本文主要是介绍【AutoML】一个用于图像、文本、时间序列和表格数据的AutoML,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一个用于图像、文本、时间序列和表格数据的AutoML
- AutoGluon介绍
- 安装AutoGluon
- 快速上手
- 参考资料
AutoGluon自动化机器学习任务,使您能够在应用程序中轻松实现强大的预测性能。只需几行代码就可以训练和部署有关图像,文本,时间序列和表格数据的高准确机器学习以及深度学习模型。
项目地址:https://github.com/autogluon/autogluon
本文中的代码使用Google colab实现。
AutoGluon介绍
AutoGluon: AutoML for Image, Text, Time Series, and Tabular Data
主要特点:
- 快速原型制作:用几行代码在原始数据上构建机器学习解决方案。
- 最先进的技术:无需专业知识即可自动利用SOTA模型。
- 易于部署:从实验到生产云预测因子和预建装容器。
- 可自定义:可扩展使用自定义功能处理,模型和指标。
快速上手:
pip install autogluon
安装AutoGluon
对于Linux操作环境,如果有GPU,则执行如下:
pip install -U pip
pip install -U setuptools wheel# Install the proper version of PyTorch following https://pytorch.org/get-started/locally/
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 --index-url https://download.pytorch.org/whl/cu118pip install autogluon
快速上手
在本教程中将看到如何使用AutoGluon的TabularPredictor来预测基于表格数据集中其他列的目标列的值。
首先确保已安装AutoGluon,然后导入Autogluon的TabulardataTaset和Tabular Pressixor。我们将使用前者加载数据和后者来训练模型并做出预测。
!python -m pip install --upgrade pip
!python -m pip install autogluon
加载TabulardataTaset和Tabular Pressixor:
from autogluon.tabular import TabularDataset, TabularPredictor
(1)示例数据
在本教程中将使用《自然》杂志第7887期封面故事中的数据集:人工智能引导的数学定理直觉。我们的目标是根据knot(绳结)的特性来预测它的特征。我们从原始数据中抽取了10K 训练和5K 测试的样本。采样的数据集使本教程快速运行,但是如果需要,AutoGluon 可以处理完整的数据集。
直接从URL加载此数据集。Autogluon的Tabulardataset是Pandas DataFrame的一个子类,因此也可以在TabulardatAset上使用任何Dataframe方法。
data_url = 'https://raw.githubusercontent.com/mli/ag-docs/main/knot_theory/'
train_data = TabularDataset(f'{data_url}train.csv')
train_data.head()

我们的目标存储在“signature”列中,该列有18个独特的整数。即使pandas没有正确地将此数据类型识别为分类,Autogluon也会解决此问题。
label = 'signature'
train_data[label].describe()
count 10000.000000
mean -0.022000
std 3.025166
min -12.000000
25% -2.000000
50% 0.000000
75% 2.000000
max 12.000000
Name: signature, dtype: float64
(2)训练
现在,我们通过指定“signature”列名称,然后在数据集上使用TagularPredictor.fit()在数据集上进行训练。我们不需要指定任何其他参数。Autogluon将认识到这是一项多类分类任务,执行自动功能工程,训练多个模型,然后将模型集成以创建最终预测器。
predictor = TabularPredictor(label=label).fit(train_data)
执行过程如下:
No path specified. Models will be saved in: "AutogluonModels/ag-20240326_144222"
No presets specified! To achieve strong results with AutoGluon, it is recommended to use the available presets.Recommended Presets (For more details refer to https://auto.gluon.ai/stable/tutorials/tabular/tabular-essentials.html#presets):presets='best_quality' : Maximize accuracy. Default time_limit=3600.presets='high_quality' : Strong accuracy with fast inference speed. Default time_limit=3600.presets='good_quality' : Good accuracy with very fast inference speed. Default time_limit=3600.presets='medium_quality' : Fast training time, ideal for initial prototyping.
Beginning AutoGluon training ...
