本文主要是介绍【PyTorch实战演练】Faster R-CNN介绍以及通过预训练模型30行代码实现目标检测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0. 前言
- 1. R-CNN的发展史
- 1.1 R-CNN
- 1.2 Fast R-CNN
- 1.3 Faster R-CNN
- 2. 预训练模型
- 3. 目标检测代码及解析
- 4. 结果展示
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文介绍Faster R-CNN的结构及原理,并基于PyTorch官方文档使用预训练好的模型进行目标检测实例。
1. R-CNN的发展史
1.1 R-CNN
R-CNN的提出背景
R-CNN(Regions with Convolutional Neural Network Features)是在目标检测领域具有开创性意义的深度学习模型,由Ross Girshick等人在2014年发表于计算机视觉领域的顶级会议论文 Rich feature hierarchies for accurate object detection and semantic segmentation 中提出。
在当时,尽管卷积神经网络(CNN)已经在图像分类任务上取得了显著进展(例如AlexNet在2012年的ImageNet大规模视觉识别挑战赛ILSVRC上夺冠),但如何将这种成功迁移至更复杂的物体检测任务尚存在挑战。
传统的物体检测方法如滑动窗口或选择性搜索策略在生成候选区域时效率低下,而直接将全卷积网络应用于整个图像会导致计算资源浪费。因此,R-CNN的核心思想是结合区域提议(Region Proposals)方法与深度卷积神经网络来高效地提取和分类候选区域,从而提高了目标检测的准确性和速度。
R-CNN的结构
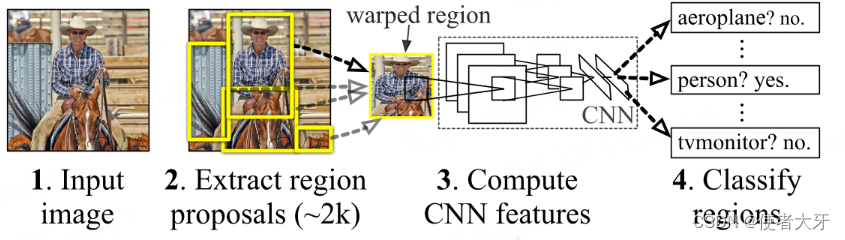
R-CNN的基本流程包括以下四个主要步骤:
- 区域提议(Region Proposals): 利用选择性搜索(Selective Search)算法或其他方法生成一组可能包含目标物体的候选区域;
- 特征提取(Feature Computation): 对每个候选区域裁剪并缩放成固定大小,然后通过预训练的CNN(如AlexNet)提取特征;
- 分类器(Classifier): 将提取的特征输入到支持向量机(SVM)中进行类别分类;
- 边界框回归(Bounding Box Regression): 为了进一步优化预测边界框的位置,引入了一个线性回归模型来微调每个候选框的位置。
R-CNN的优点
- 高精度:R-CNN首次将深度学习应用于目标检测候选区域的特征表示,实现了比传统方法更高的检测精度;
- 可迁移性:利用预训练的CNN,可以有效利用在大规模图像分类任务上预训练的特征表示,提升了模型的泛化能力;
- 模块化设计:通过分离区域提议、特征提取、分类和定位优化四个步骤,使得模型的设计和改进更为灵活;
- 开创性:R-CNN作为早期深度学习目标检测框架,为后续的目标检测算法如Fast R-CNN、Faster R-CNN以及Mask R-CNN等奠定了基础。
然而,尽管R-CNN在目标检测上取得了突破,但它也存在明显的缺点,比如计算效率低,需要对每个候选区域独立运行CNN导致大量重复计算,训练过程复杂等。这些问题在后续的改进版本中得到了逐步解决。
1.2 Fast R-CNN
Fast R-CNN 是在 R-CNN 基础上针对目标检测算法进行改进的一种深度学习模型,由Ross Girshick于2015年论文 Fast R-CNN 中提出,其核心目标是解决R-CNN存在的计算效率低、训练流程繁琐等问题。
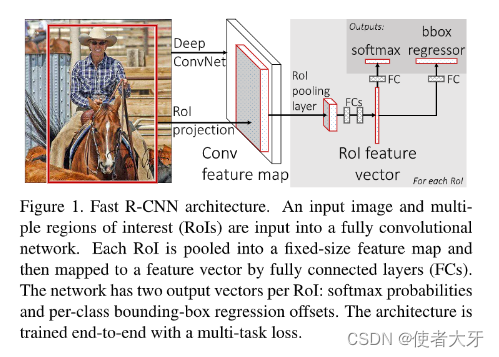
以下是Fast R-CNN相对于R-CNN的主要改进点:
共享卷积特征映射:
- 在R-CNN中,每个候选区域都需要单独通过卷积神经网络进行前向传播以提取特征,这导致了大量的计算冗余。
- Fast R-CNN则首先在整个输入图像上进行一次卷积操作,产生一个全局共享的特征图。所有候选区域(RoIs, Regions of Interest)都在这个特征图上进行操作,极大地减少了计算量。
RoI池化层(RoI Pooling Layer):
- 引入了RoI Pooling层,用于处理不同尺寸和比例的候选区域。它将每个候选区域映射到一个固定尺寸的小区域上,确保特征可以统一输入到全连接层进行分类和位置回归。
