白话专题
白话数据结构之【最小生成树】
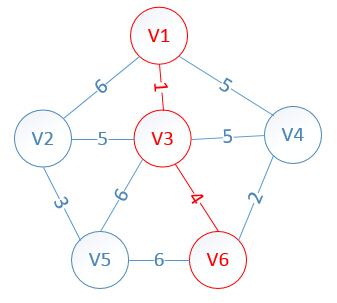
一:基本概念 1:什么是生成树? 对于图G<V,E>,如果其子图G'<V',E'>满足V'=V,且G'是一棵树,那么G'就是图G的一颗生成树。生成树是一棵树,按照树的定义,每个顶点都能访问到任何一个其它顶点。(离散数学中的概念),其中V是顶点,E是边,通俗来讲生成树必须包含原图中的所有节点且是连通的 比如 2:最小生成树 一个无向连通图G=(V,E),最小生成树就是联结所

欢迎大家关注我的【白话算法和数据结构】专栏
学习ACM也有一年半了,曾经对什么算法都不懂,现在对很多算法都有一定的了解,我们acm集训队都是学长学姐带学弟学妹,其实我们将的学弟学妹大部分都不能理解,当初我听杨大神讲课也是一样,听和没听一样,但是有学长告诉你有这个算法也是好的,只是你知道哦,原来这道题要用这道算法,我以前傻逼的暴力解决~~~然后他告诉你有这个算法,你自己去学,去网上搜资料学,所有人都是这么走过来的,但是网上能把算法将的跟白话一

白话RNN系列(七)
本文,探讨下LSTM的一些高级应用,比如双向LSTM。 前面的探讨过程中, 我们使用到的RNN或者LSTM都是单向的,即按照时间顺序排列的一维序列;而在实际应用中,双向的RNN由于考虑到更充足的上下文,往往能起到更好的效果: Bi-RNN又叫双向RNN,是采用了两个方向的RNN网络。 RNN网络擅长的是对于连续数据的处理,既然是连续的数据规律,我们不仅可以学习它的正向规律,还可以学习它的反向规
白话RNN系列(六)
上文给出了一个LSTM使用的具体例子,但其中依旧存在一些东西说的不是很清楚明白,接下来,我们会针对LSTM使用中更加细致的一些东西,做一些介绍。 本人目前使用的基本都是TensorFlow进行开发。 lstm_cell = tf.nn.rnn_cell.LSTMCell(n_hidden, forget_bias=1.0, name='basic_lstm_cell')outputs, st

白话RNN系列(五)
前文,对于LSTM的结构进行了系统的介绍,本文,通过一个MNIST_data的例子,争取能够把LSTM的基本使用来吃透。 import tensorflow as tfimport input_data# 导入 MINST 数据集# from tensorflow.examples.tutorials.mnist import input_data# one_hot=True,代表输入的

白话RNN系列(四)
本文,谈谈RNN的一个变种,也是目前使用比较广泛的神经网络LSTM,我们首先描述下LSTM的基本结构,然后给出一个具体的使用LSTM的例子,帮助大家尽快掌握LSTM的原理和基本使用方法; 这可能是一张大家熟悉地不能再熟悉的图片了。 我们可以将其与RNN的基本结构进行对比: 我们可以看到区别:RNN中,每个循环体会产生一份输出,即隐藏状态;最终输出由此隐藏状态产出,同时,隐藏状态会保

白话RNN系列(三)
紧接上文,白话RNN系列(二)。 通过generateData得到我们的样本数据之后,我们开始搭建自己的RNN: # 每个批次输入的数据,这里定义为5,即每个批次输入5个数据batch_size = 5# RNN中循环的次数,即时间序列的长度# 这里取长度为15的时间序列truncated_backprop_length = 15# 与时间序列相对应,占位符的维度为 5 * 15#

白话RNN系列(二)
紧接白话谈RNN系列(一) 上文讨论了基础的全连接神经网络,本文,我们来说说RNN。 首先,RNN相比于普通的神经网络,有什么改进? 两点比较突出:权值共享和隐层神经元节点的有序连接。 直接上图,浅显易懂: 上图,摘自深度学习(花书),左侧图和右侧图表达了相同的含义,我们以右侧图为例,并配合实例,对RNN进行透彻的分析,我尽可能以很通俗移动的方式把RNN讲明白。 从本图中,我们很清

