本文主要是介绍AI论文速读 |【综述】 时序分析基础模型:教程与综述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文标题:Foundation Models for Time Series Analysis: A Tutorial and Survey
作者: Yuxuan Liang(梁宇轩), Haomin Wen(温浩珉), Yuqi Nie(PatchTST一作), Yushan Jiang, Ming Jin(金明), Dongjin Song, Shirui Pan(潘世瑞), Qingsong Wen(文青松)
机构:香港科技大学(广州),北京交通大学,普林斯顿大学,康涅狄格大学,莫纳什大学,格里菲斯大学,松鼠AI
论文链接:https://arxiv.org/abs/2403.14735
Cool Paper:https://papers.cool/arxiv/2403.14735
TL;DR:本文全面介绍了基础模型在时间序列分析中的应用,重点关注模型架构、预训练技术、适应方法和数据模态,以增进理解和推动该领域的发展。
关键词:时间序列分析, 基础模型, LLM

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
摘要
时间序列分析是数据挖掘社区中的焦点,是提取对无数实际应用程序至关重要的有价值见解的基石。 基础模型 (FM) 的最新进展从根本上重塑了时间序列分析的模型设计范式,在实践中推动了各种下游任务。 这些创新方法通常利用预先训练或微调的 FM 来利用专为时间序列分析定制的通用知识。 在本综述中,目标是提供用于时间序列分析的 FM 的全面且最新的概述。 虽然之前的综述主要关注 FM 在时间序列分析中的应用或流程方面,但它们往往缺乏对阐明 FM 为何以及如何有益于时间序列分析的基本机制的深入理解。 为了解决这一差距,本综述采用了以模型为中心的分类,描述了时间序列 FM 的各种关键要素,包括模型架构、预训练技术、适应方法和数据模式。 总体而言,这项综述旨在巩固与时间序列分析相关的 FM 的最新进展,强调其理论基础、最近的发展进展以及未来研究探索的途径。