AutoGluon will save models to "AutogluonModels/ag-20240326_144222"
=================== System Info ===================
AutoGluon Version: 1.0.0
Python Version: 3.10.12
Operating System: Linux
Platform Machine: x86_64
Platform Version: #1 SMP PREEMPT_DYNAMIC Sat Nov 18 15:31:17 UTC 2023
CPU Count: 2
Memory Avail: 11.26 GB / 12.67 GB (88.9%)
Disk Space Avail: 41.86 GB / 78.19 GB (53.5%)
===================================================
Train Data Rows: 10000
Train Data Columns: 18
Label Column: signature
AutoGluon infers your prediction problem is: 'multiclass' (because dtype of label-column == int, but few unique label-values observed).First 10 (of 13) unique label values: [-2, 0, 2, -8, 4, -4, -6, 8, 6, 10]If 'multiclass' is not the correct problem_type, please manually specify the problem_type parameter during predictor init (You may specify problem_type as one of: ['binary', 'multiclass', 'regression'])
Problem Type: multiclass
Preprocessing data ...
Warning: Some classes in the training set have fewer than 10 examples. AutoGluon will only keep 9 out of 13 classes for training and will not try to predict the rare classes. To keep more classes, increase the number of datapoints from these rare classes in the training data or reduce label_count_threshold.
Fraction of data from classes with at least 10 examples that will be kept for training models: 0.9984
Train Data Class Count: 9
Using Feature Generators to preprocess the data ...
Fitting AutoMLPipelineFeatureGenerator...Available Memory: 11534.85 MBTrain Data (Original) Memory Usage: 1.37 MB (0.0% of available memory)Inferring data type of each feature based on column values. Set feature_metadata_in to manually specify special dtypes of the features.Stage 1 Generators:Fitting AsTypeFeatureGenerator...Note: Converting 5 features to boolean dtype as they only contain 2 unique values.Stage 2 Generators:Fitting FillNaFeatureGenerator...Stage 3 Generators:Fitting IdentityFeatureGenerator...Stage 4 Generators:Fitting DropUniqueFeatureGenerator...Stage 5 Generators:Fitting DropDuplicatesFeatureGenerator...Useless Original Features (Count: 1): ['Symmetry_D8']These features carry no predictive signal and should be manually investigated.This is typically a feature which has the same value for all rows.These features do not need to be present at inference time.Types of features in original data (raw dtype, special dtypes):('float', []) : 14 | ['chern_simons', 'cusp_volume', 'injectivity_radius', 'longitudinal_translation', 'meridinal_translation_imag', ...]('int', []) : 3 | ['Unnamed: 0', 'hyperbolic_adjoint_torsion_degree', 'hyperbolic_torsion_degree']Types of features in processed data (raw dtype, special dtypes):('float', []) : 9 | ['chern_simons', 'cusp_volume', 'injectivity_radius', 'longitudinal_translation', 'meridinal_translation_imag', ...]('int', []) : 3 | ['Unnamed: 0', 'hyperbolic_adjoint_torsion_degree', 'hyperbolic_torsion_degree']('int', ['bool']) : 5 | ['Symmetry_0', 'Symmetry_D3', 'Symmetry_D4', 'Symmetry_D6', 'Symmetry_Z/2 + Z/2']0.1s = Fit runtime17 features in original data used to generate 17 features in processed data.Train Data (Processed) Memory Usage: 0.96 MB (0.0% of available memory)
Data preprocessing and feature engineering runtime = 0.2s ...
