本文主要是介绍分类算法-NB(NaiveBeyesian Classification)分类器及AUC效果评估,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在整个机器学习领域,有很多算法,除了与业务相关的推荐算法,还有分类,回归,聚类算法。其实,回归算法中也有类似分类算法,回归算法在机器学习中就是为了解决分类问题。
至于这个分类模型有什么用,我们在机器学习过程中:
定义一个对象X,将其划分到定义的某个类别Y中,输出是某个类别,例如新闻类,军事类
这里分类我们说一下,分类中有二分类(邮件垃圾邮件)、多分类(网页分类),那么分类算法解决的流程是什么:
例如:新闻分类
-
特征表示:X={昨日,投资,市场。。。。。。}
-
特征选择:X={国内,投资,市场}
-
模型选择:朴素贝叶斯分类器
-
训练数据准备
-
模型训练
-
预测(分类)
-
评估
在机器学习中,一般我们会有训练集和测试集,这里我们只是简单说明一下,因为后续代码中需要用到,那么为什么要有这个训练集和测试集,是为了检验模型效果的一个泛化能力,能够达到举一反三的效果,在机器学习中,我们是依靠对学习器的泛化误差进行评估的方法来选择学习器。具体方法如下:我们需要从训练集数据中产出学习器,再用测试集来测试所得学习器对新样本的判别能力,以测试集上的测试误差作为泛化误差的近似,来选取学习器。
通常我们假设训练集、测试集都是从样本集中独立同分布采样得到,且测试集、训练集中的样本应该尽可能互斥(测试集中的样本尽量不在训练集中有出现、尽量不在训练过程中被使用)
测试样本为什么要尽可能不出现在训练集中呢?好比老师出了10道练习题给大家做,考试时候又用这10道练习题考试,这个考试成绩显然“过于乐观”,不能真实的反映同学的学习情况。我们是希望得到泛化性能强的模型,好比同学做完10道练习题能“举一反三”。
这里我们用到朴素贝叶斯公式,这个主要是解决分类的问题,在这个分类问题上,我们一般还会对这个分类的好坏进行效果的评估,这个评估比较重要,那么我们接下来一个一个看,首先我们看下解决分类问题的朴素贝叶斯。
朴素贝叶斯就是一个公式:
p(yi|X)=p(X|yi)p(yi)/p(X)
P(X):待分类对象自身的概率,可忽略
P(yi):每个类别的先验概率,如P(军事)
P(X|yi):每个类别产生该对象的概率
P(xi|yi):每个类别产生该特征的概率,如P(苹果|科技)
我们来看下推导的过程:

那么我们知道了朴素贝叶斯公式,我们怎么来进行分类呢,也就是说我们要怎么求这个概率,这个过程中,我们首先要知道先验概率和条件概率即知道分子p(X|yi)和p(yi),为什么这里不说p(x)呢,因为这个概率始终是个固定值,可以约去,那么我们来说一下p(X|yi)怎么理解:
例如1:
• 总共训练数据1000篇,其中军事类300篇,科技类240篇,生活类140篇,......
• 军事类新闻中,谷歌出现15篇,投资出现9篇,上涨出现36篇
P(yi)
– p(军事)=0.3, p(科技)=0.24, p(生活)=0.14,......
P(xj|yi)
– P(谷歌|军事)=0.05, P(投资|军事)=0.03, P(上涨|军事)=0.12,......
– P(谷歌|科技)=0.15, P(投资|科技)=0.10, P(上涨|科技)=0.04,......
– P(谷歌|生活)=0.08, P(投资|生活)=0.13, P(上涨|生活)=0.18,......