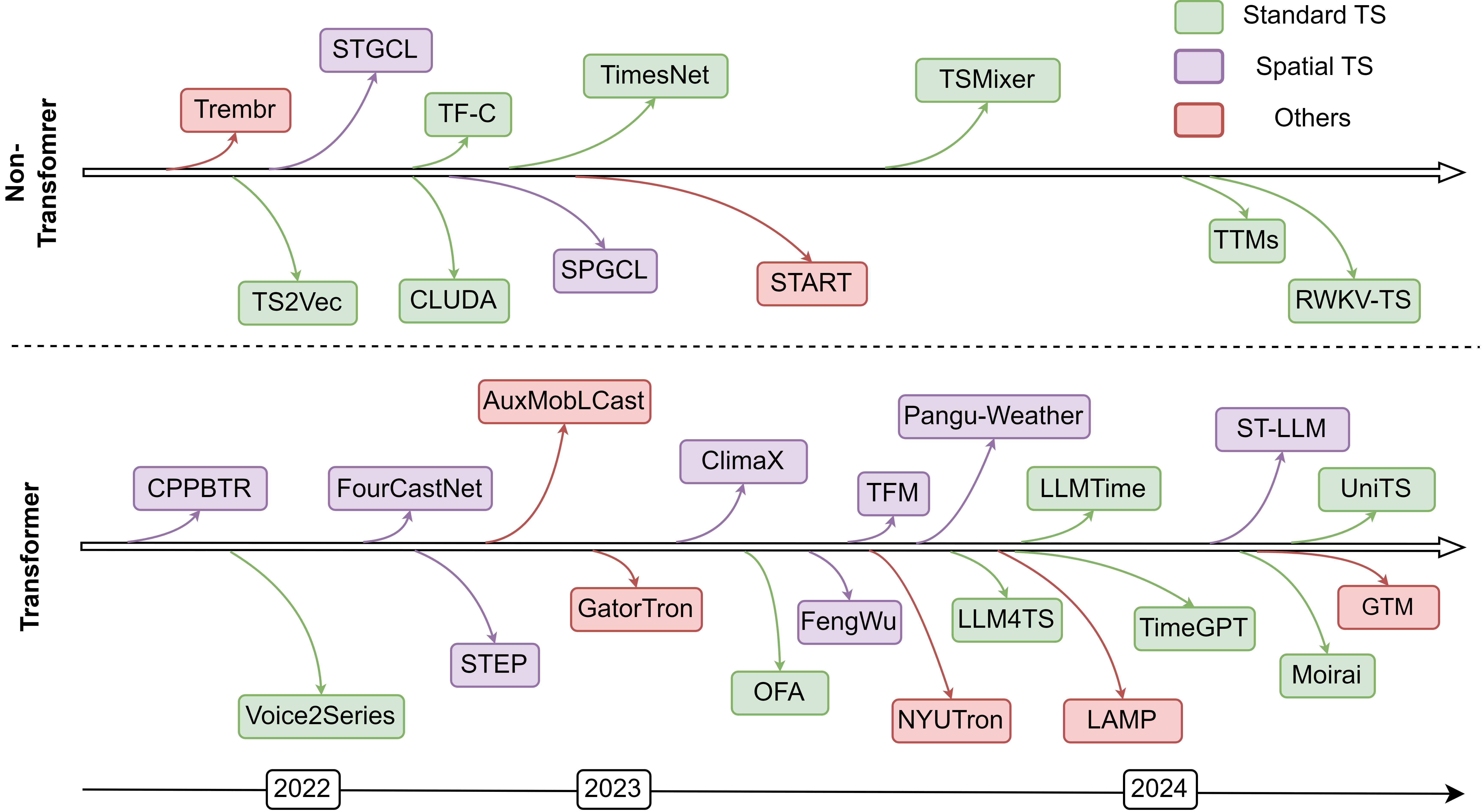
Q: 这篇论文试图解决什么问题?
A: 这篇论文《Foundation Models for Time Series Analysis: A Tutorial and Survey》旨在提供一个全面且最新的关于时间序列分析中基础模型(Foundation Models, FMs)的概述。论文试图解决的问题是,尽管时间序列分析在数据挖掘社区中占有核心地位,并且在许多实际应用中至关重要,但是现有的文献对于时间序列分析中基础模型的系统性分析却相对缺乏。特别是,以往的研究要么集中在应用层面,要么集中在流程方面,但往往缺乏对基础模型如何以及为何能够提升时间序列分析的深入理解。
为了解决这一问题,论文采取了以下措施:
- 模型中心分类:通过模型中心的分类方法,明确了时间序列基础模型(Time Series Foundation Models, TSFMs)的各个关键要素,包括模型架构、预训练技术、适应方法和数据模态。
- 最新进展的整合:综合了最新的关于时间序列分析中基础模型的进展,强调了它们理论基础、最近的发展动态,以及未来研究的探索方向。
- 未来研究方向的探讨:讨论并强调了使用基础模型增强时间序列分析的未来研究机会,鼓励研究人员深入探索这一领域。
总的来说,这篇论文试图通过提供一个方法论中心的分类框架,来弥补现有文献中对于时间序列分析中基础模型作用机制理解的空白,并推动该领域的研究和应用发展。
Q: 有哪些相关研究?
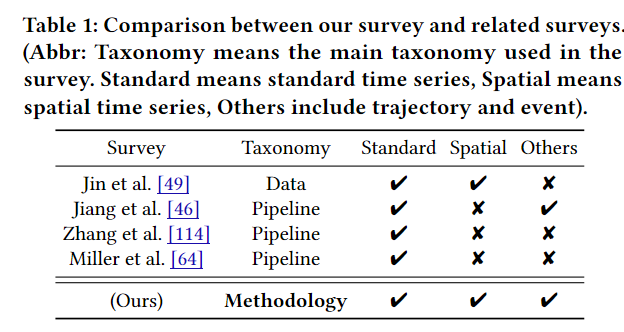
提到的4篇综述:
- Jin M, Wen Q, Liang Y, et al. Large models for time series and spatio-temporal data: A survey and outlook[J]. arXiv preprint arXiv:2310.10196, 2023.
