本文主要是介绍DeepMind训练AI玩足球,风骚走位比中国男足都强(狗头),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:AI科技评论本文约4200字,建议阅读9分钟本文带你了解DeepMind训练的 AI 玩足球。
AI踢足球可以有多燃?
不好,对方攻到底线了!看我一脚精准拦截、抢球!

想抢回去?没门!
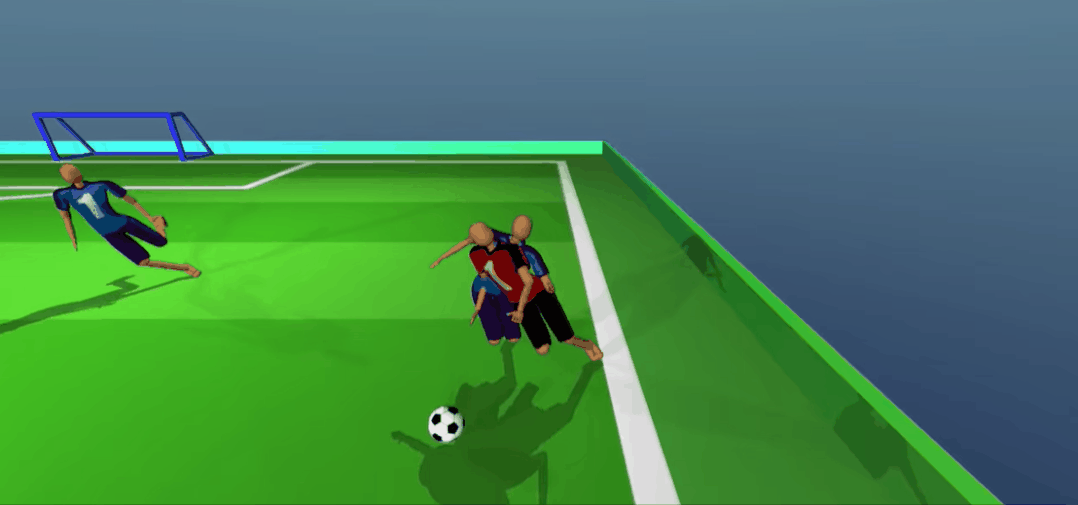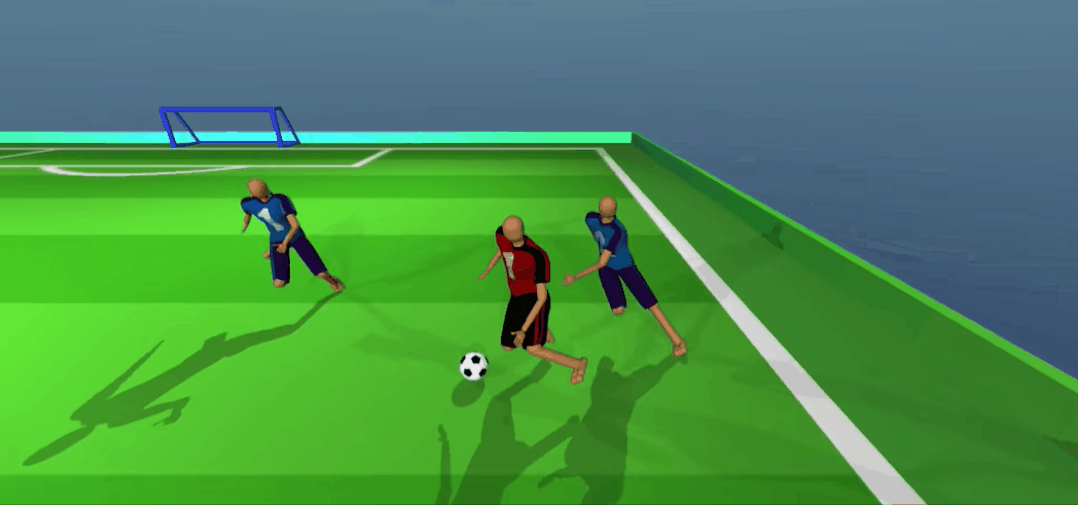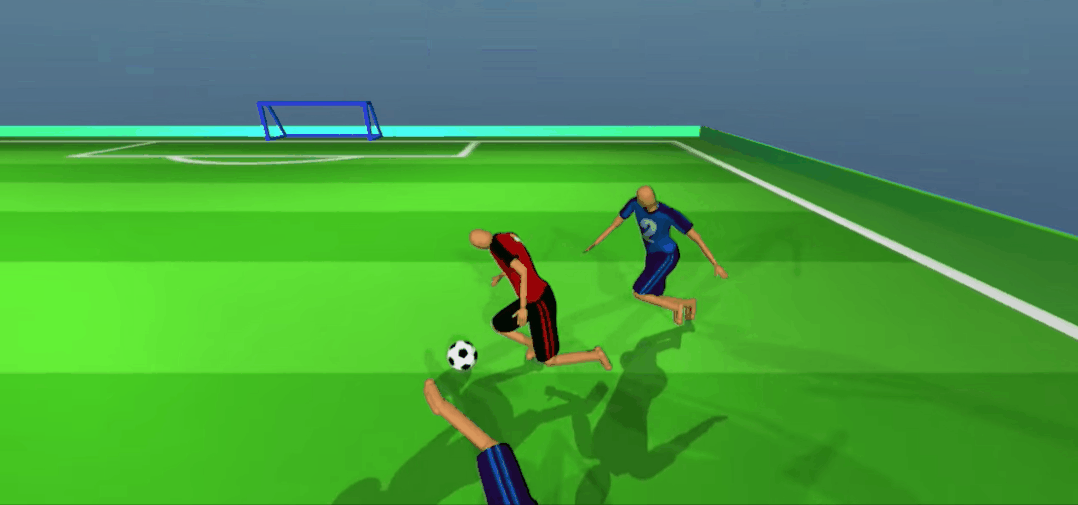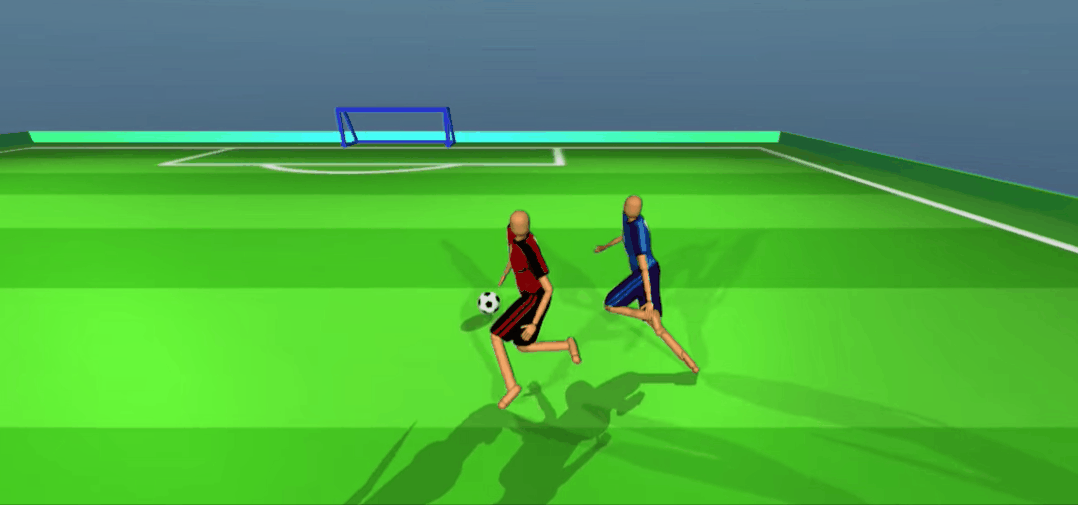
差点被进了,赶紧回传!好队友,马上来接应了。
