本文主要是介绍白话transformer(六)编码器与解码器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
B 站视频:https://www.bilibili.com/video/BV1fE421T7tR/?vd_source=9e18a9285284a1fa191d507ae548fa01
白话transformer(六)
1、前言
今天我们将探讨Transformer模型中的两个核心组件:编码器和解码器。我们将通过一个具体的任务——将中文算术表达式翻译成英文——来深入理解这两个组件的工作原理。
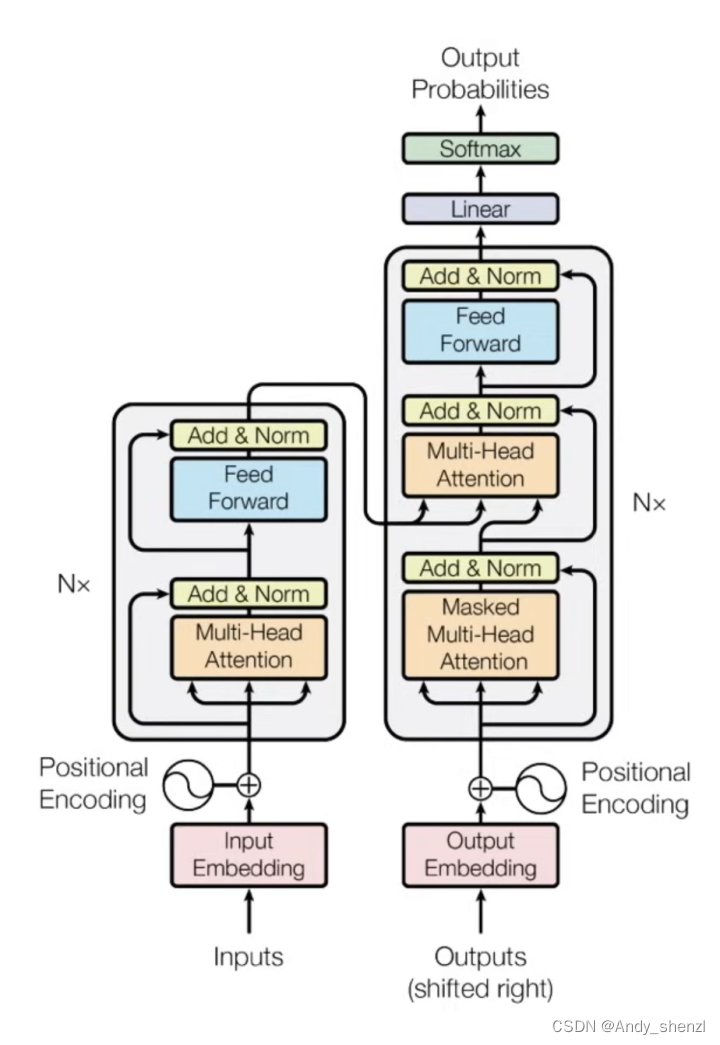
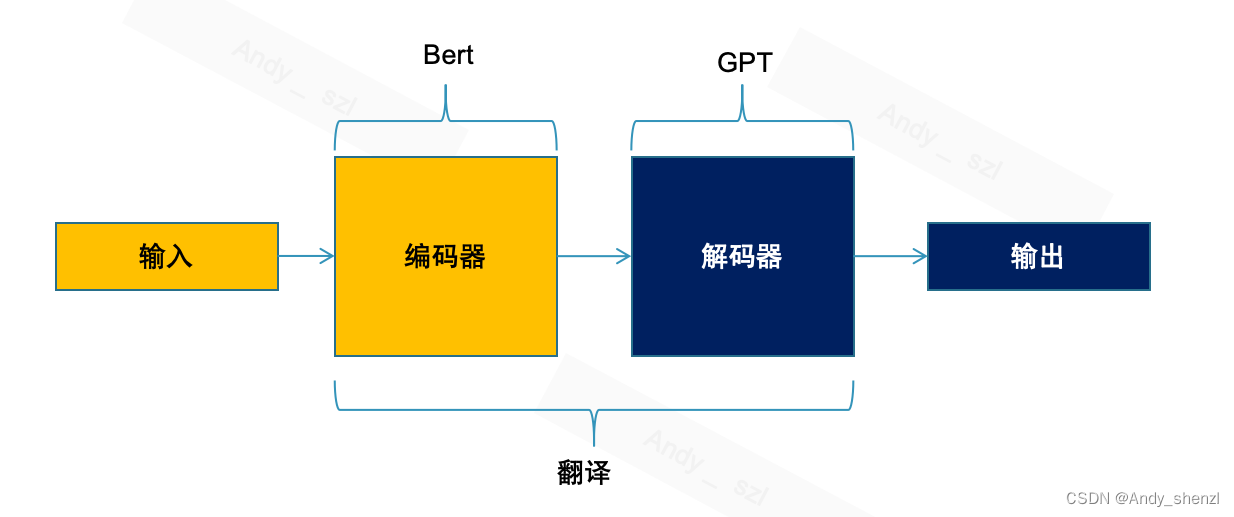
transform的原始论文中,整体的架构是有编码器和解码器组成的,但是根据任务不同,有的只需要编码器,比如Bert;有的只需要使用解码器,比如GPT系列模型;还有的是需要编码器和解码器都使用的,比如机器翻译任务
2、概念理解
下面让我们看一下解码器和编码器的原理及作用。
2.1 编码器(Encoder)
编码器的作用是对输入序列进行编码,捕捉序列中的信息并转化为固定长度的向量表示。
- 类比:你的听力理解能力。
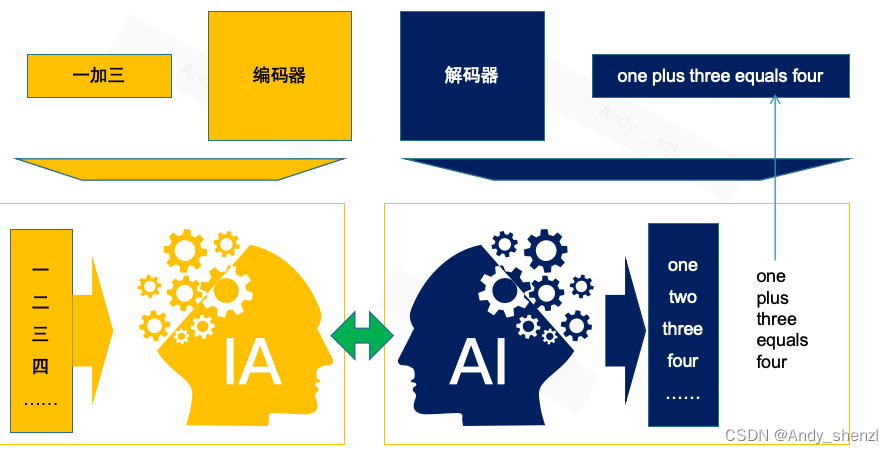
- 功能:它的任务是理解并编码输入的信息。在我们的任务中,输入是一个中文算术表达式,比如“一加三”。编码器首先将每个中文字符(一、加、三)转换成嵌入向量。这些向量不仅表示字符本身,还捕捉字符之间的关系。例如,编码器能够理解“加”是加法运算的符号,而“一”和“三”是参与运算的数字。