- Jiang Y, Pan Z, Zhang X, et al. Empowering Time Series Analysis with Large Language Models: A Survey[J]. arXiv preprint arXiv:2402.03182, 2024.
- Zhang X, Chowdhury R R, Gupta R K, et al. Large Language Models for Time Series: A Survey[J]. arXiv preprint arXiv:2402.01801, 2024.
- Miller J A, Aldosari M, Saeed F, et al. A survey of deep learning and foundation models for time series forecasting[J]. arXiv preprint arXiv:2401.13912, 2024.
A: 这篇论文中提到了多项与时间序列分析中基础模型(TSFMs)相关的研究,这些研究涵盖了不同的数据模态、模型架构、预训练技术和应用领域。以下是一些具体的相关研究:
- 标准时间序列(Standard Time Series):
- Time-LLM [48]: 利用预训练的大型语言模型(LLM)进行时间序列预测。
- TempCast [101]: 通过提示工程(prompt engineering)和大型语言模型进行时间序列预测。
- PatchTST [67]: 使用生成模型进行时间序列分析。
- TimeGPT-1 [35]: 一个基于生成模型的时间序列预测方法。
- 空间时间序列(Spatial Time Series):
- ST-LLM [57]: 结合空间-时间信息和部分冻结的大型语言模型进行交通预测。
- FourCastNet [69]: 用于全球天气预报的数据驱动模型。
- ClimaX [66]: 用于气候和天气相关任务的通用气候基础模型。
- 其他类型的时间序列(Others):
- AuxMobLCast [102]: 利用预训练的大型语言模型进行人类移动性预测。
- GTM [55]: 用于轨迹数据的通用轨迹建模方法。
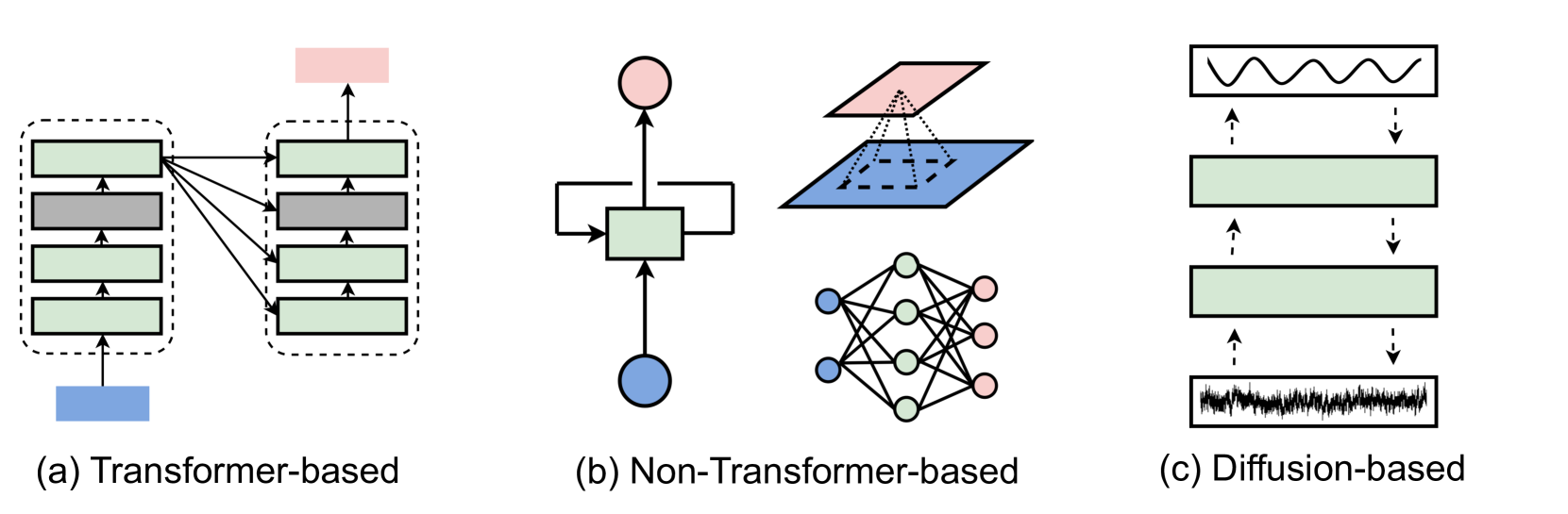
- 非Transformer基础模型:
- TSMixer [31]: 轻量级的基于多层感知器(MLP)的时间序列预测模型。
- TimesNet [98]: 用于一般时间序列分析的基于卷积神经网络(CNN)的模型。
- 基于扩散模型(Diffusion-based):
- TimeGrad [76]: 用于多变量概率时间序列预测的自回归去噪扩散模型。
- DiffSTG [93]: 结合去噪扩散模型进行概率空间-时间图预测。
这些研究代表了时间序列分析中基础模型的最新进展,并且论文还讨论了这些模型在金融、医疗保健、交通、气候和其他领域的应用。此外,论文还提出了一个全面的分类法,将TSFMs分为不同的类别,包括基于Transformer的模型、非基于Transformer的模型(如MLP、RNN、CNN)和基于扩散的模型,以及它们在不同数据模态下的应用。
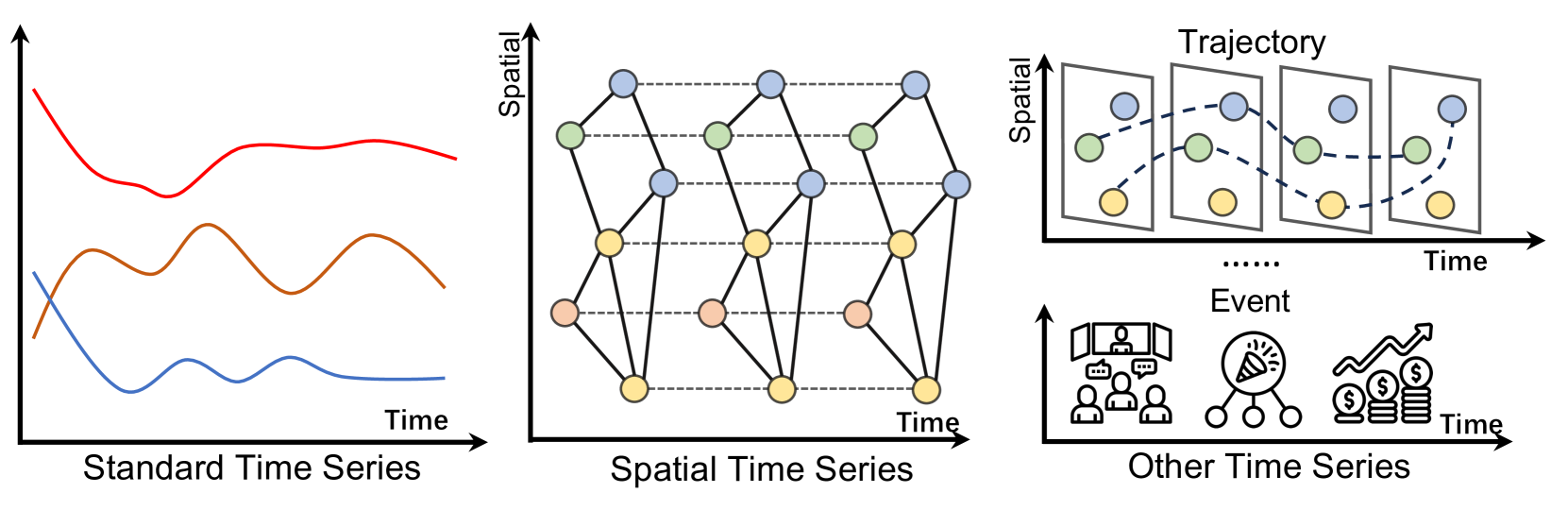
Q: 论文如何解决这个问题?