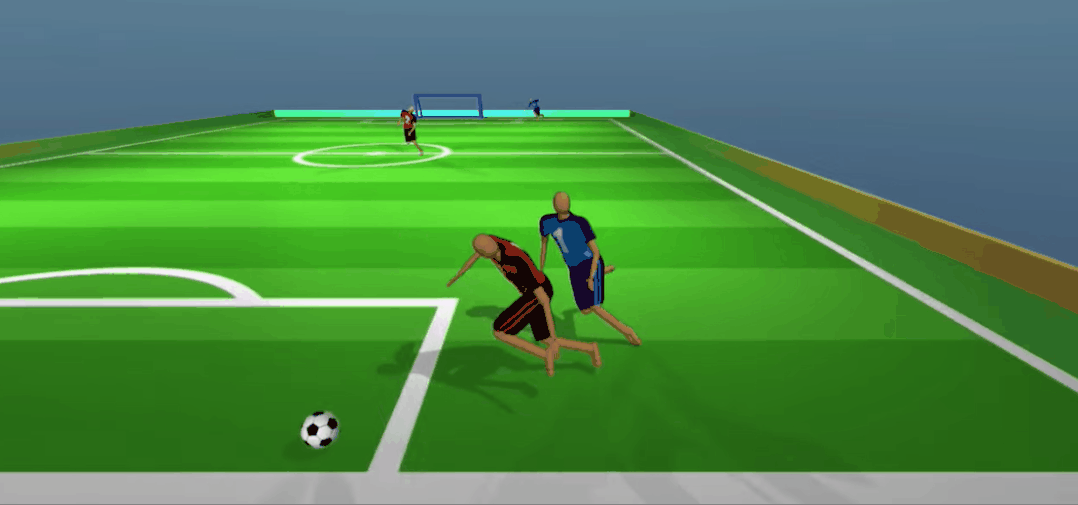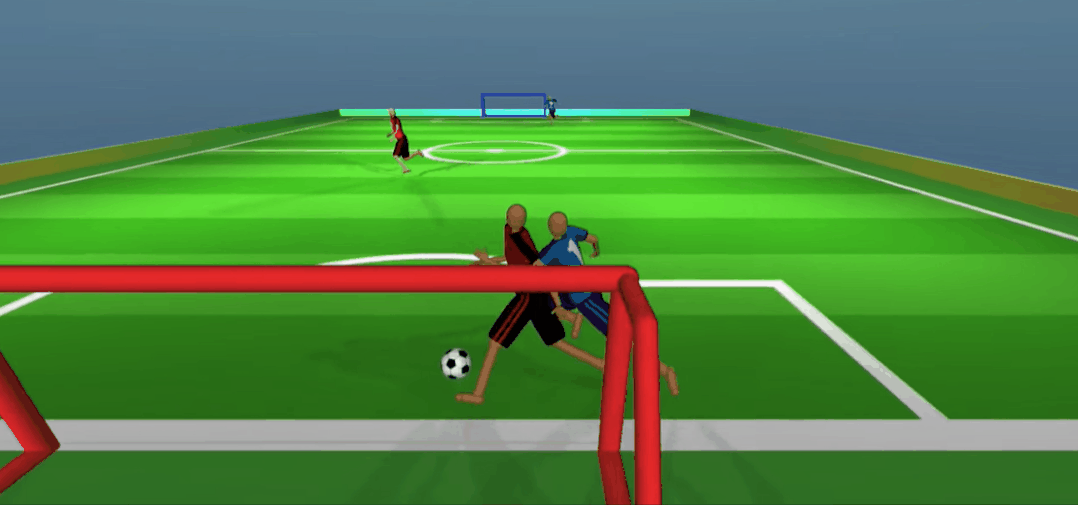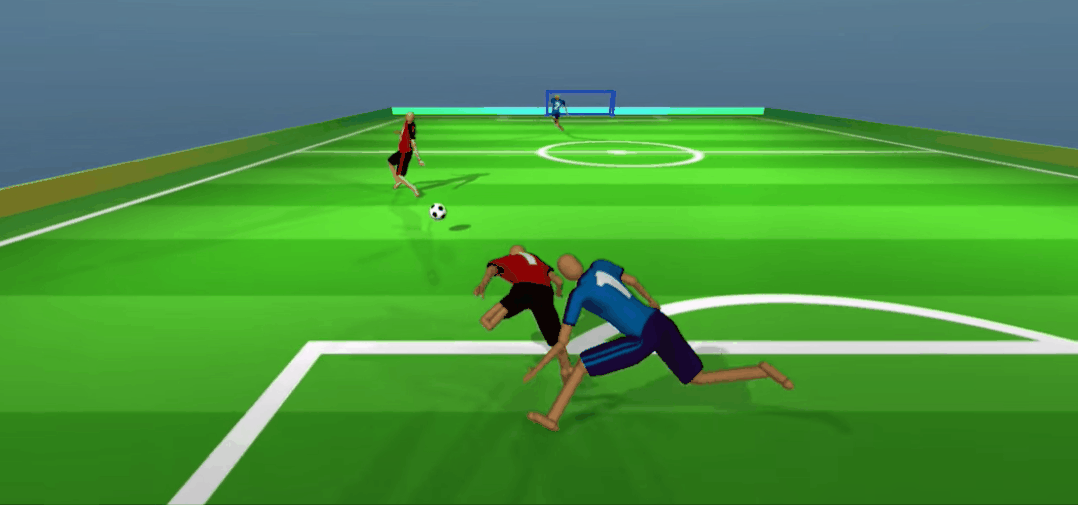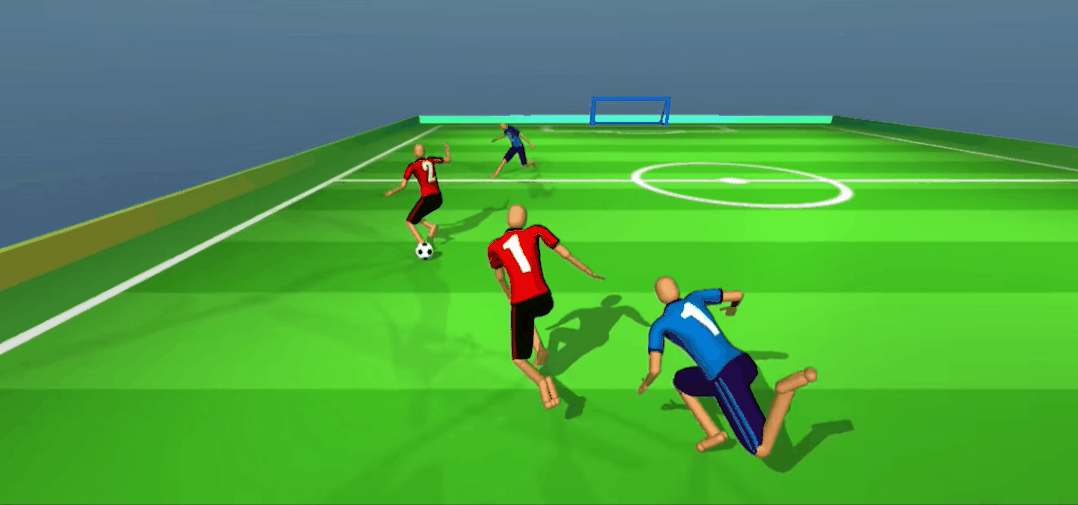
嘿嘿,被骗了吧。队友无球跑骗过了防守,我当然是赶紧传一个,反杀!

怎么样,是不是比你强?
