本文主要是介绍GAMES Webinar 317-渲染专题-图形学 vs. 视觉大模型|Talk+Panel形式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 两条路线:传统渲染路线,生成路线
- 两种路线的目的都是最终生成图片或者视频等
- 在现在生成大火的情况下,传统路线未来该如何发展呢,两种路线是否能够兼容呢
严令琪

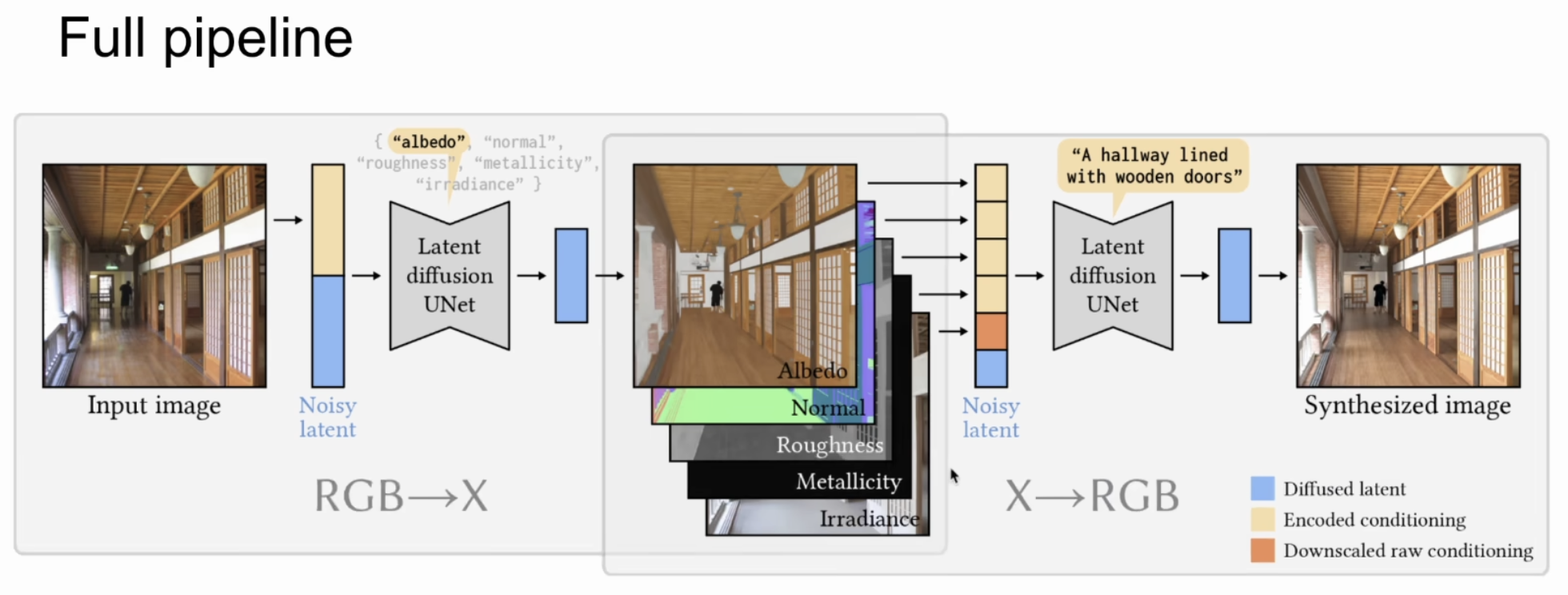
- 这篇工作是吸取这两条路各自优势的一篇工作
- RGB是一张图,X是生成模型根据图片生成的东西,可以认为是一个buffer(特征性,控制性的东西),它可以被修改,并且可以再生成一张图
- 想生成真实的图and又想精准的控制,就是这篇文章的思想

- X: intrinsic channels(G-buffers)是几何缓冲区
- 现在是用X去生成RGB图,当然也沿用以前的语言模型,也就是文本
- 当然这个工作也完成了给一张RGB图,从中提取G-buffers
- 这个工作可以让X生成RGB的过程可控,也就是可以生成想要的图,支持图片编辑(比如,给一张RGB图,提取出G-buffers,修改,再生成图)
RGB->X

- 可以根据文本(关键词)提取出最多这五种信息
X->RGB

- 根据X的信息可以走传统的渲染过程,也可以不走,用扩散模型生成
- 也不用把X的五种信息都给才生成图片,给哪些,哪些就体现在生成结果上
pipeline
Results