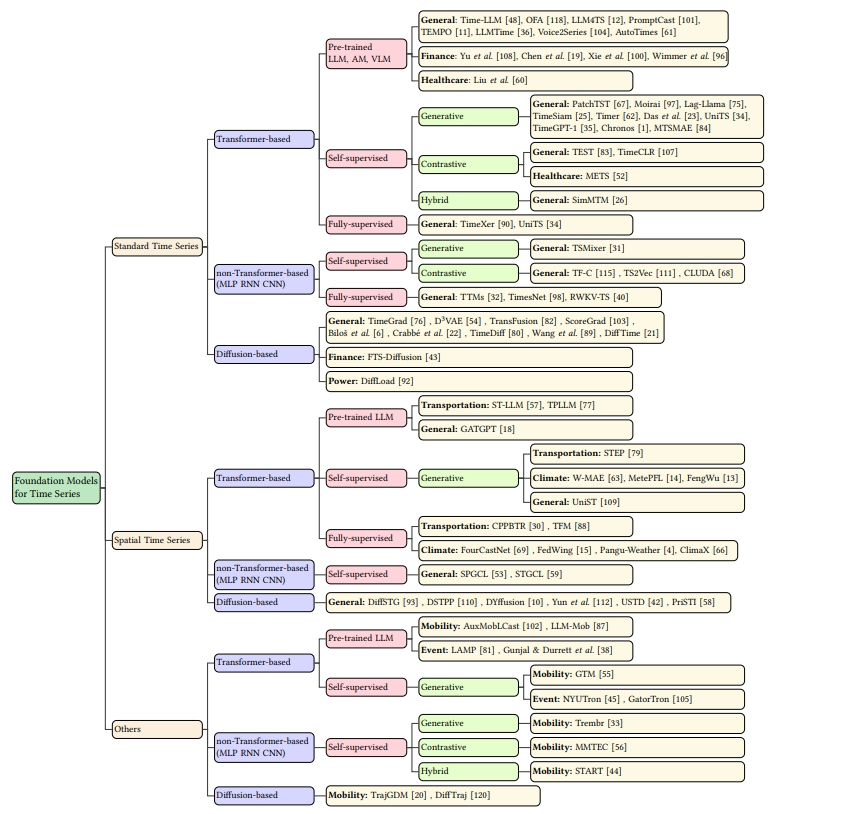
A: 为了解决现有文献中对时间序列分析中基础模型(TSFMs)缺乏系统性分析的问题,论文采取了以下方法:
- 模型中心分类(Model-Centric Classification):
- 提出了一个新的分类框架,专注于从方法论角度对TSFMs进行分类,包括模型架构、预训练技术、适应方法和数据模态。
- 通过这种分类,论文详细审视了构成时间序列基础模型的关键元素,从而深入理解这些模型在时间序列分析中的工作机制。
- 全面的最新进展概述(Comprehensive and Up-to-Date Overview):
- 论文提供了一个全面的最新进展概述,包括标准时间序列、空间时间序列和其他类型(如轨迹和事件)。
- 总结了当前TSFMs的发展路线图,以促进该领域的进一步创新和理解。
- 未来研究方向的探讨(Discussion of Future Research Directions):
- 论文讨论了使用基础模型增强时间序列分析的未来研究机会,鼓励研究人员探索新的方法和技术。
- 指出了未来可能的研究方向,如结合多模态数据、探索更高效的架构、开发更有效的预训练和适应技术,以及保护隐私等。
- 理论基础与实际应用的结合(Integration of Theoretical Foundations and Practical Applications):
- 论文不仅关注理论分析,还强调了TSFMs在实际应用中的潜力,如金融、医疗、交通等领域。
- 通过案例研究和应用实例,展示了TSFMs如何在不同领域中发挥作用。
通过上述方法,论文旨在为时间序列分析中的基础模型提供一个深入的理解和全面的视角,同时为未来的研究和应用奠定基础。
Q: 论文做了哪些实验?