例如2:
给大家100篇文章,其中50篇是军事、30篇财经、20篇体育
P(y=军事) = 50/100
P(y=财经) = 30/100
P(y=体育) = 20/100
P(X):这篇文章的概率=是一个固定值,可以忽略掉
P(yi|X)≈ P(yi)P(X|yi)
P(X|yi):对于y指定的类别中,出现X的概率
P(xi|yi):对于y指定的类别中,出现x这个词的概率
y=军事,x=军舰
X={军舰、大炮、航母}
P(X|y=军事) = P(x=军舰|y=军事)*P(x=大炮|y=军事)*P(x=航母|y=军事)
前提:独立同分布=》朴素贝叶斯
P(yi|X)≈ P(yi)P(X|yi)
对每一个标签都求对应概率,最大者为该分类
为了完成NB分类问题,我们需要2类参数来支持
1、先验概率P(yi)
2、条件概率P(X|yi)
其实这里所谓的求这类的参数也就是求模型的过程,即参数就是模型。
在这里说明一下,我们在平时代码实现的过程中有两种求解条件概率的计算方法,这两类都可以计算条件概率:
第一种:
分子:军事类文章中包含“谷歌”这个词的文章个数
分母:军事类文章个数
p(x="谷歌"|y="军事"):分子 / 分母
第二种:
分子:军事类文章中包含“谷歌”这个词的个数
分母:军事类文章中所有词的个数
p(x="谷歌"|y="军事"):分子 / 分母
朴素贝叶斯说了这么多,有什么优缺点呢:
优点:简单有效,结果是概率,对二值和多值同样适用
缺点:独立性假设有时不合理
那么我们来看下代码怎么实现的,代码部分注释都已经标示清楚:
这里我们用我们已经知道的好类的文章来做个模拟分析的过程,我们只用三类财经,体育,汽车这三类,来看看机器学习过程中的分类实际情况
词转tokenId的过程,并且得到训练和测试模型的过程
import sys
import os
import randomWordList = []
WordIDDic = {}
#训练阈值
TrainingPercent = 0.8#输入文件夹
inpath = sys.argv[1]
#输出的文件
OutFileName = sys.argv[2]
#输出的文件训练集是OutFileName.train,测试集是:OutFileName.test
trainOutFile = file(OutFileName+".train", "w")
testOutFile = file(OutFileName+".test", "w")def ConvertData():i = 0tag = 0for filename in os.listdir(inpath):#只分析三大类的数据,财经,汽车,体育,并且给每个类别打个标示,财经是1,汽车2,体育3if filename.find("business") != -1:tag = 1elif filename.find("auto") != -1:tag = 2elif filename.find("sport") != -1:tag = 3#统计一共读了多少篇文章i += 1#设置一个随机数,为了下面能够把数据按照二八原则分为训练集和测试集rd = random.random()#把测试集的文件名赋给outfile变量outfile = testOutFile#若随机数小于0.8则把训练集文件名副歌outfile变量,这种操作是为了下面写入数据做准备if rd < TrainingPercent:outfile = trainOutFileif i % 100 == 0:print i,"files processed!\r",#读入目录下的文章内容,inpath是目录地址,filename是目录下的文件名称infile = file(inpath+'/'+filename, 'r')#首先把三类文章的标签写入输出文件开头,后面加空格outfile.write(str(tag)+" ")#一次性全部读入,python中read,readline 不同的读的方式不一样content = infile.read().strip()#进行编码转义content = content.decode("utf-8", 'ignore')#因为一次性读入,所以会有换行的问题,这里直接把换行替换成空格,并且以空格切分开,words是个列表words = content.replace('\n', ' ').split(' ')#循环列表for word in words:if len(word.strip()) < 1:continue'''这里的代码是我觉得写的最好的一段代码,简单又复杂。首先判断这个单词在不在token2Id的字典里面,若不在,将该单词添加到一个wordList列表中然后将该单词存入token2Id的字典里面,key是word,value是wordList列表的长度这个if判断的精华在于利用判断word是否在token2id的字典来进行去重复'''if word not in WordIDDic:WordList.append(word)WordIDDic[word] = len(WordList)#将word对应的id写入输出文件中outfile.write(str(WordIDDic[word])+" ")#最后一篇文章转换完成后,用#号隔开文章名称和内容outfile.write("#"+filename+"\n")infile.close()print i, "files loaded!"print len(WordList), "unique words found!"#首先调用ConvertData()函数
