本文主要是介绍字节跳动端到端深度学习召回算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:DataFunTalk
本文约2600字,建议阅读5分钟
本文为你介绍字节跳动AML Team在大规模推荐中构建的可学习的索引结构。[ 导读 ] 传统的召回算法一般基于双塔结构并加以approximately nearest neighbor search (ANN) 或者maximum inner productive search (MIPS),比如fast ball tree (FBT),hierarchical navigable small world (HNSW) 等。这些传统的算法embedding的训练目标和ANN的目标不一致,导致ANN的损失无法学习。目前比较著名的解决思路是构建一个tree-based model如TDM等。
我们今天将介绍字节跳动AML Team在大规模推荐中构建的可学习的索引结构,使得embedding的训练目标和索引结构的训练目标可以一致学习,达到良好的召回效果,它不仅局限于广告业务,在推荐和搜索业务中也有应用。
本文将从以下几方面展开:
Deep retrieval的核心模型
如何训练structure model
思考与讨论
精选问答
01、Deep retrieval的核心

如图所示我们可以根据DR的structure的KxD的矩阵构造出path。我们可以把这种path看成层级的聚类,每个path里面有很多的item,每个item也可以属于多个path,这样我们可以保留item的多元化信息。比如“同仁堂”可能是中药企业,也可以是一个相声,所以我们在搜索“同仁堂”对应的文章时,它既有可能在中医药的path出现,又有可能在相声中出现,达到了我们multi-path的效果。
1. 训练阶段的structure loss
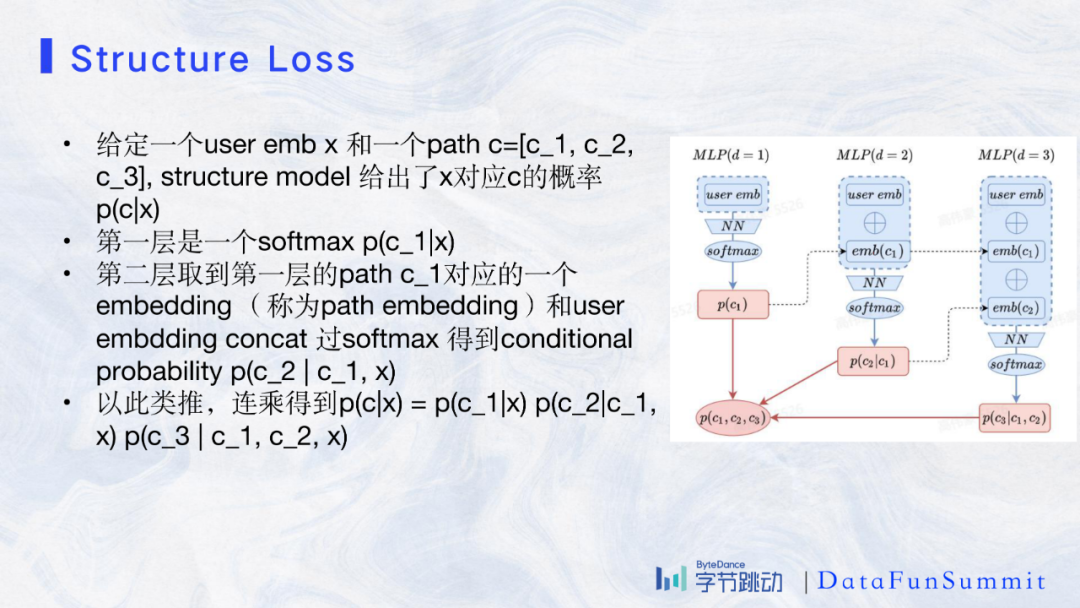
从上图的图例我们可以看到网络的结构,在第一层得到用户的embedding x 对应c_1的概率,之后path中的每一段都将用户embedding与之前的path embedding串联,最终得到path中当前code的条件概率。根据联合概率公式最终的概率为:
p(c|x)=p(c_1,c_2,c_3|x)=p(c_1|x)p(c_2|c_1,x)p(c_3|c_2,c_1,x)
在训练中已知正例用户embedding x和item id y, 如果我们知道y所在的path为π(y),则:
maxlogp(π(y)|x)=logp(π(y)1|x)+logp(π(y)2|π(y)1,x)+logp(π(y)3|π(y)1, π(y)2,x)
2. serving阶段的beam search
在serving阶段我们采用的是beam search的算法,具体如图所示:
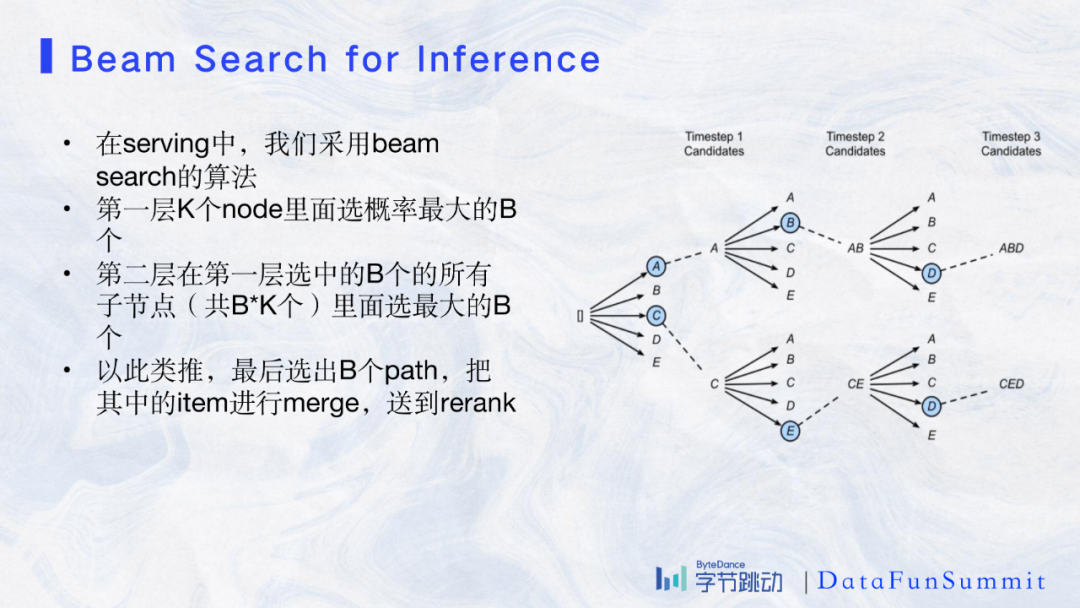
通过图中示意的方法,我们在每一层选概率最大的B个node向下传递,B是指beam size,通常选10个左右。最后我们选出B个path并merge其中的item。
02、如何训练structure model
1. EM算法
在DR中我们需要同时训练structure model的参数(记为θ),以及所有item到path的mapping(记为π),则训练目标为:
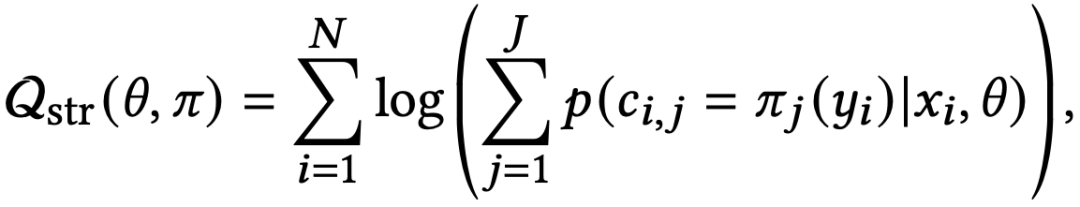
其中J是指J条path。我们想交替训练π和θ,于是采用EM算法来共同训练参数和mapping。最开始我们随机初始化θ和π并轮流进行E-step和M-step。
在E-step中,我们进行以下操作:一是可用任何基于梯度的优化算法优化θ,因为p_θ是可微的。二是对于每一个path c和item v计算它们的likelihood,记为s[v,c],也称为hidden score。
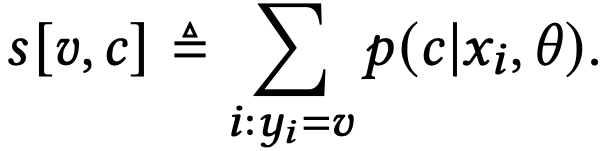
其中假设对于任何一个item v出现了n次,对应n个用户xi,我们计算平均p(c|x, θ)的likelihood。由于可能的path有K^D个而我们不可能全部计算,所以我们将只选取beam search分数较高的path并记录其hidden score。
在M-step中,我们需要从hidden path和hidden score中更新π(v)。最直接的方法是对于每一个item我们选取hidden path中分数最高的path作为新的π,这样在EM算法的objective function显然会达到很高的分数,但是这样做有一个缺点,即导致很多item学到一个path,使得path过于集中,即有的path中有大量的item,有的path里面没有item,这样的结果送到下游任务时,下游的压力就无法控制。为此我们引入patch-size penalty,我们令f(x)=x^4,α是可调参数,有:
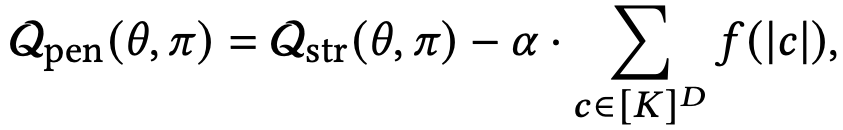