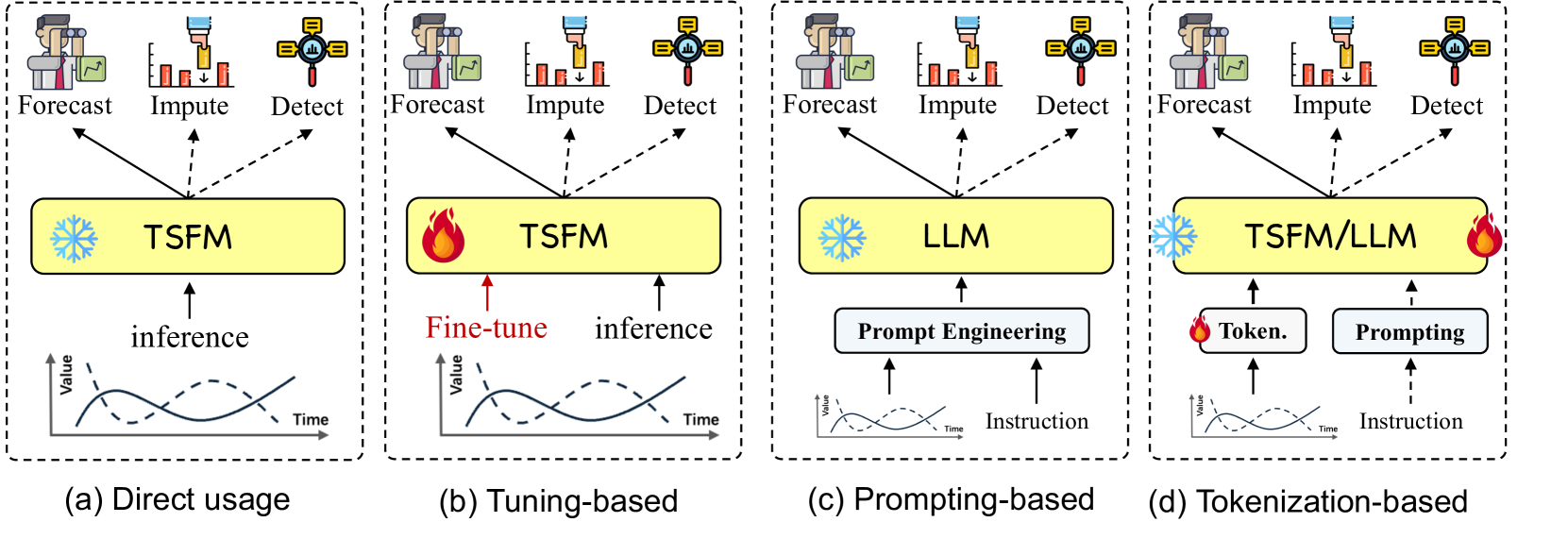
A: 这篇论文是一个关于时间序列分析中基础模型(Foundation Models, FMs)的教程和综述,而不是一个实验性研究。因此,它没有进行实验或者提供实验结果。相反,论文的主要贡献在于:
- 文献回顾:对现有的时间序列分析中基础模型的研究进行了全面的回顾,总结了这些模型在不同领域的应用和效果。
- 分类框架:提出了一个新的模型中心分类框架,用于对时间序列基础模型进行分类和分析。
- 理论分析:深入探讨了时间序列基础模型的理论基础,包括模型架构、预训练技术、适应方法和数据模态等方面。
- 未来方向:讨论了时间序列分析中基础模型的未来研究方向和潜在的研究机会。
综述论文通常不会包含实验部分,而是依赖于对现有研究的分析和综合,以提供该领域的全面视角和最新进展。在这种情况下,论文的价值在于为研究人员和实践者提供一个关于时间序列分析中基础模型的系统性理解的资源。
Q: 有什么可以进一步探索的点?