ConvertData()
trainOutFile.close()
testOutFile.close()
朴素贝叶斯的实现过程:
#Usage:
#Training: NB.py 1 TrainingDataFile ModelFile
#Testing: NB.py 0 TestDataFile ModelFile OutFileimport sys
import os
import mathDefaultFreq = 0.1
TrainingDataFile = "nb_data.train"
ModelFile = "nb_data.model"
TestDataFile = "nb_data.test"
TestOutFile = "nb_data.out"
ClassFeaDic = {}#{classid :{自增长id:计数器}}
ClassFreq = {}#频次 classid下token的总数
WordDic = {} #token字典
ClassFeaProb = {} #条件概率字典
ClassDefaultProb = {} #默认概率字典 默认概率分母与条件概率分母一致
ClassProb = {} #先验概率字典def Dedup(items):tempDic = {}for item in items:if item not in tempDic:tempDic[item] = Truereturn tempDic.keys()#加载数据,初始化
def LoadData():i =0#读入训练集infile = file(TrainingDataFile, 'r')#以行的方式读入,在上次的Data处理中已经转换成每一行的内容,首先读入一行sline = infile.readline().strip()#判断该文件是否有内容,循环所有的训练集while len(sline) > 0:#找到没行的#号和文章名,输出是个索引index数字pos = sline.find("#")if pos > 0:#取出从该篇文章开始到#号的位置sline = sline[:pos].strip()#将取出的文章内容以空格分割开words = sline.split(' ')#判断文章有么有问题if len(words) < 1:print "Format error!"break#得到刚刚那三类文章的tag即财经是1,汽车2,体育3 赋给classidclassid = int(words[0])#判断这类型文章在不在文章字典里面,不在进入if,在进行频次+1,为了求先验概率if classid not in ClassFeaDic:#给当前的classid定义一个字典放入ClassFeaDic字典里面,即ClassFeaDic的输出就是{'classid':{}}ClassFeaDic[classid] = {}ClassFeaProb[classid] = {}#给当前的classid记录频次放入频次几点里面ClassFreq[classid] = 0ClassFreq[classid] += 1#获取除了文章标签的真正内容words = words[1:]#remove duplicate words, binary distribution#words = Dedup(words)#循环内容for word in words:if len(word) < 1:continue#获取每个词,这里词是我们转置的数字wid = int(word)#判断当前的词在不在词语字典里面,不在初始化为1if wid not in WordDic:WordDic[wid] = 1#若当前词在该词的字典里面,紧接着判断当前词在不在当前classid文章中的字典里面,不在初始化为1,在的话记录频次if wid not in ClassFeaDic[classid]:ClassFeaDic[classid][wid] = 1else:ClassFeaDic[classid][wid] += 1#记录读的总行数i += 1#接着再读入一行知道结束sline = infile.readline().strip()infile.close()print i, "instances loaded!"print len(ClassFreq), "classes!", len(WordDic), "words!"#计算模型