白话RNN系列(一)
RNN,循环神经网络,全称Recurrent Neural Network。 本文,从RNN的基本原理讲起,会探讨RNN的前向传播和反向传播,并通过一些浅显易懂的小例子,展示RNN这个东东的神奇之处,尽最大可能以通俗易懂的方式,让看到本文的童鞋都能够掌握RNN。 1:RNN的基本原理 即便是RNN,也依旧脱离不了神经网络的基本架构,换句话说,我们看RNN的时候,一定要记住一句,它不过是高级一

J.U.C Review - 白话Java内存模型
文章目录 并发编程要解决的问题运行时内存的划分内存可见性问题及其解决方法JMM的抽象示意图 Java内存模型与JVM内存区域划分的关系重排序与happens-before什么是重排序?重排序的类型顺序一致性模型与JMM的保证顺序一致性模型Java内存模型(JMM)的保证 happens-before原则什么是happens-before天然的happens-before关系实例分析小结
优雅谈大模型:白话ZeRO 下
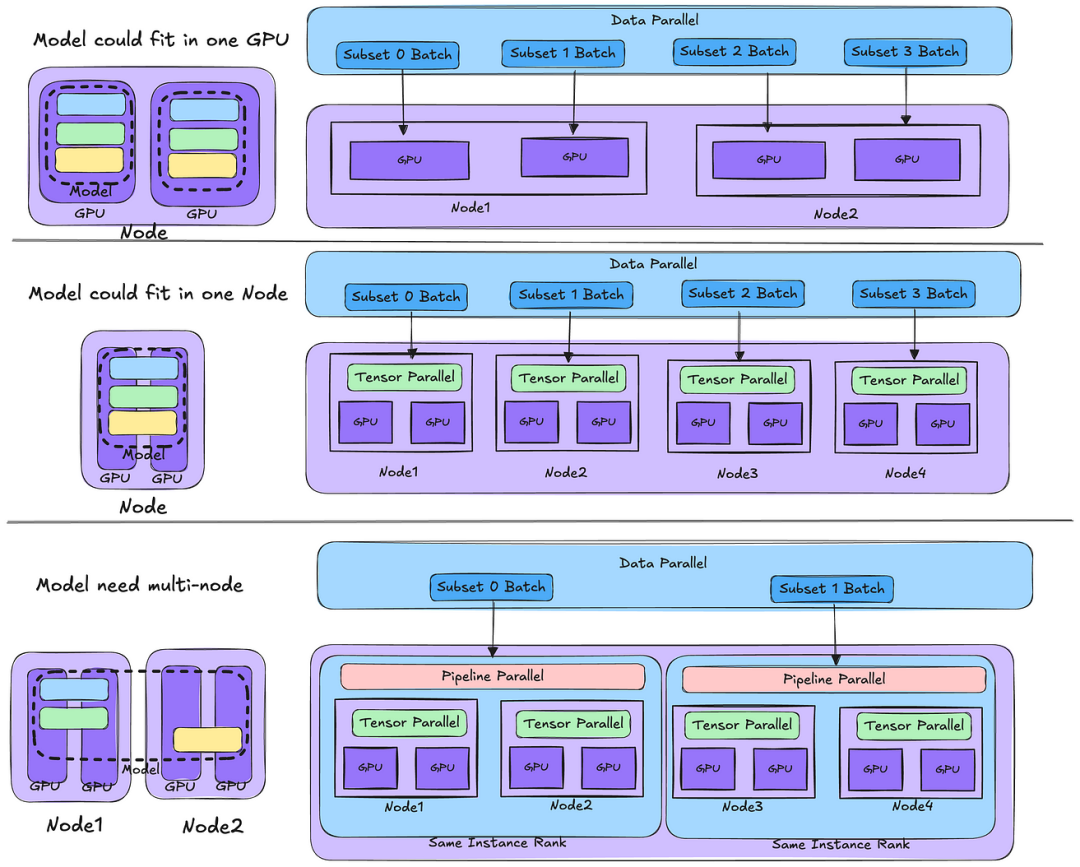
机器学习模型的复杂性和规模不断增长,分布式训练变得比以往任何时候都更加重要。训练具有数千亿参数的大型语言模型( LLMs )将是机器学习基础设施面临的挑战。与传统的分布式计算框架不同的地方在于GPU的分布式训练需要将数据传递给GPU芯片等物理硬件层。GPU设备之间会进行频繁、大规模的数据交换以进行高效训练,今天将揭开分布式训练的神秘面纱。 上图为基本的机器学习训练框架,数据准备占据1/3
白话解析:一致性hash算法 consistent hashing
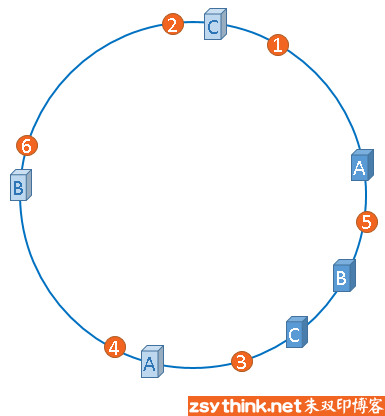
以下内容转载自: 朱双印博客| 白话解析:一致性哈希算法 consistent hashing 原文地址:http://www.zsythink.net/archives/1182 在了解一致性哈希算法之前,最好先了解一下缓存中的一个应用场景,了解了这个应用场景之后,再来理解一致性哈希算法,就容易多了,也更能体现出一致性哈希算法的优点,那么,我们先来描述一下这个经典的分布式缓存的