A: 论文提出了未来研究方向,可以进一步探索的点包括:
- 多模态数据的结合:
- 探索如何将时间序列数据与其他模态数据(如文本、图像、音频等)结合起来,以学习更全面和泛化的知识,从而提高不同下游任务的性能。
- 更高效的架构探索:
- 研究除了Transformer之外的更高效的基础模型架构,例如状态空间模型(如Mamba),以处理长序列数据时减少计算成本和内存消耗。
- 更有效的预训练和适应技术:
- 开发新的预训练策略来更好地处理时间序列数据的独特属性,如时间分布偏移和因果关系。
- 探索适应技术,以便模型能够更好地泛化到新的时间序列任务和数据集。
- 隐私保护:
- 在训练基础模型时考虑到隐私保护,发展新的隐私保护技术,如联邦学习,以在不泄露敏感信息的情况下利用多源数据。
- 解释性和透明度:
- 提高模型的解释性和透明度,使研究人员和用户能够理解模型的决策过程,特别是在敏感应用(如医疗和金融)中。
- 跨领域和跨任务的泛化能力:
- 研究如何提升模型在不同领域和任务之间的泛化能力,例如通过元学习和迁移学习技术。
- 模型稳健性和健壮性:
- 研究如何提高模型在面对噪声数据、异常值和攻击时的稳健性和健壮性。
- 实时和在线学习:
- 探索如何使基础模型适应实时和在线学习场景,以便能够处理连续到来的数据流。
这些方向不仅为学术研究提供了新的机遇,也为实际应用中的挑战提供了可能的解决方案。未来的研究可以围绕这些点展开,以推动时间序列分析领域的发展。
Q: 总结一下论文的主要内容
A: 这篇论文《Foundation Models for Time Series Analysis: A Tutorial and Survey》主要内容可以总结如下:
- 背景与动机:
- 时间序列分析对于数据挖掘社区至关重要,能够为多种实际应用提供宝贵洞察。
- 基础模型(FMs)在时间序列分析中的应用已经显著提升了多个下游任务的性能。
- 研究缺口:
- 尽管FMs在时间序列分析中取得了进展,但现有文献缺乏对这些模型背后机制的深入理解。
- 主要贡献:
- 提出了一个新的模型中心分类法,对时间序列基础模型(TSFMs)的关键元素进行了全面分析。
- 整合了最新的TSFMs进展,强调了它们在时间序列分析中的理论基础和实际应用。
- 探讨了未来研究方向,鼓励更深入地探索基础模型在时间序列分析中的潜力。
- 分类框架:
- 根据数据类别(标准时间序列、空间时间序列和其他类型),模型架构(基于Transformer、非基于Transformer和基于扩散的模型),预训练技术和应用领域对TSFMs进行了分类。
- 未来研究方向:
- 推荐了多个未来研究的潜在方向,包括结合多模态数据、探索更高效的架构、开发更有效的预训练和适应技术,以及保护隐私等。
- 结论:
- 论文提供了一个全面的方法论视角,以理解和应用基础模型于时间序列分析,同时指出了该领域的最新进展和未来可能的创新工作。
未来研究方向:
- 推荐了多个未来研究的潜在方向,包括结合多模态数据、探索更高效的架构、开发更有效的预训练和适应技术,以及保护隐私等。
- 结论:
- 论文提供了一个全面的方法论视角,以理解和应用基础模型于时间序列分析,同时指出了该领域的最新进展和未来可能的创新工作。
整体而言,这篇论文是对时间序列分析中基础模型的全面回顾和前瞻,旨在为研究人员提供一个清晰的理论框架和实践指南。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅
这篇关于AI论文速读 |【综述】 时序分析基础模型:教程与综述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






