本文主要是介绍AI芯片竞争白热化!Meta官宣最新AI推理芯片!性能提升300%,支撑Llama高负载计算,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在算力为王的大模型时代,AI技术“三巨头”:微软,谷歌,Meta,在自研芯片领域卷的是热火朝天。
最早是微软,在去年宣布基于台积电5nm技术制造了Azure Maia 100及Azure Cobalt 100芯片。前几天,谷歌也发布了自研数据中心芯片Axion,以应对高昂的AI竞赛成本。
这次Meta又有了大动作,发布第二代芯片Meta Training and Inference Accelerator v2(MTIAv2)。
GPT-3.5研究测试: https://hujiaoai.cn
GPT-4研究测试: https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4): https://hiclaude3.com
话不多说,先来看看MTIAv2的硬件表现。
容量、计算、带宽翻倍
在工艺和性能方面,相比于Meta去年5月推出的MTIAv1采用的台积电7nm芯片,MTIAv2则换上了台积电5nm芯片,频率从800MHz提升到1.35GHz,稠密算力达到上一代的近3.5倍,稀疏算力达到上一代的近7倍,INT8精度下达到708TFLOPS。
这主要得益于稀疏计算的流水线相关的体系结构的改进,以及本地PE存储、片上SRAM以及LPDDR5容量的翻倍,并将其带宽增加到3.5倍。

能耗方面,从25W提升到了90W。值得一提的是,英伟达H100的功耗约在350~500W,INT8精度下稀疏算力为3026TFLOPS,每瓦性能和MTIAv2基本差不多。在平台层,通过2倍的设备数量和2插槽CPU,MTIAv2能够实现6倍的模型服务吞吐量、比MTIAv1系统提高多达1.5倍的每瓦性能。
在架构设计方面,MTIAv2主要为排名和推荐模型提供服务,这些模型中,模型大小和每个输入样本的计算量可能相差约10-100倍。因此,芯片设计考虑了计算、内存带宽和内存容量的平衡,即便其batch size大小相对较低,也能提供相对较高的利用率。
然而,芯片竞赛的挑战不仅在于芯片本身,其完整的计算生态也至关重要。
Meta完整的计算生态
相比商用GPU,MTIAv2可实现更高的效率,这得益于Meta在芯片的生产和使用中可以控制全栈,比如它的配套硬件、软件、编译器等.
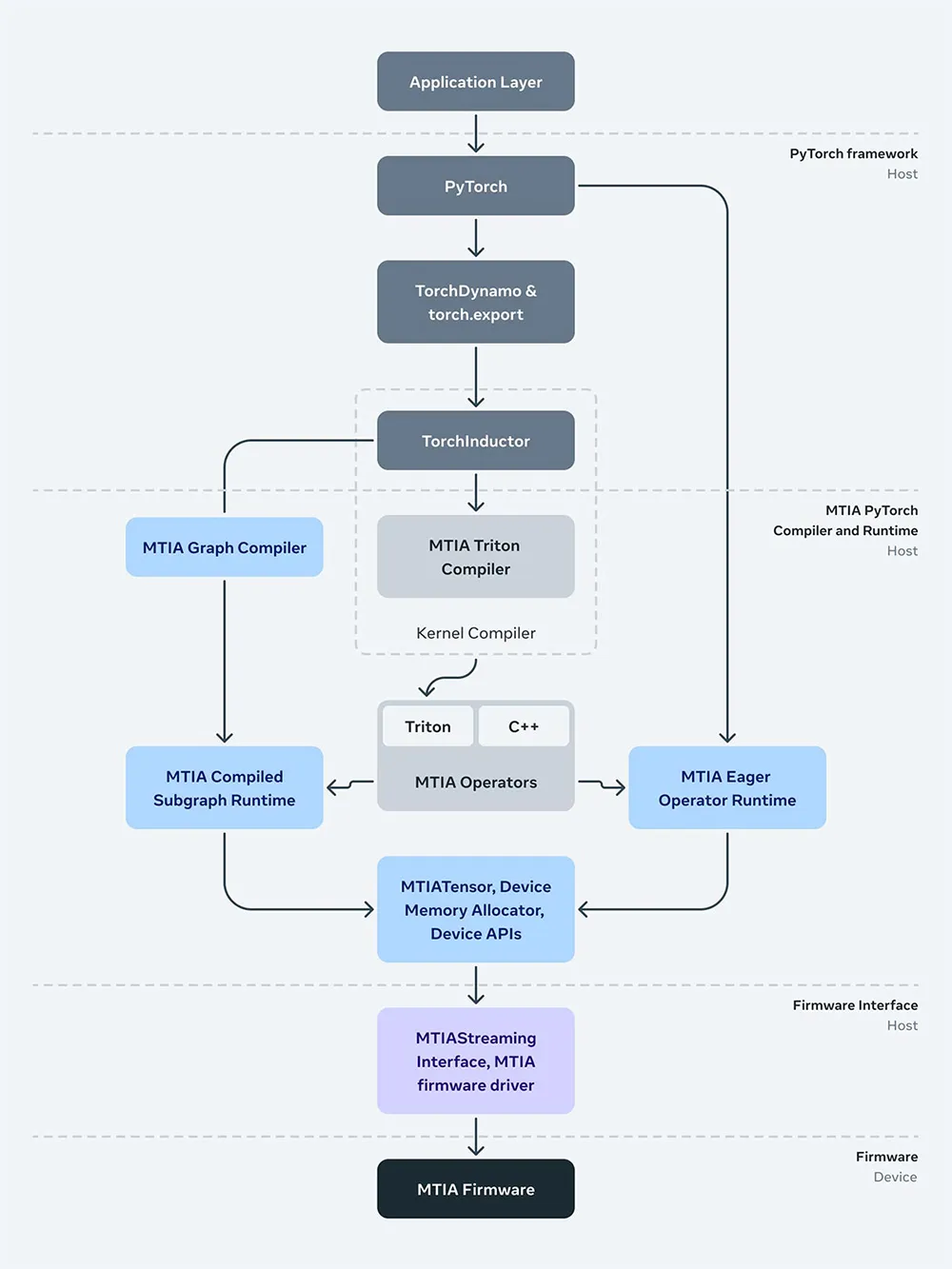
▲MTIAv2全栈的计算生态
在配套硬件方面,Meta开发了一个大型的机架式系统,它由3个机箱组成,每个机箱包含12块电路板,每块电路板上有2块芯片,总计可容纳72个MTIAv2。
Meta特别设计了这个系统,使芯片的功率和性能都能充分发挥,系统通信采用PCIe Gen5,以增加系统的带宽和可扩展性。如果选择扩展到机架之外,还能选择添加RDMA网卡。