霍宇驰






- 对于AI来说,未来NPU应该比GPU更重要

sora

- sora是一种模糊语言来生成,也就是文本
- 未来可能可以通过模糊文本一点点修改结果到自己需求那样
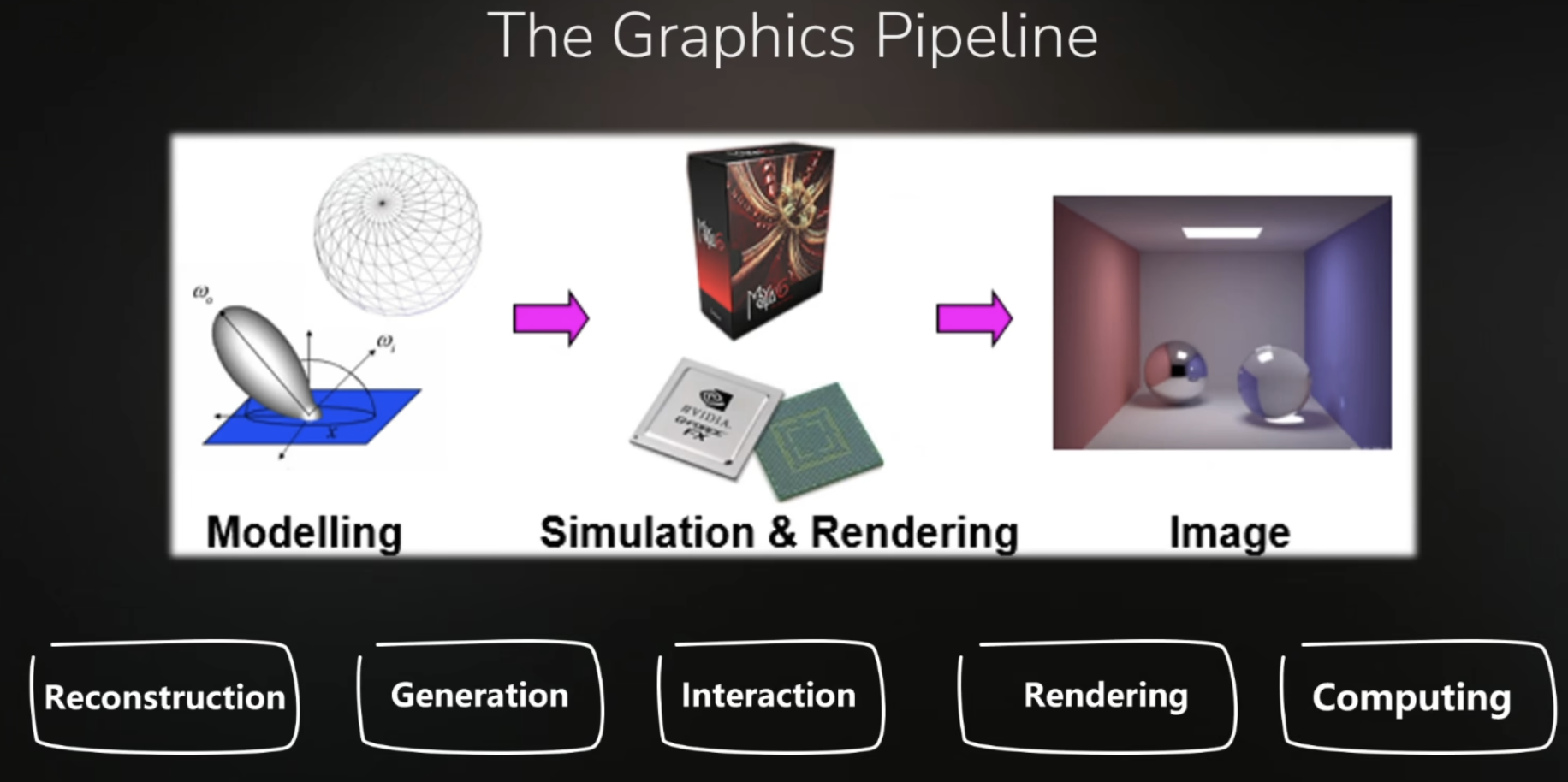
- 传统的图像管线是精细化生成,sora是模糊生成