DeepMind 在强化学习这块总是走在世界前列,上面的演示是他们训练的「双人足球」AI在比赛中的精彩瞬间。
基于AI控制的智能体球员不仅动作灵活、敏捷,还掌握了运球、过人、传球等基本技能。
更重要的是,为了赢得比赛,多个智能体之间竟学会了打配合。比如上面红色球员假接传球、真无球跑位的策略,可谓相当机智。
整个过程一气呵成,看起来和人类足球运动员几乎没有什么区别。
要知道,在还没训练的时候,他们只是一群站都站不稳,三两下就躺倒闹着要休息的熊孩子。
但他们还是天赋过人,仅仅经过了三天的训练,他们就学会了比较简单的配合技巧。
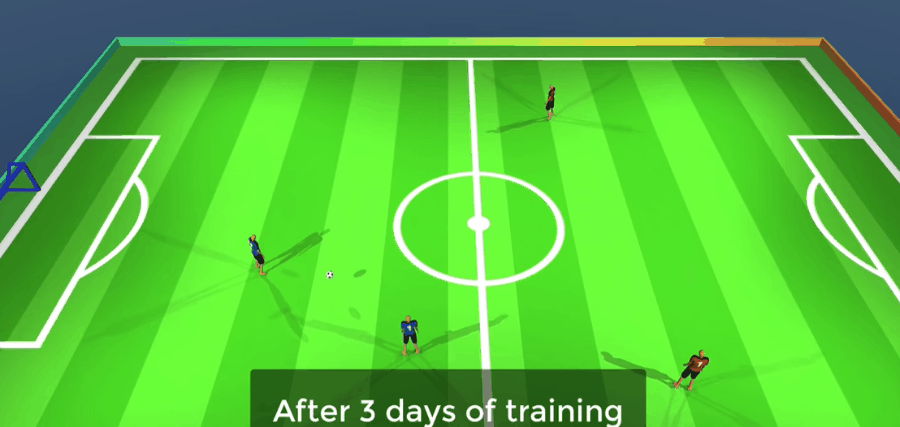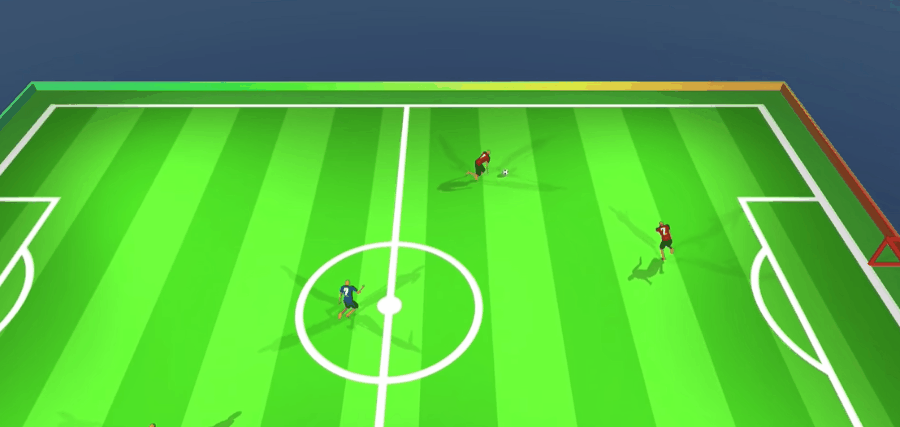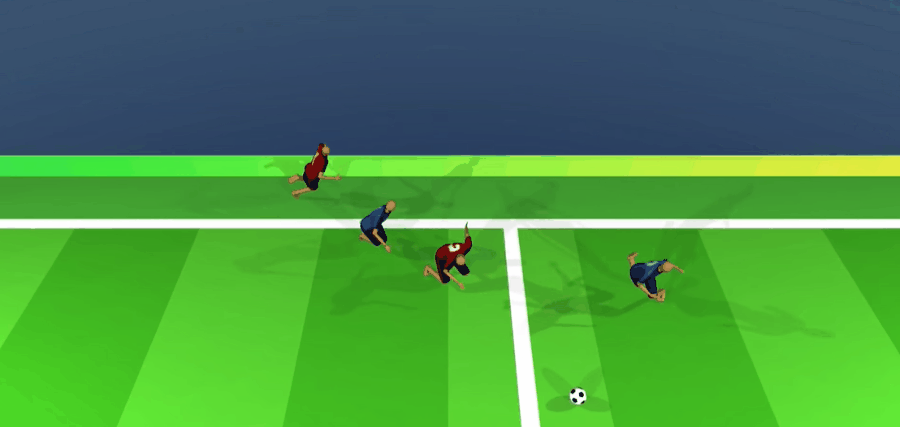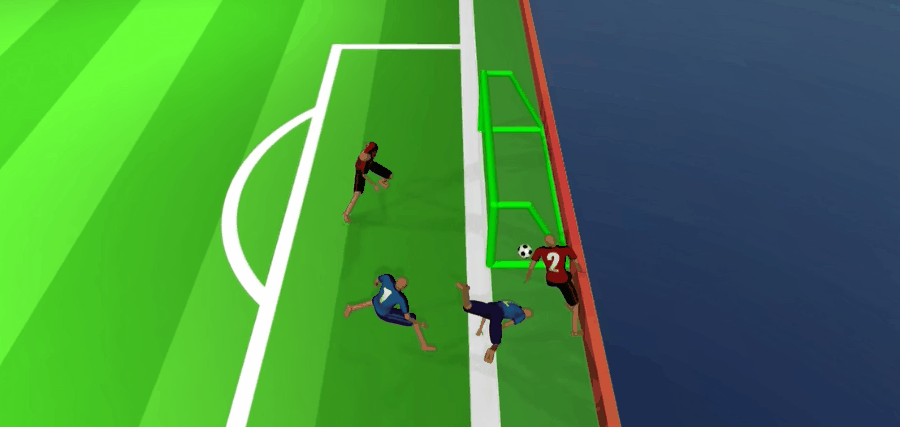
完成50天训练后,他们已经能在很精细的水平上完成抢断、接应、分头行动的配合节奏。

DeepMind一直尝试用AI来玩一些复杂多变的策略性游戏,以训练出接近人类智力水平的智能体。在足球运动中,团队协作是智能体训练面临的最大挑战,它不仅要对足球规则、技巧十分娴熟,还要对赛场上的局势,队友和对手的位置、以及目标有更好的理解,以做出更理性的决策。
DeepMind表示,此次升级的AI智能体训练出了对他人的“意识”,能够在更大的时空维度上,与队友协同配合完成更复杂的作战策略。
在发布演示视频的同时,DeepMind也分享了这篇名为“From Motor Control to Team Play in Simulated Humanoid Football”的技术论文。

论文地址:
https://arxiv.org/pdf/2105.12196.pdf
在这篇论文中,研究人员通过仿真人形模拟足球运动,提出了将模仿学习、单智能体和多智能体强化学习与群体训练相结合的方法,并在不同抽象层次上利用行为的可转移表征主导决策。
在训练阶段,这个具有全关节的人形智能体球员先是通过模仿学习学会了一些基础动作。

紧着掌握了运球、射门等中等水平的足球技能。



最后通过毫秒级的运动控制实现了多智能体团队协作,弥合了数十秒范围内行为与目标之间的差距。

以下是一个2v2多智能体在物理世界中实现多维度综合决策的演示视频:
论文概述
