本文主要是介绍融合创新!全局注意力+局部注意力,训练成本直降91.6%,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
全局注意力结合局部注意力可以让模型在处理数据时,既不会丢失重要的局部细节,也能考虑到整个数据集中的全局结构,从而在保持模型计算效率的同时,提高模型的表达能力。
这种策略相较于传统的单一注意力机制,能够更全面地理解输入数据,同时捕捉长距离依赖关系和细节信息。对于论文er来说,是个可发挥空间大、可挖掘创新点多的研究方向。
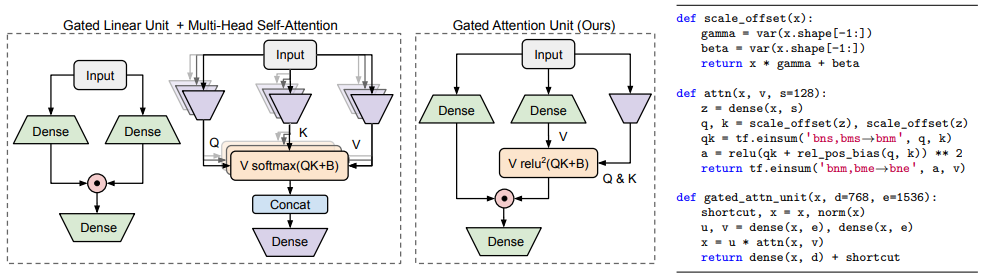
以谷歌Quoc Le团队的FLASH模型为例:
FLASH是一种解决现有高效Transformer变体质量和经验速度问题的实用解决方案。它通过以下方式实现全局注意力和局部注意力的结合:
分块混合注意力(Mixed Chunk Attention):FLASH模型采用了一种分块的策略,将输入数据分成多个块,并在每个块内部进行局部注意力计算。这样可以捕捉到每个数据块内部的详细信息,同时减少整体的计算量。
全局注意力单元(GAU):FLASH模型使用了全局注意力单元(GAU),这是将门控线性单元(GLU)和注意力机制结合起来的一种结构。GAU的设计允许模型在处理数据时考虑到更广泛的上下文信息,从而实现全局注意力的效果。
FLASH首次不仅在质量上与完全增强的 Transformer相当,而且在现代加速器的上下文大小上真正享有线性可扩展性,训练成本仅有原版1/12。
本文分享全局注意力+局部注意力8种结合创新方案,有最新的也有经典的,可借鉴的方法和创新点我做了简单介绍,原文以及相应代码都整理了,方便同学们学习。
论文和代码需要的同学看文末
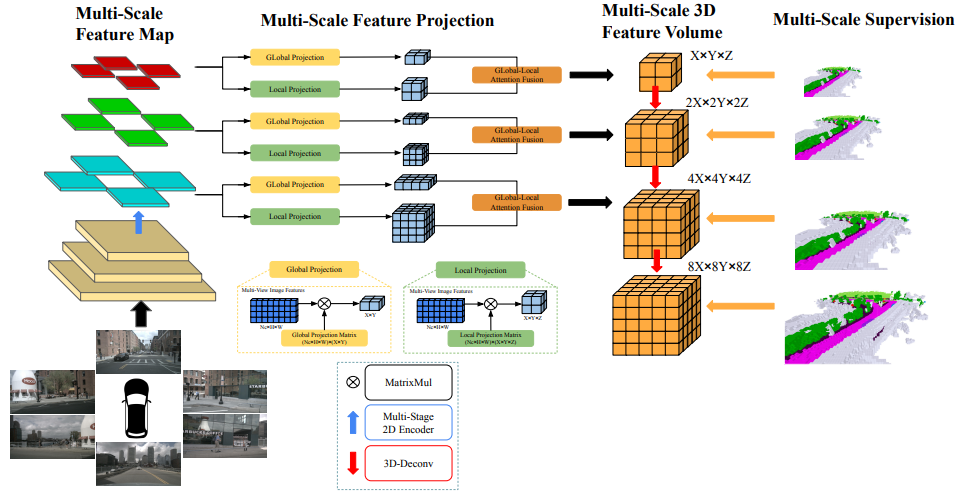
InverseMatrixVT3D: An Efficient Projection Matrix-Based Approach for 3D Occupancy Prediction
方法:论文介绍了一种名为InverseMatrixVT3D的方法,用于将多视图图像特征转换为三维特征体,以进行三维语义占用预测。该方法利用两个投影矩阵存储静态映射关系,并利用矩阵乘法高效地生成全局鸟瞰特征和局部三维特征体。通过在多视图图像特征图和投影矩阵之间进行矩阵乘法,生成三维特征体和鸟瞰特征。通过全局局部融合模块将这两种特征融合在一起,得到最终的三维特征体。
创新点:
-
提出了基于投影矩阵的方法来构建局部的3D特征体积和全局的鸟瞰图特征。
-
提出了全局局部融合模块,将全局的鸟瞰图特征和局部的3D特征体积结合起来,得到最终的3D体积。
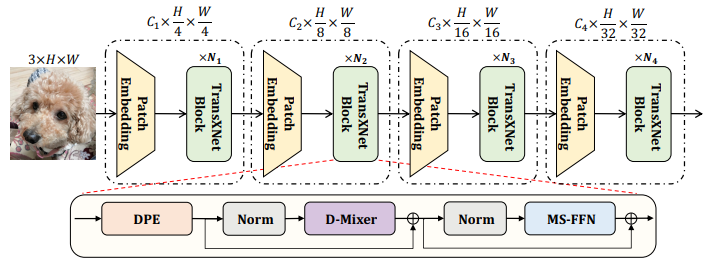
TransXNet: Learning Both Global and Local Dynamics with a Dual Dynamic Token Mixer for Visual Recognition
方法:论文提出了一种名为D-Mixer的新型令牌混合器,以输入相关的方式聚合稀疏的全局信息和局部细节,产生大的有效感受野和强大的归纳偏差。作者通过将D-Mixer作为令牌混合器,还设计了一种名为TransXNet的新型强大视觉骨干网络。
创新点:
-