- 而且传统的管线,前面几步骤完成后,最后结果的生成不用再做前面一些步骤,但sora每次都要从0开始
- 具体用哪个看需求是在精细度的哪个层级
- 目前也有很多工作在把两个连接起来
王利民
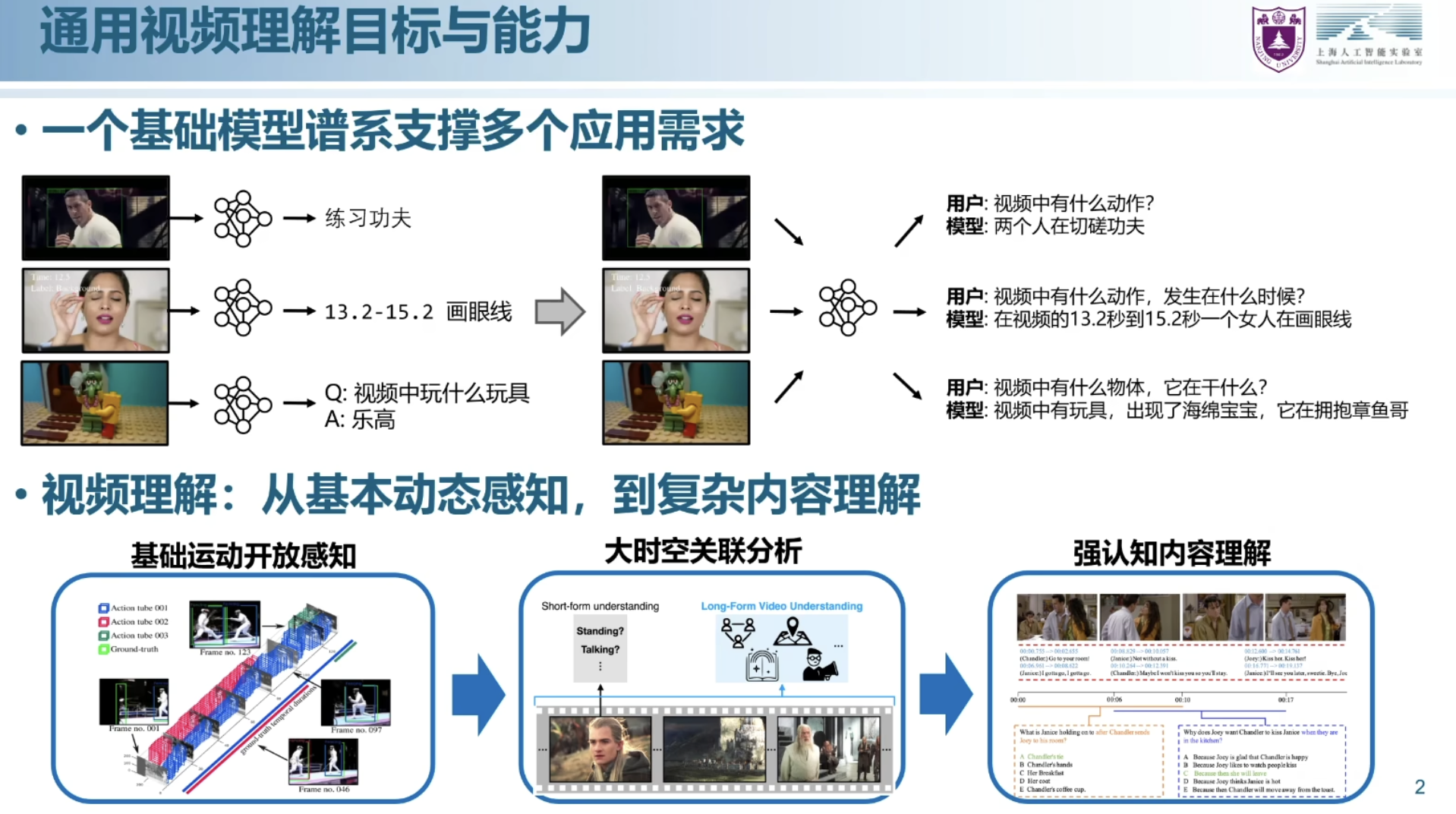