- 这个层允许模型在不丢失重要信息的情况下对不同大小的目标进行标准化处理,简化了后续的分类和定位工作。
针对RoI,我此前写过一篇专题介绍文章:【PyTorch实战演练】Fast R-CNN中的RoI(Region of Interest)池化详解
端到端训练:
- R-CNN的训练过程涉及多个独立阶段,包括预训练CNN、训练SVM分类器和边框回归器。
- Fast R-CNN整合了分类和定位回归的任务,构建了一个单一的多任务损失函数,使模型可以进行端到端(end-to-end)训练,简化了训练流程,提高了训练效率和准确性。
Fast R-CNN通过一系列关键创新优化了R-CNN的架构和训练流程,不仅大幅提升了检测速度,还保持并提高了检测质量,为后续目标检测算法Faster R-CNN的发展奠定了基础。
1.3 Faster R-CNN
Faster R-CNN是在Fast R-CNN的基础上进一步优化设计的,旨在再进一步提高检测速度的同时保持高精度。Fast R-CNN虽然解决了R-CNN的一些低效问题,但候选区域(Region Proposal)的生成依然依赖于Selective Search这样的外部算法,这在计算上较为耗时。
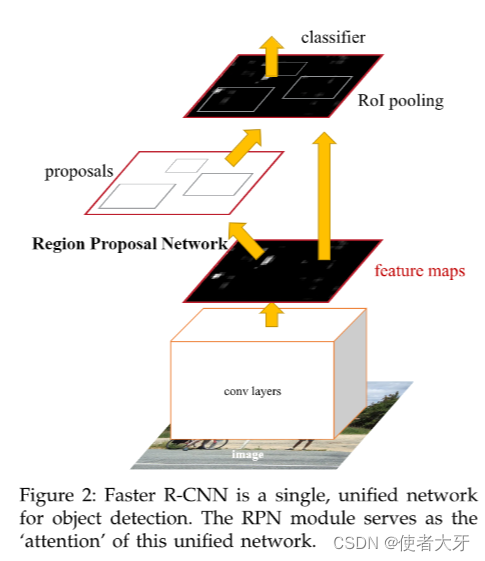
Faster R-CNN对Fast R-CNN所做的关键改进在于引入了一个新的组件——区域提议网络(Region Proposal Network, RPN):
- Faster R-CNN直接在网络内部实现候选区域的生成,通过共享卷积特征图的方式,RPN可以在一张特征图上滑动窗口,并应用小型卷积网络预测每个位置的潜在目标边界框以及每个边界框是否包含对象的概率。
- RPN可以同时生成多个不同尺度和比例的锚框(Anchor Boxes),并通过训练学习如何调整这些锚框以适应不同大小和形状的目标物体。
Faster R-CNN的主要贡献在于通过内建的RPN实现了候选区域提议的高效生成,并且通过共享特征、联合训练等策略整合成了一个更为流畅且高效的端到端目标检测框架,极大地提升了目标检测的速度和准确性。
针对RPN,我也写过一篇专题介绍文章:【PyTorch实战演练】RPN(Region Proposal Networks)候选区域网络算法解析(附PyTorch代码)
最终,超进化完全体的Faster R-CNN结构原理图如下:
2. 预训练模型
预训练模型(Pretrained Models)是指那些已经在大规模公开数据集(如ImageNet对计算机视觉,或者Wikipedia和其他大型文本集合对NLP)上训练好的深度学习模型。这些模型已经学习到了丰富的特征表示,可以用来作为基础模型,为新的但相关性较小的数据集或任务提供初始权重。
预训练模型的优势在于它们极大地减少了从头开始训练所需的时间和资源,并且往往能取得非常出色的性能表现,尤其是在训练数据有限的情况下。
PyTorch中的torchvision.models子模块提供了丰富的搭建好的模型及预训练完成后的权重。本文将直接使用PyTorch官网文档提供的Faster R-CNN示例代码来完成目标检测任务。
3. 目标检测代码及解析
本文创建一个基于PyTorch实现的Faster R-CNN检测模型,使用ResNet-50作为骨干网络,并结合了Feature Pyramid Network (FPN) 架构,其代码及解析如下:
其中英文注释为PyTorch官网带的注释,中文注释为作者增加的说明。
from torchvision.io.image import read_image
from torchvision.models.detection import fasterrcnn_resnet50_fpn_v2, FasterRCNN_ResNet50_FPN_V2_Weights
from torchvision.utils import draw_bounding_boxes
from torchvision.transforms.functional import to_pil_imageimg = read_image("street.jpg")# Step 1: Initialize model with the best available weights
weights = FasterRCNN_ResNet50_FPN_V2_Weights.DEFAULT #权重文件会自动下载到默认文件夹下,例如:C:\Users\XXXXX\.cache\torch\hub\checkpoints