- 过程:编码器通过多层自注意力机制和前馈神经网络处理这些嵌入向量。自注意力机制允许编码器在处理每个字符时,考虑到其他所有字符的信息。这样,编码器能够全面理解输入表达式的结构和意义。
2.2 解码器(Decoder)
解码器的作用是对编码器的输出进行解码,生成目标序列。
- 类比:你的语言表达和回应能力。
- 功能:解码器负责基于编码器提供的信息生成输出。解码器的角色类似于一位作家,它根据编码器提供的信息生成输出。在我们的任务中,解码器的目标是生成英文的算术表达式,比如“one plus three equals four”。
- 过程:它接收编码器产生的内部表示,解码器逐个字符地生成输出。它首先预测“one”,然后是“plus”,接着是“three”,最后是“equals”和“four”。在生成每个字符时,解码器使用编码器-解码器注意力机制来关注编码器输出的相关信息。这意味着解码器在生成每个字符时,都会参考编码器输出的关于输入表达式的全面理解。
2.3 编码器与解码器的交互
在Transformer模型中,编码器和解码器通过注意力机制进行交互。解码器中的第二个子层(多头注意力机制)的输出会与编码器的输出进行交互,这样在生成每个目标序列的元素时,都能够考虑到整个输入序列的信息。
在这个过程中,编码器和解码器是协同工作的。编码器提供对输入表达式的全面理解,而解码器则根据这种理解生成准确的输出。通过这种方式,模型能够将中文算术表达式翻译成英文。
通过这种方式,Transformer模型能够有效地处理长距离依赖问题,并且在训练和推理过程中都能实现并行计算,大大提高了计算效率。这也是它在自然语言处理领域得以广泛应用的重要原因之一。
3、几个问题
3.1 解码器的输入是编码器的全部内容还是部分内容?