艾伦·纽厄尔(Allen Newell)在描述基础认知科学和人工智能的评论中指出,从毫秒级的肌肉抽搐,到几百毫秒或几秒钟的认知级决策,再到更长时间的以社会信息为导向的目标序列,人类行为可以在多个层级水平上被理解。
正如Newell所观察到的,协调抽象层次的能力是人类行为最显著的特征之一。这个能力意味着人类通过低层次的运动可形成认知水平的决策,进而完成高层次的目标或协作任务。
在Newell发表这篇文章之后,有关智能行为是如何产生的研究取得了显著性进展。学者们开始关注单一个体的抽象层次,如运动控制和目标导向行为,合作行为的起源,以及动物和人类的群体协调机制。类似地,有关机器人研究的目标也是让机器产生类似动物的敏捷、复杂的动作。
近几年,基于学习的方法成功地解决了人工智能领域的一些现有挑战,包括具有层次结构行为、长期策略以及多智能体协调问题。本文展示了模拟真实世界的具体化系统在生成复杂运动策略上的广泛前景。然而,Newell强调的多维度行为策略,以及现实世界的复杂性仍然给人工智能系统的设计者带来诸多困扰。
本文在智能仿人控制(22, 23, 31–33)研究的基础之上,通过模拟人类足球比赛开发了一个基于深度强化学习(deep RL)的研究框架,该框架解决了长视野范围内团队协作的现存问题。
在行为学研究中,团队运动在协调决策和运动控制方面存在诸多挑战。自1996年以来,机器人相关研究一直在尝试解决这些挑战,特别是在足球领域,他们的目标是在2050年击败一只人类足球队。
在足球比赛中,激烈的竞争需要双方球员在不同的时空抽象层次上做出决策——通过“低水平”的快速控制产生“中级水平”的技能,以实现“高级别”的目标,例如通过踢球和运球等具有目标导向的行为为团队赢得比分。需要强调的是,这些不同级别的决策是紧密相关的,例如,传球的成功与失败取决于对球场局势的共同理解和球员联合行动的一致性,也取决于他们精确控制自己动作的能力。
本文通过模拟现实的足球环境,尝试解决智能体在运动和团队协作方面所面临的挑战。
文中的智能体由完全关节化的物理人形构成,具有足够的灵活性,在自然地移动的同时,也能够与其他多智能体配合生成更复杂的协调策略。
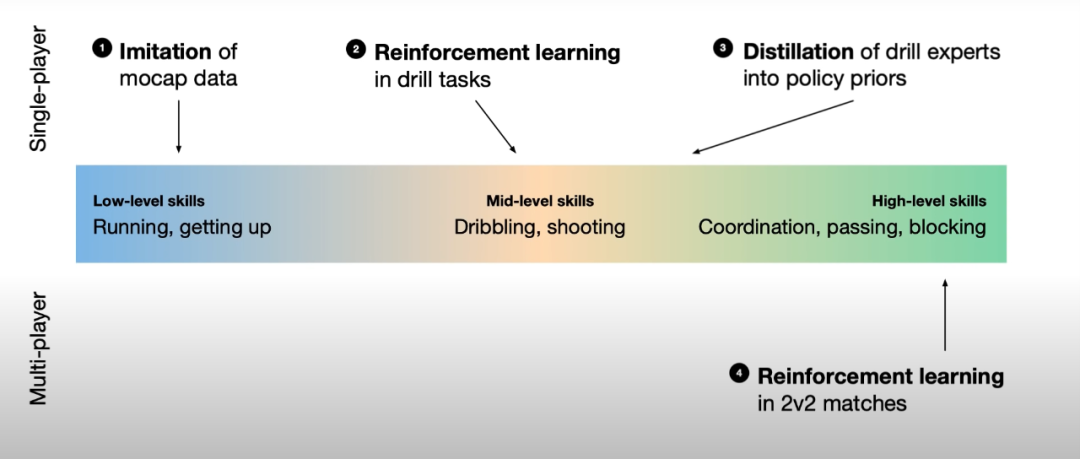
具体来说,智能体的学习框架分为三个阶段:先是通过模仿学习掌握低水平的动作技能,再是利用强化学习获得中级足球技能,最后通过多智能体强化学习完成整个足球游戏。这个过程意味着通过模仿获得的先验知识,智能体可以在自我游戏的视频中学会更复杂的技能,而这些技能是很难通过奖励或模型学习教会它的。