(史上最白话最简单)深度剖析Java的split();方法(附:怎么能看懂JDK源码?)
前言: 随着Java学习的深入,我们不仅仅会要求自己熟练使用一些API的方法,更想看看这些方法的底层是如何实现的,然而你如果想进步那么必须要训练看源码的能力,将来学高级框架的时候是一定会看底层源码的,所以必须要从相对基础的JDK源码训练开始! ヾ(◍°∇°◍)ノ゙ 目录 前言: 什么是split方法?(理解的可以跳过) 第一个:split(String regex) 翻译

胖虎白话学习设计模式之专业术语存在的误解
胖虎白话学习设计模式之专业术语存在的误解 记录胖虎学习设计模式过程,不许勿喷,转载请注明出处! http://blog.csdn.net/ljphhj 1.存在问题 胖虎想要把学习设计模式的过程记录下来,但是发现一直以来有些专业术语的概念没有弄清楚,这样是很不利于设计模式知识的学习的,所有特写一篇博文来记录一些常见的被误解的术语 我们必须弄清楚:算法,多态性,方法
白话:服务降级与熔断的区别
虽然之前在《Spring Cloud构建微服务架构》系列文章中介绍了Hystrix服务降级与Hystrix断路器的概念。但是,还是一直收到这样的提问:降级与熔断区别是什么?并且在很多交流过程中,发现有不少童鞋对降级和熔断的概念有混淆的情况。