- 第一阶段单模态的信息抽取
- 第二阶段多模态,涉及到音频和文本,要进行对齐
- 第三阶段多模态的生成与对话能力
第一阶段
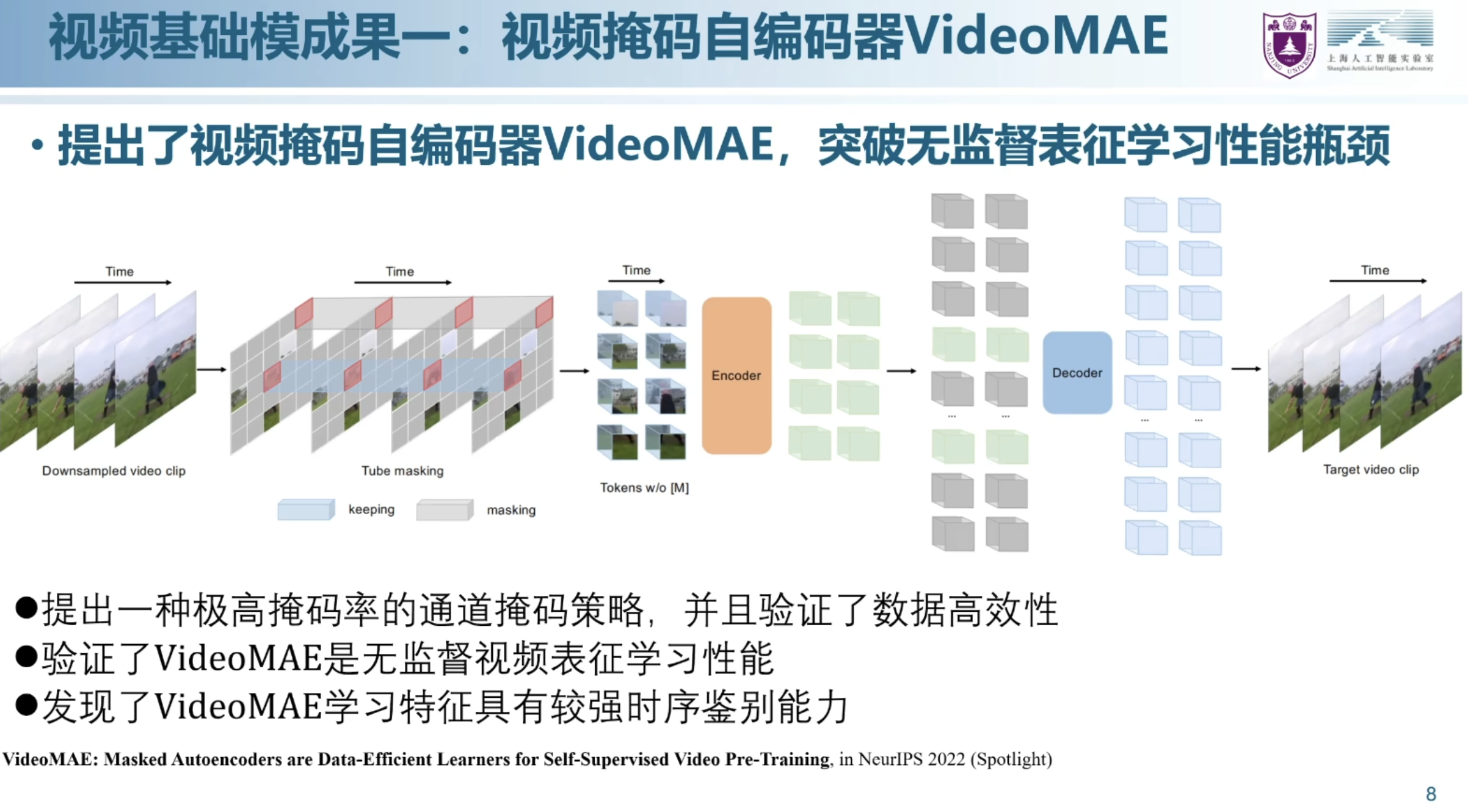
- 将视频进行掩码处理,再生成