AutoGluon will gauge predictive performance using evaluation metric: 'accuracy'To change this, specify the eval_metric parameter of Predictor()
Automatically generating train/validation split with holdout_frac=0.1, Train Rows: 8985, Val Rows: 999
User-specified model hyperparameters to be fit:
{'NN_TORCH': {},'GBM': [{'extra_trees': True, 'ag_args': {'name_suffix': 'XT'}}, {}, 'GBMLarge'],'CAT': {},'XGB': {},'FASTAI': {},'RF': [{'criterion': 'gini', 'ag_args': {'name_suffix': 'Gini', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'entropy', 'ag_args': {'name_suffix': 'Entr', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'squared_error', 'ag_args': {'name_suffix': 'MSE', 'problem_types': ['regression', 'quantile']}}],'XT': [{'criterion': 'gini', 'ag_args': {'name_suffix': 'Gini', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'entropy', 'ag_args': {'name_suffix': 'Entr', 'problem_types': ['binary', 'multiclass']}}, {'criterion': 'squared_error', 'ag_args': {'name_suffix': 'MSE', 'problem_types': ['regression', 'quantile']}}],'KNN': [{'weights': 'uniform', 'ag_args': {'name_suffix': 'Unif'}}, {'weights': 'distance', 'ag_args': {'name_suffix': 'Dist'}}],
}
Fitting 13 L1 models ...
Fitting model: KNeighborsUnif ...0.2232 = Validation score (accuracy)0.06s = Training runtime0.02s = Validation runtime
Fitting model: KNeighborsDist ...0.2132 = Validation score (accuracy)0.04s = Training runtime0.02s = Validation runtime
Fitting model: NeuralNetFastAI ...0.9459 = Validation score (accuracy)21.81s = Training runtime0.02s = Validation runtime
Fitting model: LightGBMXT ...0.9459 = Validation score (accuracy)8.91s = Training runtime0.21s = Validation runtime
Fitting model: LightGBM ...0.956 = Validation score (accuracy)6.37s = Training runtime0.12s = Validation runtime
Fitting model: RandomForestGini ...0.9449 = Validation score (accuracy)5.6s = Training runtime0.09s = Validation runtime
Fitting model: RandomForestEntr ...0.9499 = Validation score (accuracy)6.36s = Training runtime0.1s = Validation runtime
Fitting model: CatBoost ...0.956 = Validation score (accuracy)57.69s = Training runtime0.01s = Validation runtime
Fitting model: ExtraTreesGini ...0.9469 = Validation score (accuracy)2.16s = Training runtime0.11s = Validation runtime