def ComputeModel():sum = 0.0#循环遍历不同类文章记录的字典的value值,key是classid value是该类对应的频次for freq in ClassFreq.values():#sum将所有的value相加即得到三类文章的总的篇幅数sum += freq#循环遍历不同类文章记录的字典的key值,key是classid value是该类对应的频次for classid in ClassFreq.keys():#当前classid对应的先验概率,用体育举例子,体育类文章篇幅数除以总的篇幅数,循环计算三类文章各个先验概率ClassProb[classid] = (float)(ClassFreq[classid])/(float)(sum)#循环遍历每类文章中每个词频的字典中的key,key是classid,value是个字典{词:词频}for classid in ClassFeaDic.keys():#Multinomial Distributionsum = 0.0#循环遍历当前classid对应的value字典{词:词频},中的key即词for wid in ClassFeaDic[classid].keys():#统计当前类文章的词频次数sum += ClassFeaDic[classid][wid]#newsum = (float)(sum+len(WordDic)*DefaultFreq)#为了使程序健壮,防止向下溢出,这里可以把sum+1newsum = (float)(sum + 1)#Binary Distribution#newsum = (float)(ClassFreq[classid]+2*DefaultFreq)#循环遍历当前类文章的的key即词for wid in ClassFeaDic[classid].keys():#存入条件概率值,用体育举例子,体育文章中铅球的条件概率=铅球在体育文章中的总数/体育文章的总词数ClassFeaProb[classid][wid] = (float)(ClassFeaDic[classid][wid]+DefaultFreq)/newsum#每一类文章设置一个默认的条件概率,防止在测试集时候一个词在当前类文章没有,就用该值ClassDefaultProb[classid] = (float)(DefaultFreq) / newsumreturn'''
训练模型数据输出格式: 共四行.第一行 classid 先验概率 默认概率 第二行属于class_A tokenid 条件概率 tokenid 条件概率 tokenid 条件概率 第三行属于class_B tokenid 条件概率 tokenid 条件概率 tokenid 条件概率 第四行属于class_C tokenid 条件概率 tokenid 条件概率 tokenid 条件概率
'''
def SaveModel():#以写的方式打开该类文件outfile = file(ModelFile, 'w')#循环遍历类别频次字典,获取三大类别的classidfor classid in ClassFreq.keys():#将classid写入文件outfile.write(str(classid))outfile.write(' ')#将获取的先验概率写入文件outfile.write(str(ClassProb[classid]))outfile.write(' ')#将默认的每类别条件概率写入文件outfile.write(str(ClassDefaultProb[classid]))outfile.write(' ' )#第一行遍历3类文章对应的不同概率,然后换行outfile.write('\n')#循环遍历每个类别对应的词和词频的字典,key是classid,value是{词:词频}for classid in ClassFeaDic.keys():#循环value的key即词for wid in ClassFeaDic[classid].keys():#将获得的词用来获取该词的条件概率outfile.write(str(wid)+' '+str(ClassFeaProb[classid][wid]))outfile.write(' ')#每一类的文章模型为一行outfile.write('\n')outfile.close()#加载模型
def LoadModel():global WordDicWordDic = {}global ClassFeaProbClassFeaProb = {}global ClassDefaultProbClassDefaultProb = {}global ClassProbClassProb = {}#读入模型infile = file(ModelFile, 'r')sline = infile.readline().strip()#每篇文章以空格分割开items = sline.split(' ')if len(items) < 6:print "Model format error!"returni = 0while i < len(items):#获取每类文章的tagclassid = int(items[i])#定义一个字典ClassFeaProb[classid] = {}#将i+1i += 1if i >= len(items):print "Model format error!"return#存放先验概率ClassProb[classid] = float(items[i])#i+1接下来是默认的条件概率i += 1if i >= len(items):print "Model format error!"return#存放默认的条件概率ClassDefaultProb[classid] = float(items[i])#i+1 接下来就是另外一个类别的文章i += 1#循环遍历条件概率的key,key是不同类别的文章classidfor classid in