即减去所有path,每个path里面的item个数的四次方,如果当前path的item已经很多时,可以有效抑制item继续增加。
2. 在线EM算法
对于流式训练,我们设计了在线EM算法。在E-step中,我们将使用一个滑动的平均hidden score并且动态跟踪一个固定大小的hidden path set。在M-step中我们采取定时任务的方式,从Parameter Server里面读取每个item的hidden path和hidden score,然后运行上段所说的penalty 算法计算出新的true path并写入到PS。
3. 多任务学习
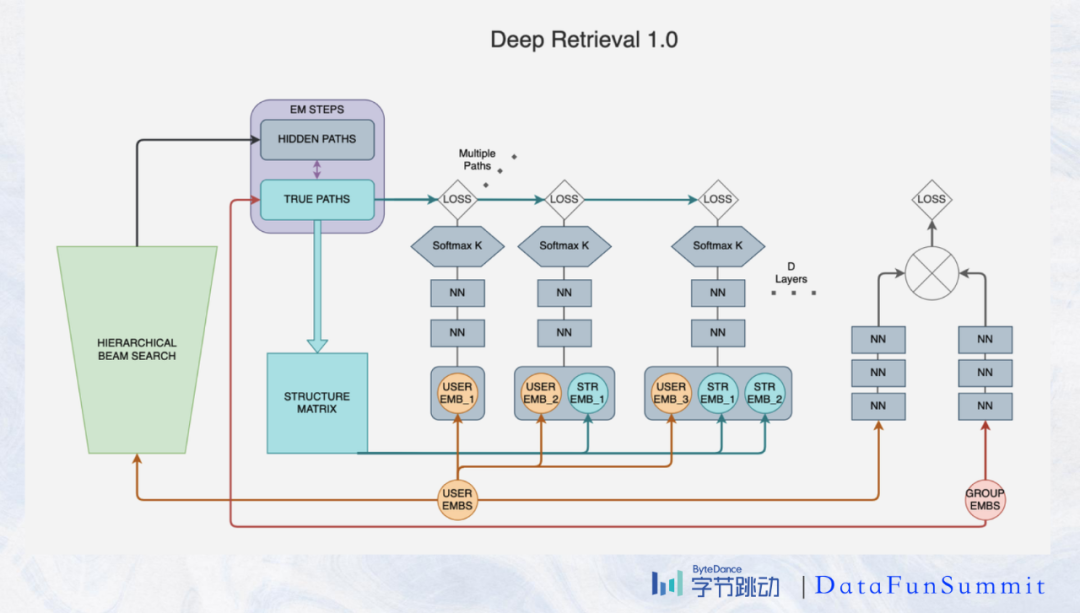
现在的DR采用multi-task learning的机制,我们使用structure loss来训练structure model以及item-path mapping,同时我们也保留了点乘模型比如FFM,NN模型来训练user或者item embedding用作reranker。在serving过程中,我们通过beam search找出hidden path以及他们的item,先经过reranker经过初步筛选出固定条数的candidates,再精排。这样可以减缓了粗排和精排的压力,另一方面也可以控制出口条数。
03、思考与讨论
与传统的ANN相比,DR的聚类更注重用户侧行为而不是item本身,比如足球视频和汽车视频在ANN召回中可能不在同一类但是在DR中会在同一类。DR其实不是利用item embeddeing本身,而是利用user和item之间的信息,利用hidden score进行聚类,即虽然两个item本身并不相近,但是他们可能会被同一种user消费。所以DR中path里面item的diversity会比ANN高很多。
因此DR更偏向于偏重用户行为的应用场景,比如广告或者推荐,在搜索中DR通常会降低相关性。
DR的structure model目前只用了正例没有负例,负例只在rerank model中使用。而且structure model只使用了item ID embedding,没有使用item侧特征,item侧特征只在rerank model中使用。除此之外,DR的学习目标之来源于user,item pair没有体现相关性,如果能将相关性loss引入DR loss来端到端学习用户行为和相关性也许可以解决搜索遇到的问题。
04、精选问答
Q:同一个item是否属于同一个D?