实验证明,基于该训练框架的智能体球员掌握了复杂运动、足球技能和团队协作的能力。在演示视频中,智能体表现出了拟人化、敏捷、健壮的动作和控球技巧,比如从地上快速起身,调整方向,或者围绕对手周旋,随时准备进攻。
从个体行为发展到相互协调的团队战术(从移动,到配合防守、定位和传球),研究人员将现有的AI技术与体育分析技术相结合,定量分析了球员运动,行为策略以及内部表现。实验表明,比赛的结果与球员的球技呈正相关,也与团队协作策略以及预测对手行为的能力呈正相关,类似于人类对足球运动员的观察,智能体球员对带球运动员,对方得分情况以及运球的意图都有着正确的理解。
需要说明的是,本文虽然仅提供了该框架在足球游戏中的演示,但它的基本原则是通用的,也就是说,该智能体框架也适用于其他需要团队协作的场景或领域。
智能体学习模式
如上文所述,智能体的学习过程分为三个阶段,第一阶段是通过模仿从人体运动数据中获得低水平运动技能,并通过关节驱动转化为逼真的仿人动作;第二阶段,在运动模块的基础上,训练智能体学习一套足球专项技能,并设定一般运动和控球技能的训练优先级;第三阶段训练智能体在完整足球赛中掌握长视野协调能力。该阶段利用低级和中级技能的表征来加速训练,避免了局部最优和常见问题。
以下为三个阶段的概述图:
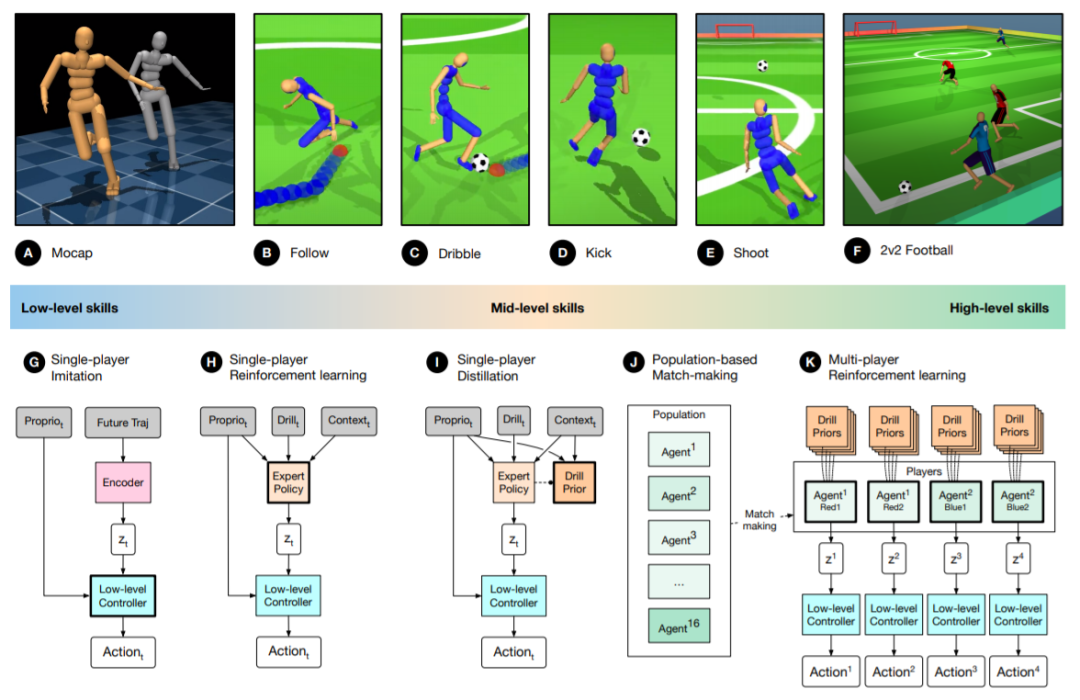
初级技能:所用数据截取自足球游戏的某一个片段,时长大约1小时45分钟,重点追踪足球运动员四肢的基础动作。在底层控制器方面(如图2G),使用包含跟踪运动捕捉片段和独立策略的二级管道。其中,每个被跟踪的行为将提炼成单个底层控制器。这种结构被称为神经概率运动原始(neural probabilistic motor primitive ,NPMP)模型。
具体来说,首先将运动捕捉数据切割成4-8个片段,通过强化学习来模拟每个片段并训练单独的时间索引“跟踪”策略。然后从每个追踪策略中抽取多条运动轨迹,并适当加入噪声以修正运动行为。接下来,使用有监督的训练方法将这些采样轨迹提炼成单一的神经网络控制器。
中级足球技能:包括跑步、转身和平衡,以及运球和踢腿技能,以下是智能体需要训练的运动大纲。这些预习的技能将用于加速整个足球任务的学习。

该阶段采用基于PBT-R的特定任务专家训练策略(如图2H),在低水平运动技能的基础上,训练一批特定任务专家将运动意图输出到固定的NPMP模块,在潜在运动意图空间中有效地执行RL,并以适应度测量(Fitness Measure)和专家选择训练目标作为表征期望行为的奖励函数。