所以,这篇博文准备换一种方式来说说这两个概念,以帮助读者更好的理解之前两篇文章中介绍的这两个重要知识。 下面通过一个日常的故事来说明一下什么是服务降级,什么是
白话机器学习4:小波分解的原理与Python代码实现
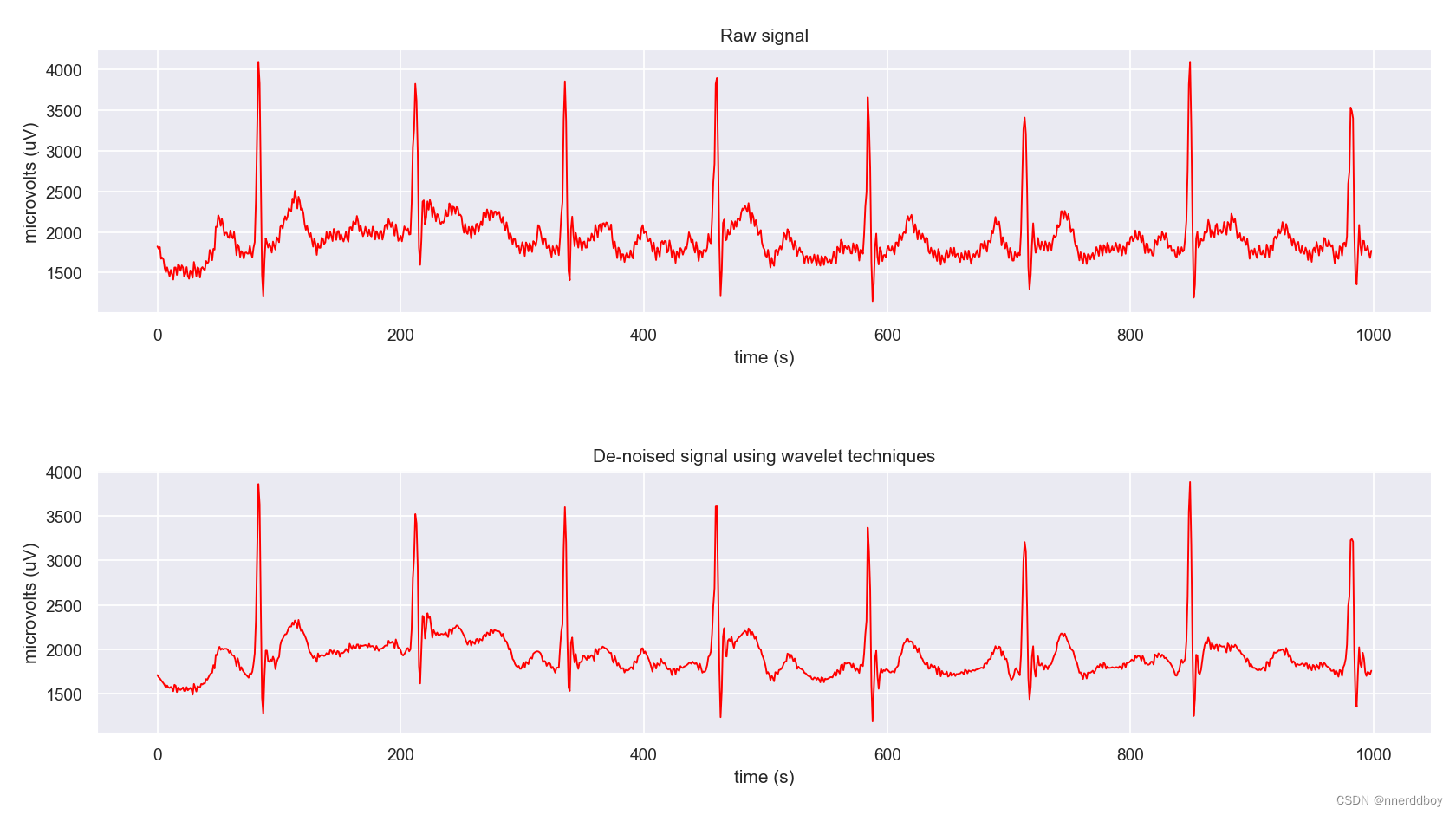
小波去噪可以想象成使用一把“筛子”来过滤信号。这个“筛子”能够根据信号的不同频率成分,将其分解成多个层次。在这个过程中,信号的重要信息通常包含在低频部分,而噪声则多分布在高频部分。 将信号通过这个“筛子”分解后,我们可以对那些包含噪声的高频部分进行“削弱”或“切除”,然后再将剩下的部分重新组合起来。这样,经过处理的信号就会保留下重要的信息,同时去除了很多噪声。
白话tensorflow分布式部署和开发
白话tensorflow分布式部署和开发 关于tensorflow的分布式训练和部署, 官方有个英文的文档介绍,但是写的比较简单, 给的例子也比较简单,刚接触分布式深度学习的可能不太容易理解。在网上看到一些资料,总感觉说的不够通俗易懂,不如自己写一个通俗易懂给大家分享一下。 1. 单机多GPU训练 先简单介绍下单机的多GPU训练,然后再介绍分布式的多机多GPU训练。: 单机的多GP