model = fasterrcnn_resnet50_fpn_v2(weights=weights, box_score_thresh=0.9) #只有当边界框所包含对象的预测得分大于 box_score_thresh 时,才会被保留下来进入后续的步骤,进而生成最终的检测结果。
model.eval()# Step 2: Initialize the inference transforms
preprocess = weights.transforms() #FasterRCNN_ResNet50_FPN_V2_Weights类中定义了变换方式 transforms=ObjectDetection# Step 3: Apply inference preprocessing transforms
batch = [preprocess(img)] #用于批量对原图进行transforms# Step 4: Use the model and visualize the prediction
prediction = model(batch)[0]
labels = [weights.meta["categories"][i] for i in prediction["labels"]]
box = draw_bounding_boxes(img, boxes=prediction["boxes"], #直接调用画bounding_box的工具类labels=labels,colors="red",width=4, font_size=30)
im = to_pil_image(box.detach())
im.show()
这里也附出关键类fasterrcnn_resnet50_fpn_v2以及其中的ObjectDetection的PyTorch源代码:
fasterrcnn_resnet50_fpn_v2类:
class FasterRCNN_ResNet50_FPN_V2_Weights(WeightsEnum):COCO_V1 = Weights(url="https://download.pytorch.org/models/fasterrcnn_resnet50_fpn_v2_coco-dd69338a.pth",transforms=ObjectDetection,meta={**_COMMON_META,"num_params": 43712278,"recipe": "https://github.com/pytorch/vision/pull/5763","_metrics": {"COCO-val2017": {"box_map": 46.7,}},"_ops": 280.371,"_file_size": 167.104,"_docs": """These weights were produced using an enhanced training recipe to boost the model accuracy.""",},)DEFAULT = COCO_V1
ObjectDetection类:
class ObjectDetection(nn.Module):def forward(self, img: Tensor) -> Tensor:if not isinstance(img, Tensor):img = F.pil_to_tensor(img)return F.convert_image_dtype(img, torch.float)def __repr__(self) -> str:return self.__class__.__name__ + "()"def describe(self) -> str:return ("Accepts ``PIL.Image``, batched ``(B, C, H, W)`` and single ``(C, H, W)`` image ``torch.Tensor`` objects. ""The images are rescaled to ``[0.0, 1.0]``.")
4. 结果展示
以下是图片的验证实例:
这些“原图”都是由Midjourney生成



最终我们可以看出,本文虽然直接搬运了PyTorch的预训练权重,没有进行任何额外的训练,但是这个测试结果已经很不错了,可见预训可以节省多么巨大的工作量!
这篇关于【PyTorch实战演练】Faster R-CNN介绍以及通过预训练模型30行代码实现目标检测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