更大视野内( Long-Horizon)的协作运动:使用双时间刻度(two-timescale)优化设置来训练足球运动员(如图2J-K)。在外环( outer-loop )驱动PBT的适应度测量,然后利用行为塑造,前两个阶段获得的中低水平技能以及额外的塑造奖励,通过多智能体强化学习对内环进行优化。
实验和结果
论文中,通过一系列实验评估了智能体在不同阶段的学习情况以及框架的性能。每个实验训练16名独立的足球运动员,并对它们的权重和超参数进行随机初始化。所有实验中使用相同的NPMP,但是为每个实验单独训练一组专家和先验知识。其训练的基础平台如下:
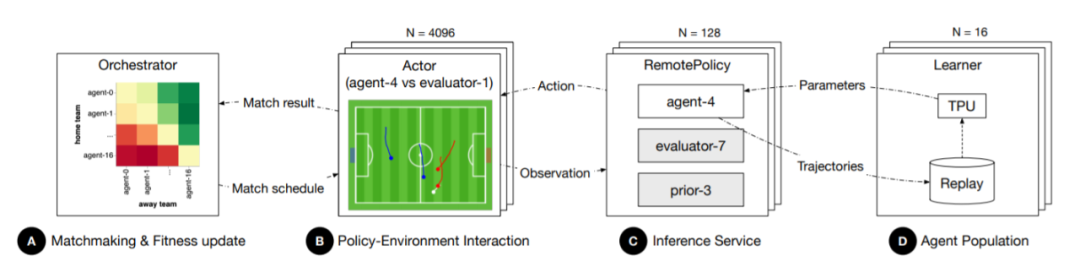
使用一台16核TPU-v2中央处理器和128个服务器来完成智能体学习和推理过程。其中每个智能体使用一个内核,每个服务器执行由唯一模型名称标识发起的推理服务。对同一推理模型的并发请求可执行自动批处理推理,其中额外的请求会产生微小的边际成本。
实验结果如下:
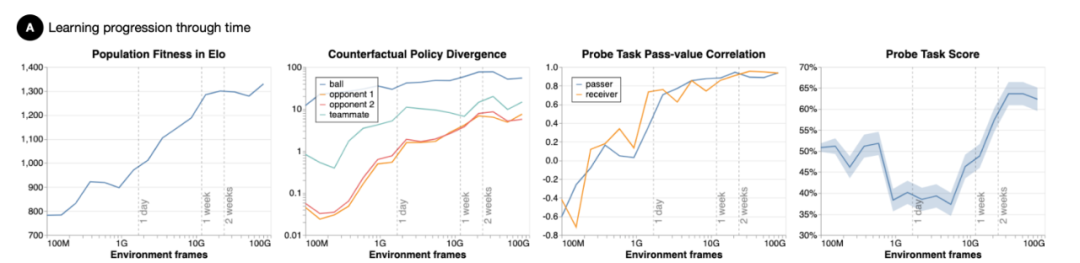
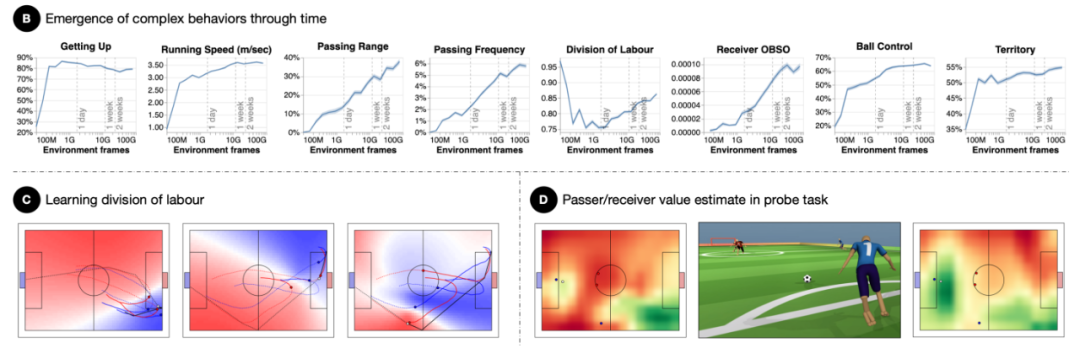
以上实验结果表明,智能体行为的发展过程大致分为两个阶段:先是获得基本的运动和控球技能,然后开始表现出团队之间的协调与合作。
在第一阶段中,经过24小时训练后,智能体球员学习游戏基础知识,运动和控球的能力迅速提高(如上图5B所示),再经过6个小时训练后,球员可以从80%的跌倒中自行恢复。此外,根据劳动分工统计数据显示,随着球员个体控球能力的提高,团队双方围着足球扎堆推挤的行为明显减少。
如上图5A,足球对智能体策略产生了显著影响。经过5个小时训练后,它所引起的反事实策略分歧大约是队友的40倍,是竞争对手的700倍。图中探测任务的分值低于50%,这意味着传球人将球踢向了与接球人相反的方向。
第二阶段团队协作开始出现。如图5B,在8 × 10^10环境步态之后数值达到了0.85以上,这意味着一名球员的控球策略与队友更为协调(队友在前方等待传球);传球的频率和范围有所增加。在8× 10^10环境步态中传球占6%,其中,40%的传球行程超过10米;整个训练过程中,OBSO也显著增加,这意味着球员们在球场中有较好的定位,即球员们在可能进球的位置调整自己的方向以获得传球。