提出了一种高效的双动态令牌混合器(D-Mixer),利用重叠空间缩减注意力(OSRA)和输入依赖深度卷积(IDConv)提供的混合特征提取。通过将基于D-Mixer的块堆叠到深度网络中,利用先前块中收集的局部和全局信息动态生成IDConv中的卷积核和OSRA中的注意力矩阵,通过融合强归纳偏差和扩展有效感受野,使网络具备更强的表示能力。
-
设计了一种名为TransXNet的新型混合CNN-Transformer网络,通过交替使用D-Mixer和MS-FFN构建。
-
一个网络应该具有较大的感受野和归纳偏差,以捕捉丰富的上下文信息。为了实现较大的感受野,应该在网络的所有阶段中封装一个高效的全局自注意机制。作者还发现将动态卷积与全局自注意相结合可以进一步扩大感受野。
Twins: Revisiting the Design of Spatial Attention in Vision Transformers
方法:提出了两种新的视觉变压器架构,即Twins-PCPVT和Twins-SVT。研究发现,全局子采样注意力在PVT中非常有效,并且在应用合适的位置编码时,其性能可以与甚至优于最先进的视觉变压器(如Swin)相媲美。
作者还提出了一种设计精巧但简单的空间注意力机制,使得这些架构比PVT更高效。该注意力机制受到广泛使用的可分离深度卷积的启发,因此被命名为空间可分离自注意力(SSSA)。Twins-PCPVT和Twins-SVT中的注意力操作都是高效且易于实现的。
创新点:
-
全局子采样注意力(GSA):GSA是一种高效的全局自注意力机制,用于处理远距离和全局信息。它通过在每个局部注意力块之后添加额外的标准全局自注意力层实现,从而实现了跨组信息交换。
-
空间可分离自注意力(SSSA):SSSA是一种精心设计但简单的空间注意力机制,通过模仿广泛使用的分离式深度卷积实现。SSSA由两种类型的注意力操作组成:(i)局部分组自注意力(LSA),用于捕获细粒度和短距离信息;(ii)全局子采样注意力(GSA),用于处理远距离和全局信息。
-
Twins-PCPVT:Twins-PCPVT是第一个提出的视觉Transformer架构。它利用全局子采样注意力(GSA)和适用的位置编码,实现了与最先进的视觉Transformer(如Swin)相媲美甚至更好的性能。

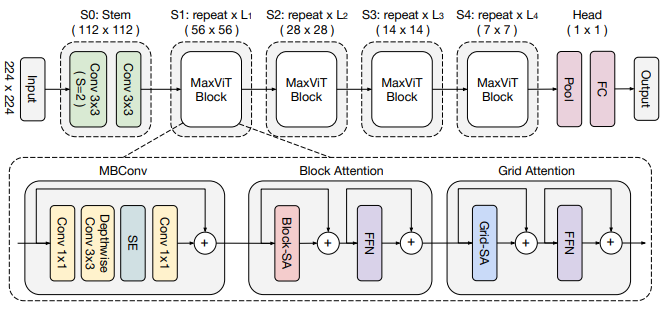
MaxViT: Multi-Axis Vision Transformer
方法:论文引入一种名为Multi-axis Vision Transformer (MaxViT)的视觉模型,该模型能够在整个网络的浅层到深层阶段都实现全局和局部感知,并在各种视觉任务中取得卓越的性能。
创新点:
-
Max-SA:一种新型的Transformer模块,能够在单个块中同时执行局部和全局空间交互,与完整的自注意力相比,提供了更大的灵活性和效率。
-
多轴注意力:一种多轴方法,通过分解空间轴将完整大小的注意力分解为两个稀疏形式(局部和全局),允许以线性复杂度进行局部和全局交互。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“全局局部”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏
这篇关于融合创新!全局注意力+局部注意力,训练成本直降91.6%的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