Fitting model: ExtraTreesEntr ...0.9429 = Validation score (accuracy)2.06s = Training runtime0.16s = Validation runtime
Fitting model: XGBoost ...0.957 = Validation score (accuracy)11.36s = Training runtime0.36s = Validation runtime
Fitting model: NeuralNetTorch ...0.9409 = Validation score (accuracy)41.09s = Training runtime0.01s = Validation runtime
Fitting model: LightGBMLarge ...0.9499 = Validation score (accuracy)12.24s = Training runtime0.33s = Validation runtime
Fitting model: WeightedEnsemble_L2 ...Ensemble Weights: {'NeuralNetFastAI': 0.22, 'RandomForestEntr': 0.22, 'ExtraTreesGini': 0.171, 'KNeighborsUnif': 0.122, 'RandomForestGini': 0.073, 'XGBoost': 0.073, 'LightGBMXT': 0.049, 'NeuralNetTorch': 0.049, 'LightGBMLarge': 0.024}0.966 = Validation score (accuracy)1.05s = Training runtime0.0s = Validation runtime
AutoGluon training complete, total runtime = 181.72s ... Best model: "WeightedEnsemble_L2"
TabularPredictor saved. To load, use: predictor = TabularPredictor.load("AutogluonModels/ag-20240326_144222")
根据CPU型号模型拟合应花费几分钟或更短的时间。可以通过指定time_limit参数来更快地进行训练。例如,fit(..., time_limit=60)将在60秒后停止训练。较高的时间限制通常会导致更好的预测性能,并且过度较低的时间限制将阻止AutoGluon训练并结合一组合理的模型。
(3)预测
一旦有一个适合训练数据集的predictor,就可以加载一组数据集以用于预测和评估。
test_data = TabularDataset(f'{data_url}test.csv')y_pred = predictor.predict(test_data.drop(columns=[label]))
y_pred.head()
执行结果:
Loaded data from: https://raw.githubusercontent.com/mli/ag-docs/main/knot_theory/test.csv | Columns = 19 / 19 | Rows = 5000 -> 5000
0 -4
1 0
2 0
3 4
4 2
Name: signature, dtype: int64
(4)评估
我们可以使用evaluate()函数在测试数据集上评估predictor,该函数测量predictor在未用于拟合模型的数据上的表现。
predictor.evaluate(test_data, silent=True)
执行结果:
{'accuracy': 0.9462,'balanced_accuracy': 0.7437099196728706,'mcc': 0.9340692878044228}
Autogluon的TabularPredictor还提供了leaderboard()函数,这使我们能够评估每个经过训练的模型在测试数据上的性能。
predictor.leaderboard(test_data)
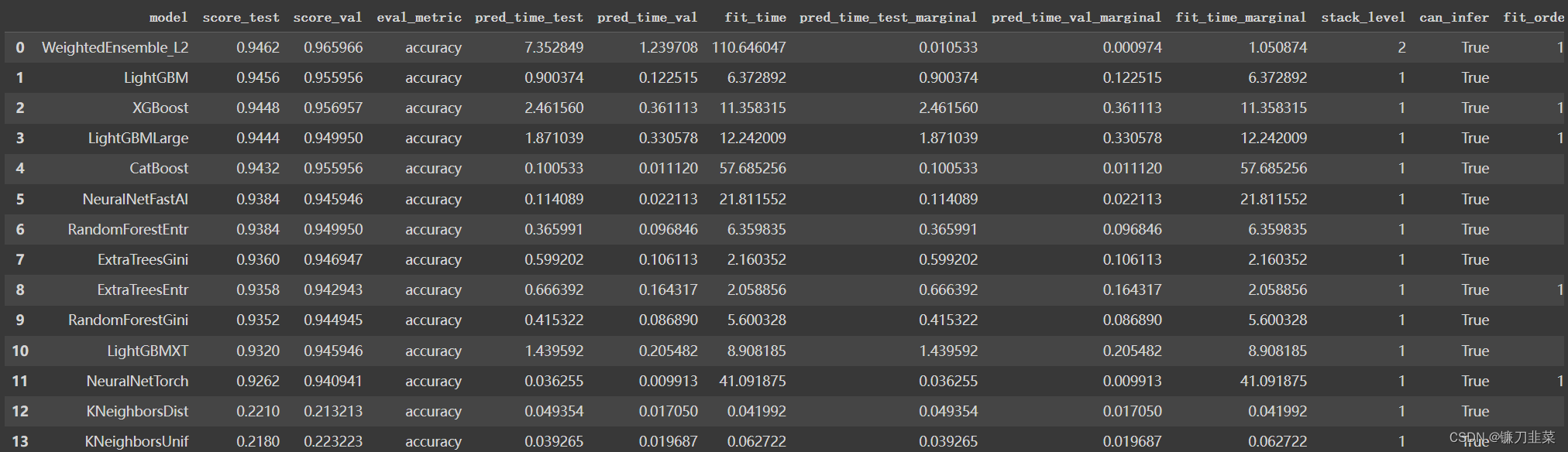
(5)结论
在此教程中,我们看到了Autogluon的基本拟合度,并使用TabularDataset和TabularPredictor预测功能。Autogluon通过不需要特征工程或模型超参数调整来简化模型训练过程。
参考资料
- AutoGluon GitHub Repo: https://github.com/autogluon/autogluon
- AutoGluon 官方文档:https://auto.gluon.ai/stable/index.html
- AutoGluon Quick Start: https://colab.research.google.com/github/autogluon/autogluon/blob/stable/docs/tutorials/tabular/tabular-quick-start.ipynb#scrollTo=EQlCXX50IvBp
这篇关于【AutoML】一个用于图像、文本、时间序列和表格数据的AutoML的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