【白话机器学习系列】白话特征向量
白话特征向量 一个方阵 A A A 与列向量 v v v 的乘积会生成一个新的列向量。这个新向量通常与原向量有着不同的方向,矩阵在这里代表一个线性变换。然而,某些向量会保持其原始方向。我们称这种向量为矩阵 A A A 的特征向量(eigenvector)。 在本文中,我们将探讨特征向量、特征值和矩阵的特征方程。并且以 2 维方阵为例,教大家如何计算矩阵的特征向量和特征值。
白话NLP技术的演进发展
自然语言处理是人工智能的一个重要分支,旨在让计算机能够理解、生成和处理人类语言。我们每天都在使用自然语言,比如与人对话、阅读文章、撰写邮件等。NLP的目标就是要让机器也能像人一样处理语言,从而实现人机交互、信息检索、机器翻译、情感分析等多种应用。 要让机器理解自然语言,首先需要将语言数字化。最常见的方法是one-hot encoding,即为词表中的每个词设置一个等长的向量,该词对应位置为1,其
白话机器学习1:分类问题中的评价指标
机器学习中的评价指标非常多,它们用来衡量模型的性能和预测能力。不同类型的机器学习任务可能需要不同的评价指标。以下是一些常见的评价指标,按照不同类型的机器学习任务分类: 对于分类问题: 准确率(Accuracy)精确率(Precision)召回率(Recall)或灵敏度(Sensitivity)F1分数(F1 Score):精确率和召回率的调和平均受试者工作特征曲线(ROC Cu
白话浅谈MPEG2-TS之demux
TS都是一个TS包组成,每个包都是固定188个字节,每个包都是4个字节包头开始,包头第一个字节是固定的0x47。那其他184个字节是什么呀,里面基本都装的是音频或者视频解码数据。如果给定一个TS文件,怎么去寻找解码音视频解码数据呢? 每个TS包的前4个字节的包头里都有一个PID,首先,一个个遍历TS包,我们找到PID为0的TS包,这个包叫PAT,这个PAT包里包含
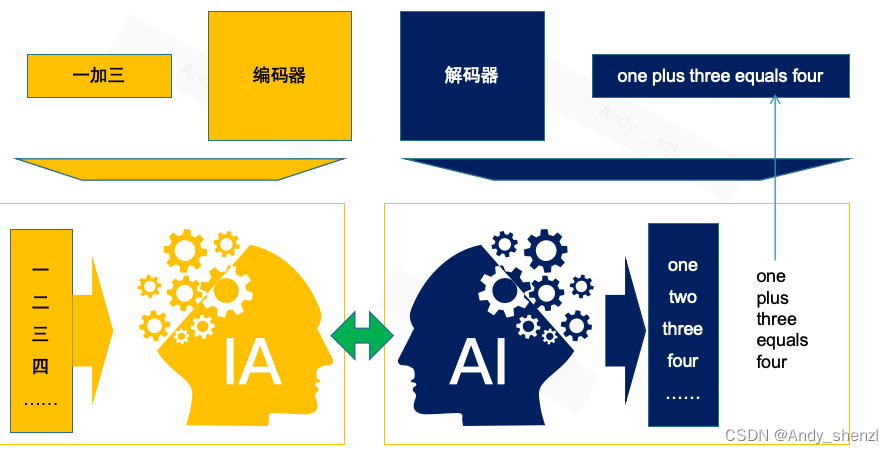
白话transformer(六)编码器与解码器
B 站视频:https://www.bilibili.com/video/BV1fE421T7tR/?vd_source=9e18a9285284a1fa191d507ae548fa01 白话transformer(六) 1、前言 今天我们将探讨Transformer模型中的两个核心组件:编码器和解码器。我们将通过一个具体的任务——将中文算术表达式翻译成英文——来深入理解这两
《白话强化学习与python》笔记——第七章Gym一一不要钱的试验场
《白话强化学习与python》笔记——第七章Gym一一不要钱的试验场 Gym 是一个免费且开源的平台,用于开发和比较强化学习算法。 Gym(全称为Gymnasium)是由OpenAI开发的一个强化学习环境,它提供了一个标准化的接口来创建、管理和测试强化学习算法。以下是一些关于Gym的重要信息: 安装与使用:要开始使用Gym,首先需要在你的计算机上进行安装。如果你使用的是虚拟环境