第二阶段

- 多模态对齐
第三阶段





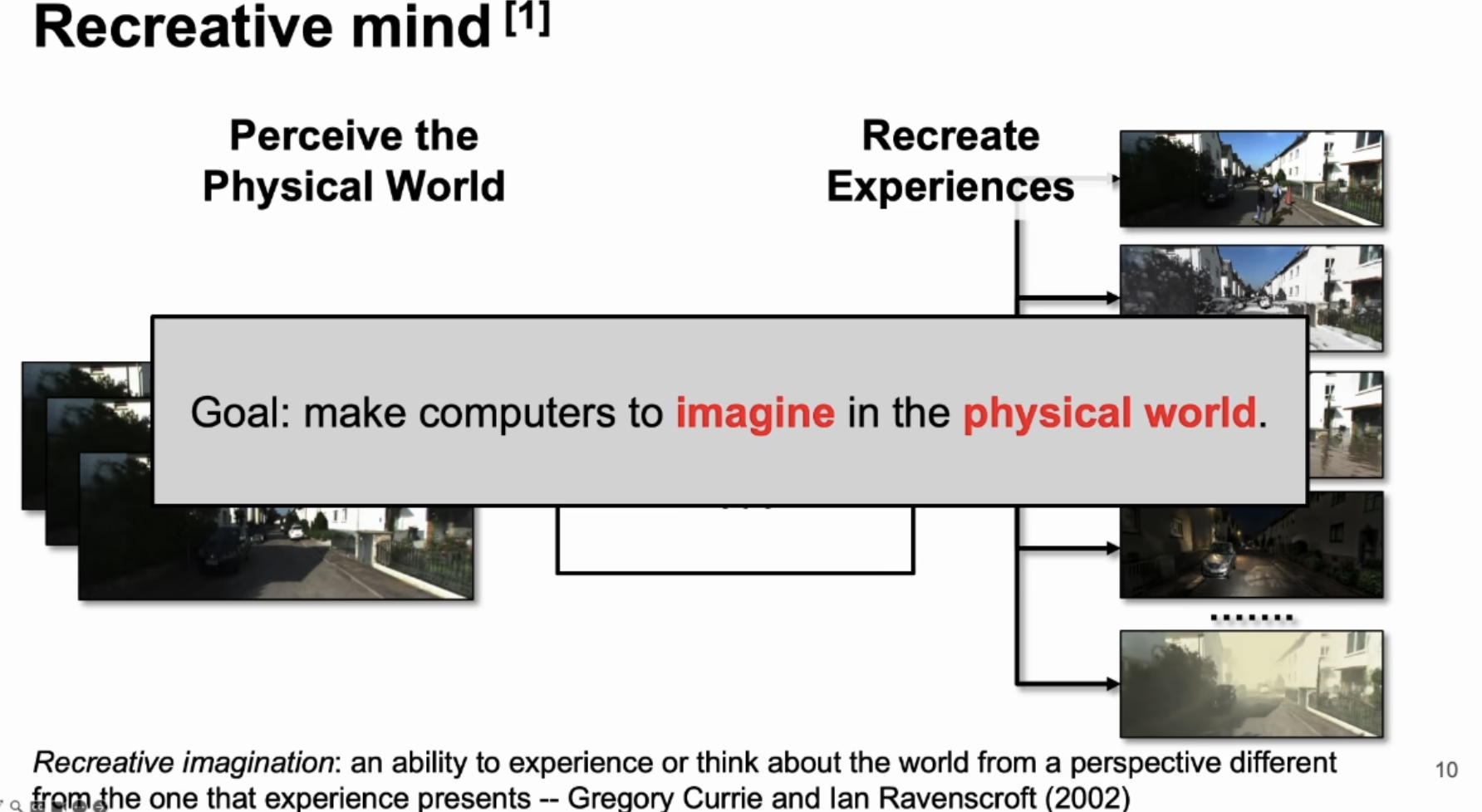
总结

王申龙

QA
- sora如此强大,传统图形学是否与到了大挑战?
- 闫令琪:它是有缺陷的,比如会凭空多东西,少东西,这些缺陷可能在这个时代,在sora表现这么好的情况下,可以容忍,但它是不好解决的,因为它是神经网络控制的,不是那么可控。sora它现在是一个快速发展阶段,但它一定会进入瓶颈期的,包括传统的渲染生成,也进入过瓶颈期,也就是从0到90,快速发展,但最后10是很难完成的,比如比较好的控制,小瑕疵的解决
- 霍宇驰:我同意sora能做到百分之90,95的效果,但它比较适合做一些离线工作,在实时工作中出现百分之10、5的错误是不能容忍的。在实时和交互方面,图形学应该是有一定优势
- 王利民:不止sora,包括gpt这些也是存在幻觉的,它是不好解决的,未来一定要加入理解和约束的知识来控制生成,尽管sora它会有瑕疵,但是它肯定会慢慢被接受,比如自动驾驶:找一个老司机开也会犯错误
- 王申龙:社区有非常大的优势,它能够让一个什么也不会的人做生成
- 光线追踪还能打几年,或者还有几年要失业?
- 严令琪:具体情况要看应用,需要精准控制的还是要走这种完全可控的渲染路线。实时渲染没有任何可以修正的余地,用生成性模型生成失败了怎么办,比如打游戏。很多东西会有一个长期共存的状态,比如从光栅化转到光线追踪,已经很多年了,但现在还是处于共存状态
- 霍宇驰:光线追踪一定会存在一些特定领域,但蛋糕就这么大,sora一定会切走一块
- 进行城市级别的场景生成会有什么困难?
- 王申龙:要保持从A到B然后再回到A,还是相同的A是比较困难的
这篇关于GAMES Webinar 317-渲染专题-图形学 vs. 视觉大模型|Talk+Panel形式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