ClassProb.keys():#接下来读入第二行数据,就是某一类文章的某个词的条件概率sline = infile.readline().strip()#以空格分割开items = sline.split(' ')i = 0#循环遍历while i < len(items):#获取该词的条件概率wid = int(items[i])#判断在不在词字典里,不再初始化if wid not in WordDic:WordDic[wid] = 1#若在将i+1i += 1if i >= len(items):print "Model format error!"return#并且给当前文章类的该词字典中赋上条件概率ClassFeaProb[classid][wid] = float(items[i])#接下来循环第二个词,以此类推i += 1infile.close()print len(ClassProb), "classes!", len(WordDic), "words!"def Predict():global WordDicglobal ClassFeaProbglobal ClassDefaultProbglobal ClassProbTrueLabelList = []PredLabelList = []i =0#读入测试集infile = file(TestDataFile, 'r')outfile = file(TestOutFile, 'w')#以每行读入,这里是每篇文章以及文章中的词sline = infile.readline().strip()scoreDic = {}iline = 0while len(sline) > 0:#上来将iline+1,是为了从第二个开始,第一是文章标示的tagiline += 1if iline % 10 == 0:print iline," lines finished!\r",#这块和前面的一样,掠过#后面的文件名称pos = sline.find("#")if pos > 0:sline = sline[:pos].strip()#将文章的内容进行以空格切分开words = sline.split(' ')if len(words) < 1:print "Format error!"break#获取当前文章类别classid = int(words[0])#将类别添加到标签list中TrueLabelList.append(classid)#内容从1开始知道最后words = words[1:]#remove duplicate words, binary distribution#words = Dedup(words)#循环遍历每个类别的先验概率,放入scoreDic字典中for classid in ClassProb.keys():scoreDic[classid] = math.log(ClassProb[classid])#循环内容for word in words:if len(word) < 1:continuewid = int(word)#过滤掉一些没有的词if wid not in WordDic:#print "OOV word:",widcontinue#循环遍历当前类别的先验概率for classid in ClassProb.keys():#判断当前词存不存在条件概率的字典中,若不存在,直接取默认的条件概率,否则取出条件概率if wid not in ClassFeaProb[classid]:# 如果当前分类中不包含这个分词,就算出一个默认概率 p(x1|y) +p(x2|y) +p(x3|y) == p(军舰|军事) +p(大炮|军事)scoreDic[classid] += math.log(ClassDefaultProb[classid])else:scoreDic[classid] += math.log(ClassFeaProb[classid][wid])#binary distribution#wid = 1#while wid < len(WordDic)+1:# if str(wid) in words:# wid += 1# continue# for classid in ClassProb.keys():# if wid not in ClassFeaProb[classid]:# scoreDic[classid] += math.log(1-ClassDefaultProb[classid])# else:# scoreDic[classid] += math.log(1-ClassFeaProb[classid][wid])# wid += 1i += 1#取出最大的概率maxProb = max(scoreDic.values())#并且循环分数字典for classid in scoreDic.keys():if scoreDic[classid] == maxProb:PredLabelList.append(classid)sline = infile.readline().strip()infile.close()outfile.close()print len(PredLabelList),len(TrueLabelList)return TrueLabelList,PredLabelList
