本文主要是介绍【Python深度学习系列】网格搜索选择神经网络超参数:隐含层神经元数量(案例+源码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这是我的第259篇原创文章。
一、引言
在深度学习中,超参数是指在训练模型时需要手动设置的参数,它们通常不能通过训练数据自动学习得到。超参数的选择对于模型的性能至关重要,因此在进行深度学习实验时,超参数调优通常是一个重要的步骤。常见的超参数包括:
-
model.add()
-
neurons(隐含层神经元数量)
-
init_mode(初始权值)
-
activation(激活函数)
-
dropout(丢弃率)
-
-
model.compile()
-
loss(损失函数)
-
optimizer(优化器)
-
learning rate(学习率)
-
momentum(动量)
-
weight decay(权重衰减系数)
-
-
-
model.fit()
-
batch size(批量大小)
-
epochs(迭代次数)
-
一般来说,可以通过手动调优、网格搜索(Grid Search)、随机搜索(Random Search)、自动调参算法方式进行超参数调优,本文采用网格搜索选择神经网络隐含层神经元数量。
二、实现过程
2.1 准备数据
dataset:
dataset = pd.read_csv("data.csv", header=None)
dataset = pd.DataFrame(dataset)
print(dataset)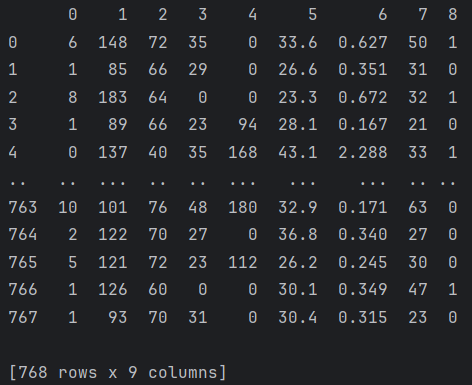
2.2 数据划分
# 切分数据为输入 X 和输出 Y
X = dataset.iloc[:,0:8]
Y = dataset.iloc[:,8]
# 为了复现,设置随机种子
seed = 7
np.random.seed(seed)
random.set_seed(seed)2.3 创建模型
需要定义个网格的架构函数create_model,create_model里面的参数要在KerasClassifier这个对象里面存在而且参数名要一致。
def create_model(neurons_1):# 创建模型model = Sequential()model.add(Dense(neurons_1, input_shape=(8, ), kernel_initializer='uniform', activation='relu'))model.add(Dropout(0.2))model.add(Dense(1, kernel_initializer='uniform', activation='sigmoid'))# 编译模型model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])return modelmodel = KerasClassifier(model=create_model, epochs=100, batch_size=80, verbose=0, neurons_1=1)这里使用了scikeras库的KerasClassifier类来定义一个分类器,这里由于KerasClassifier没有定义隐含神经元的参数,需要自定义一个表示隐含层神经元的参数neurons_1,并赋默认值为1。
2.4 定义网格搜索参数
param_grid = {'neurons_1': [1, 5, 10, 15, 20, 25, 30]}param_grid是一个字典,key是超参数名称,这里的名称必须要在KerasClassifier这个对象里面存在而且参数名要一致。
2.5 进行参数搜索
from sklearn.model_selection import GridSearchCV
grid = GridSearchCV(estimator=model, param_grid=param_grid)
grid_result = grid.fit(X, Y)使用sklearn里面的GridSearchCV类进行参数搜索,传入模型和网格参数。
2.6 总结搜索结果
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):print("%f (%f) with: %r" % (mean, stdev, param))结果:
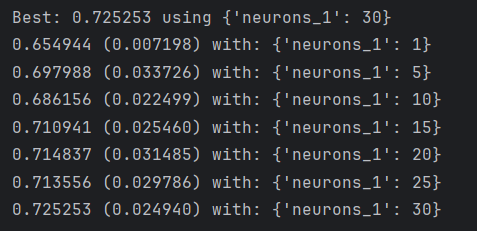
经过网格搜索,隐含层神经元数量,最优的结果是30。
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。
这篇关于【Python深度学习系列】网格搜索选择神经网络超参数:隐含层神经元数量(案例+源码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