A:首先,同一个item是可以属于多个path, 比如“同仁堂”既可以属于相声的path又可以属于中医药的path, 在不同层的code中,item也可以属于多个,比如属于1,2,3 code,1,2,4 code。着代表两个path在类方向是一致的。
Q:retrieval算法学到的聚类结构与U2U的算法的聚类结构有什么关系?
A:有可能有一定关系,聚类的结果更容易把相同用户消费的物品聚到一起。
Q:什么在检索的过程中要用beam search而不是全部检索完?
A:因为一般线上K是100到1000,D是3,如果全部检索则需要检索至少百万级别的path,是不符合实际的。所以我们需要一个方法选择比如top20的path,这个方法选择的top20和实际的top20非常相近,beam search这个方法满足了我们的需求。
Q:EM算法的收敛性是否有保证,在实际应用中是否会出现不收敛的情况?
A:在理论上是有一些paper论证过EM算法在哪些条件下可以收敛,这些理论上的假设理论性比较强。在实际情况下我们回去检验一些这些条件,有时候也可以直接看结果。在非流式训练的情况下,我们的算法经过3到5个M-step以后会收敛到稳定的值。在流式训练中,我们通过定时M-Step的方法,实际在5到10次M-step可以达到收敛,这些都是一些比较实践的方法。
Q:这个方法是召回用户的多兴趣那么也没有和其他的一些用transformer的方法做对比?
A:我们在做多兴趣召回,目前和transformer的关系还不是特别紧密,我们大概的做法也是生成不同的user embedding, 对不同的user embedding做 beam search, 对 search的结果进行一些merge并通过一些loss控制不同的embedding学习不同的兴趣,但是transformer我们还没有尝试。
Q:不加multi-task模型会变成什么样?M-step是否只做一次?
A:不加multi-task模型学到的path非常不平衡,虽然我们有penalty进行控制但是还是不够,这是因为不加multi-task负例没有被利用,item embedding也没有被充分利用,所以这就是为什么我们现阶段使用了multi-task。M-step需要做不止一次的,实际我们需要等到模型收敛,这至少要一两天的时间。
Q:这个模型的线上效果如何?
A:这个模型已经在字节跳动不少的产品上线,覆盖广告和推荐,海内外产品都有应用,效果还是很成功的。
今天的分享就到这里,谢谢大家。
编辑:于腾凯
校对:林亦霖
这篇关于字节跳动端到端深度学习召回算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