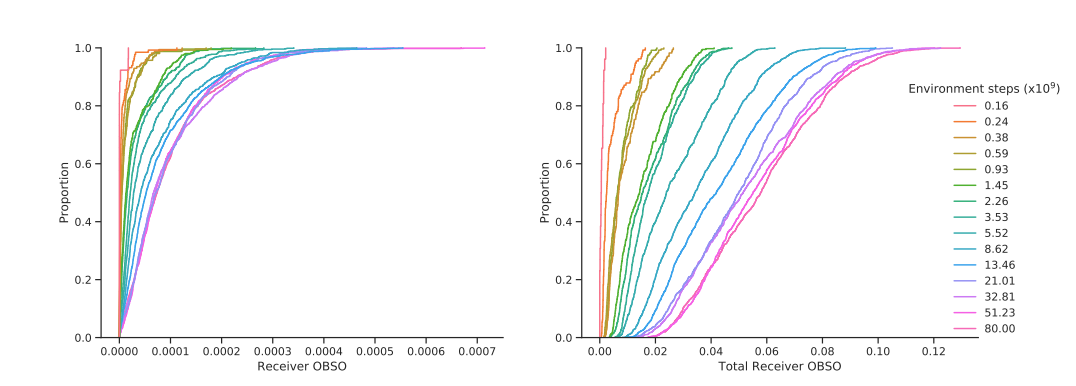
需要说明的是,训练过程中奖励机制并不能激励OBSO的增加,它意味着智能体的协调行为主要来自想要赢得足球赛的竞争压力。
与上述一致,队友和竞争对手在智能体策略中引发的CPD(counterfactual policy divergence )显著增加,这意味智能体策略对其他球员的位置更加敏感:在8× 10^10环境步态后引起的CPD小于队友的5倍,大于任何一个竞争对手的10倍,这大大增加了其他智能体的相对影响力。
在探测任务中,传球值的相关性同样显著增加:在8× 10^10环境步态后达到了0.2和0.4之间。这表明传球者和接球者在传球过程中对周围的情况都有了更清楚的了解,并且对带球队友给与了更高的重视。探测任务的性能也在8× 10^10环境步态后明显提升,传球者成功传球占到了60%。综上所述,这些观察结果表明,智能体理解向队友传球的好处,并且能够采取相应的行动。
总结
综合来说,本次研究解决了以下几项现有挑战:智能体产生自然且有效的类人行为;行为具有多维度层次结构;多智能体之间出现协调配合。此外,它所使用的的方法可随时迁移到其他任务中。在智能体研究中,这项研究成果向人类水平的智能运动迈出了一小步。
本次研究结果是在模拟真实的物理环境中获得的,更加开放的环境意味着更为复杂的行为策略,包括敏捷的动作和球员之间的身体接触。尽管最近已有一些将模拟行为转移到现实世界的成功案例,但这并不是本次实验的目标。
此外,这次的研究结果目前不适用于sim-to-real迁移,开发的方法也不适用于直接在机器人硬件上实现,其中原因有很多,如缺乏高质量数据、出于安全考虑等等。不过,它确实展示了基于学习的方法在产生复杂动作策略方面的潜力。需要强调的是,尽管模拟研究极大地简化了现实世界的复杂性,但它可以帮助我们理解各个方面的计算原理,并最终在现实世界中产生类似的行为。
相关链接:
https://www.youtube.com/watch?v=KHMwq9pv7mg
https://twitter.com/hardmaru/status/1397909538863423490
编辑:于腾凯

这篇关于DeepMind训练AI玩足球,风骚走位比中国男足都强(狗头)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