在软件方面,作为PyTorch的初始开发人员,Meta团队重视可编程性和开发效率,MTIA堆栈旨在与PyTorch 2.0、TorchDynamo和TorchInductor的完全集成。优化了前端的图形处理流程,包括捕获、分析、转换和提取操作,以及与MTIA硬件无关的可复用机制。

在编译器方面,MTIA的较低级别编译器从前端接受图形输出,生成既高效又针对设备优化的代码。在此之下是负责与驱动程序/固件接口的运行时堆栈,MTIA流式处理接口提供了管理设备内存、在设备上运行运算符以及执行编译图所需的基本操作。

为了提高代码的性能,Meta创建了Triton-MTIA编译器后端,这是一个高效的机器学习计算内核编写工具,旨在为MTIA硬件生成优化代码。Triton语言的硬件无关性使其适合于MTIA这样的非GPU硬件架构。Triton-MTIA后端通过执行硬件利用率优化和支持高性能内核来进一步提升效率,并提供了自动调优功能,以探索最佳的内核配置。
Meta通过将Triton语言特性和PyTorch 2.0集成,扩展了对PyTorch操作符的支持,使得开发人员可以在编译前(AOT)和即时编译(JIT)工作流程中利用Triton-MTIA,极大提高了开发效率和计算内核创作的可扩展性。
未来将持续投资
Meta去年资本支出为280亿美元,占其收入的21%,今年将继续扩大支出规模,预计将高达370亿美元,其中大部分用于与AI相关的服务器和数据中心建设,比如向英伟达大量采购GPU芯片以及MTIAv2的研发。

Meta在官网上说到“MTIA将成为我们长期规划的重要组成部分,旨在为Meta独特的AI工作负载构建和扩展最强大、最高效的基础设施”,这实际上也是为其大模型蓄力,据说下周Meta将推出140B参数的Llama 3大语言模型,参数量比上一代的2倍还多。
未来,我们也可以继续期待AI硬件领域的技术突破,以及技术前沿的不断拓展。


这篇关于AI芯片竞争白热化!Meta官宣最新AI推理芯片!性能提升300%,支撑Llama高负载计算的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