解码器的输入是编码器的全部内容,但这里有一些关键点需要注意:
- 全部内容的表示:编码器的输出是一个序列,其中每个元素都是对输入序列中相应元素的编码表示。这些编码表示捕捉了输入序列中每个元素的意义和它们之间的关系。解码器在生成输出序列时,会参考这些编码表示的完整集合。
- 注意力机制的作用:解码器使用一种特殊的注意力机制,称为编码器-解码器注意力,来关注编码器输出的这些编码表示。这种注意力机制允许解码器在生成每个输出元素时,动态地决定关注编码器输出的哪些部分。也就是说,解码器不是机械地使用全部内容,而是智能地选择最相关的部分来指导当前的输出。
- 序列生成过程:在生成输出序列的过程中,解码器是逐个元素地预测的。在预测每个元素时,解码器会利用到目前为止已经生成的元素(称为自注意力机制)以及编码器的全部输出(通过编码器-解码器注意力机制)。这种机制确保了解码器在生成每个元素时都有完整的上下文信息。
总结来说,解码器的输入确实是编码器的全部内容,但解码器通过其注意力机制智能地选择和使用这些内容,以生成准确的输出序列。
3.2 编码器和解码器使用的是一套embedding还是两套
比如中文一个embedding和英文的embedding
在Transformer模型中,编码器和解码器通常使用的是两套不同的嵌入(embedding):
- 编码器嵌入(Encoder Embedding):编码器接收并处理源语言(例如英文)的输入序列。它使用一套嵌入层将输入的单词或字符转换成固定大小的向量表示。这些嵌入向量捕获了词汇的语义和句子的结构信息。例如,在处理英文句子时,编码器会将每个英文单词转换为其对应的嵌入向量。
- 解码器嵌入(Decoder Embedding):解码器负责生成目标语言(例如中文)的输出序列。它也使用一套独立的嵌入层,将目标语言的单词或字符转换为嵌入向量。这些嵌入向量同样捕获了词汇的语义信息。当生成中文翻译时,解码器会将每个中文单词转换为其对应的嵌入向量。
这两套嵌入层是独立的,因为不同语言之间的词汇和语法结构可能差异很大。每个嵌入层都是针对其对应语言训练的,以便更好地捕捉该语言的特性。
此外,在翻译任务中,编码器和解码器嵌入层的维度通常是相同的,这有助于在编码器和解码器之间传输信息,特别是在编码器-解码器注意力机制中。这种设计允许模型在编码器和解码器之间有效地交换和匹配信息,从而提高翻译的准确性和效率。
3.3 会有使用一套embedding的模型吗
确实存在使用一套嵌入(embedding)的模型,尤其是在处理某些特定类型的任务时。这种设计的选择取决于任务的性质和模型的设计目标。以下是一些使用一套嵌入的模型的例子:
- 多语言模型:在处理多种语言时,一些模型会使用一套共享的嵌入层。例如,多语言BERT(mBERT)就是一个例子,它使用一套嵌入来处理超过100种语言。这种设计允许模型在多种语言之间共享词汇和语义信息,尤其是在这些语言之间存在某种程度上的词汇或语义重叠时。
- 跨语言模型:在跨语言模型中,特别是在机器翻译中,有时会使用一套共享的嵌入空间,以便源语言和目标语言可以在一个共同的语义空间中表示。这有助于模型更好地理解不同语言之间的对应关系。
- 语言建模和文本分类任务:在处理单一语言的语言建模或文本分类任务时,通常只需要一套嵌入层,因为所有数据都来自同一种语言。
使用一套嵌入的主要优点是它可以减少模型的大小和复杂性,因为不需要为每种语言或每种任务训练单独的嵌入层。此外,它还可以促进不同语言或任务之间的知识共享。
然而,对于某些任务,特别是在源语言和目标语言差异很大时,使用两套独立的嵌入可能更为有效,因为这样可以更好地捕捉每种语言的独特特征。
3.4 使用两套embedding时,两套embedding如何建立联系呢
在使用两套嵌入(embedding)的Transformer模型中,尤其是在机器翻译等跨语言任务中,确实需要一种机制来建立和维持这两套嵌入之间的联系。这种联系通常通过以下几种方式建立:
- 编码器-解码器注意力机制:在Transformer模型中,解码器通过编码器-解码器注意力机制来关注编码器的输出。这种机制允许解码器在生成每个输出元素时,根据需要从编码器的输出中选择相关信息。尽管编码器和解码器使用不同的嵌入,但这种注意力机制在某种程度上建立了两者之间的联系,因为它允许解码器根据编码器的输出做出决策。
- 共享权重或参数:在某些模型设计中,尤其是在多语言模型中,编码器和解码器的嵌入层可能会共享某些权重或参数。这种方法可以促进不同语言嵌入之间的直接联系,因为它们部分共享相同的表示空间。
- 映射函数:在一些模型中,可以设计特定的映射函数来将一种语言的嵌入空间映射到另一种语言的嵌入空间。这种映射可以是线性的或非线性的,其目的是在两种语言的嵌入之间建立直接的对应关系。
- 联合训练和对抗训练:在训练过程中,可以通过联合训练或对抗训练策略来鼓励模型学习到两种语言之间的对应关系。例如,在对抗训练中,可以训练一个判别器来区分两种语言的嵌入,同时训练主模型来欺骗这个判别器,从而促进两种语言嵌入之间的对齐。
这些方法可以在不同程度上帮助模型在两种语言的嵌入之间建立联系,从而提高跨语言任务(如机器翻译)的性能。然而,具体选择哪种方法取决于任务的性质、数据的可用性以及模型设计的目标。
这篇关于白话transformer(六)编码器与解码器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!