#计算准确率
def Evaluate(TrueList, PredList):accuracy = 0i = 0while i < len(TrueList):if TrueList[i] == PredList[i]:accuracy += 1i += 1accuracy = (float)(accuracy)/(float)(len(TrueList))print "Accuracy:",accuracy
'''计算精确率和召回率:精确率:针对军事分类, 预测军事成功的个数/预测为军事的总数召回率:针对军事分类, 预测军事成功的个数/实际军事类文章的个数
'''
def CalPreRec(TrueList,PredList,classid):correctNum = 0allNum = 0predNum = 0i = 0while i < len(TrueList):if TrueList[i] == classid:allNum += 1if PredList[i] == TrueList[i]:correctNum += 1if PredList[i] == classid:predNum += 1i += 1return (float)(correctNum)/(float)(predNum),(float)(correctNum)/(float)(allNum)#main framework
'''代码执行的主要部分判断输入参数,是训练集还是测试集,当然,我们拿到数据首先进行训练,然后进行测试,最后的出结果那么我们一个一个来看下
'''
if len(sys.argv) < 4:print "Usage incorrect!"
#当参数是1的时候进入训练集
elif sys.argv[1] == '1':print "start training:"TrainingDataFile = sys.argv[2] # 训练数据 tag 自增长的id 自增长的idModelFile = sys.argv[3] # model模型数据输出文件LoadData() # ClassFeaDic = {}#{classid :{自增长id:计数器}} ClassFreq = {}#频次 classid下token的总数ComputeModel() # 计算先验概率ClassProb 和条件概率 ClassFeaProbSaveModel()
#模型训练完成,开始进行测试
elif sys.argv[1] == '0':print "start testing:"TestDataFile = sys.argv[2]ModelFile = sys.argv[3]TestOutFile = sys.argv[4]LoadModel()#通过测试集与模型计算,获得classid和每篇文章的分类结果TList,PList = Predict()i = 0outfile = file(TestOutFile, 'w')#循环取出每篇文章以及对应的分类while i < len(TList):outfile.write(str(TList[i]))outfile.write(' ')outfile.write(str(PList[i]))outfile.write('\n')i += 1outfile.close()Evaluate(TList,PList)for classid in ClassProb.keys():pre,rec = CalPreRec(TList, PList,classid)print "Precision and recall for Class",classid,":",pre,rec
else:print "Usage incorrect!"
既然我们已经求解出分类的概率,接下来,我们看下评测这个重点的问题,我们用什么来进行评测呢,用一个叫混淆矩阵的方式来进行评测
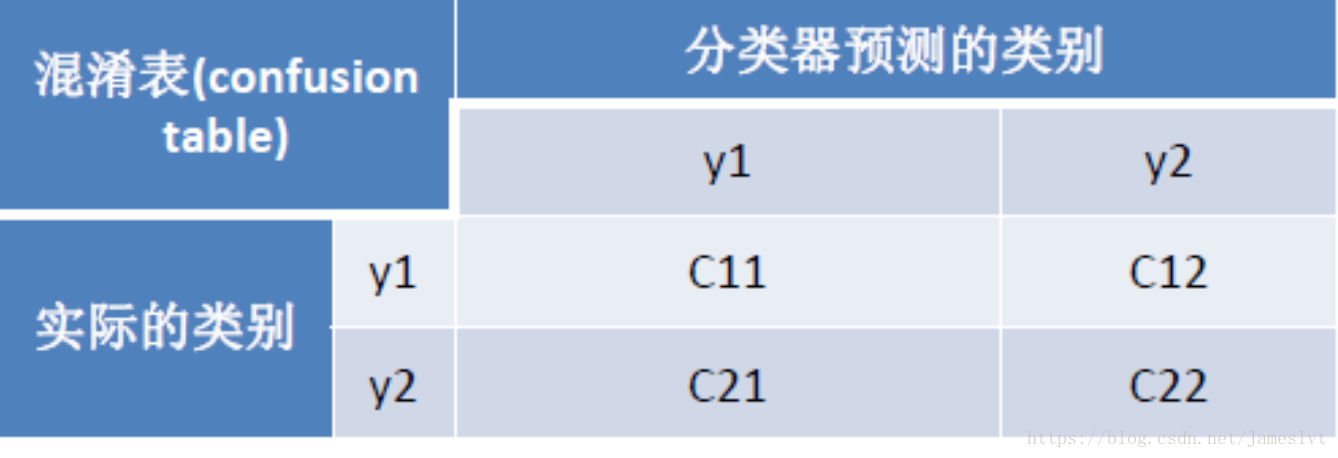
准确度Accuracy:(C11+C22)/(C11+C12+C21+C22)
精确率Precision(y1):C11/(C11+C21)
召回率Recall(y1):C11/(C11+C12)
这种方式不好看,我们来替换成例子来看下:
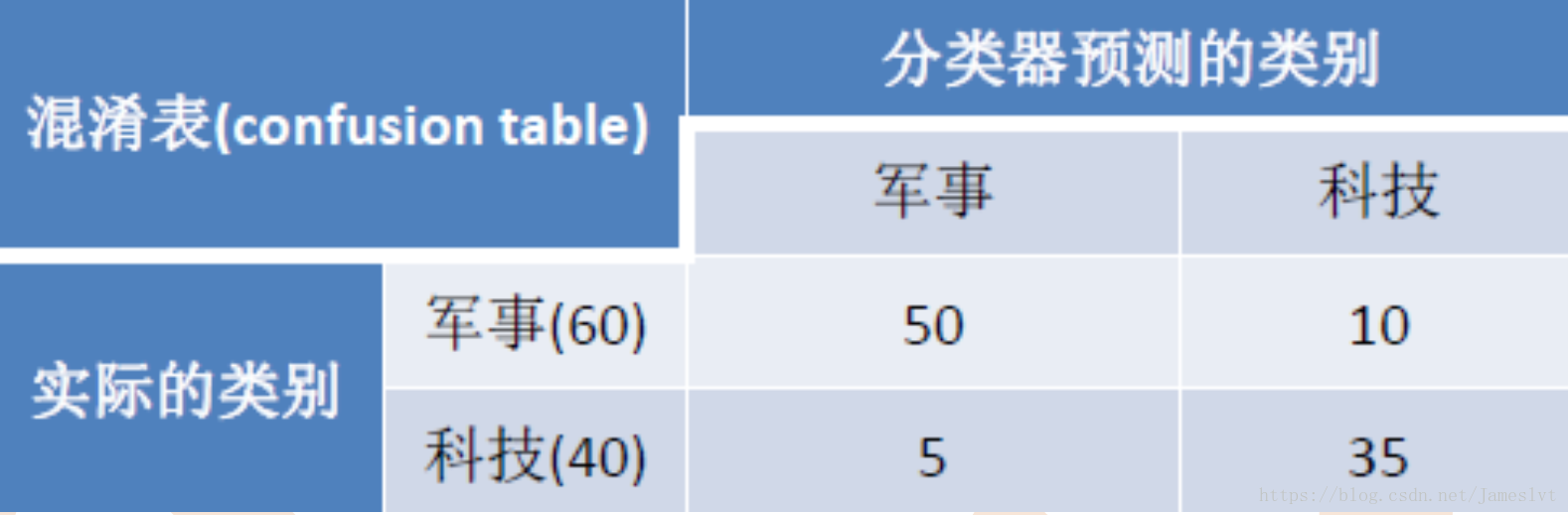
准确度Accuracy:(50+35)/(35+5+10+50)=85%
精确率Precision(y1):50/(50+5)=90.9%
召回率Recall(y1):50/(50+10)=83.3%
上面的例子很明确,我们说一下评测的指标,正确率和召回率:
正确率:预测样本中,正确的样本所占的比例,即看军事列
召回率:预测样本中,正确的样本占同一类别总的样本比例,看军事行
那么什么指标合适,在日常生活中,有的是侧重于召回,有的是侧重于正确率,越靠近底层一般越侧重于召回,越往上,越侧重于精确即Nosq库那块侧重召回,排序模型那里侧重于精确
有了这个正确率和召回率,我们可以获得一个PR曲线,即:同时评估正确率和召回率的方法就是通过PR曲线,p代表正确率,R代表召回率但是这个PR曲线很容构造成一个高正确率或高召回率的曲线,很难保证两全齐美,一般准确率高,召回率就低,召回率高,准确率低,可以构成一个二维码坐标,纵坐标是正确率,横坐标是召回率
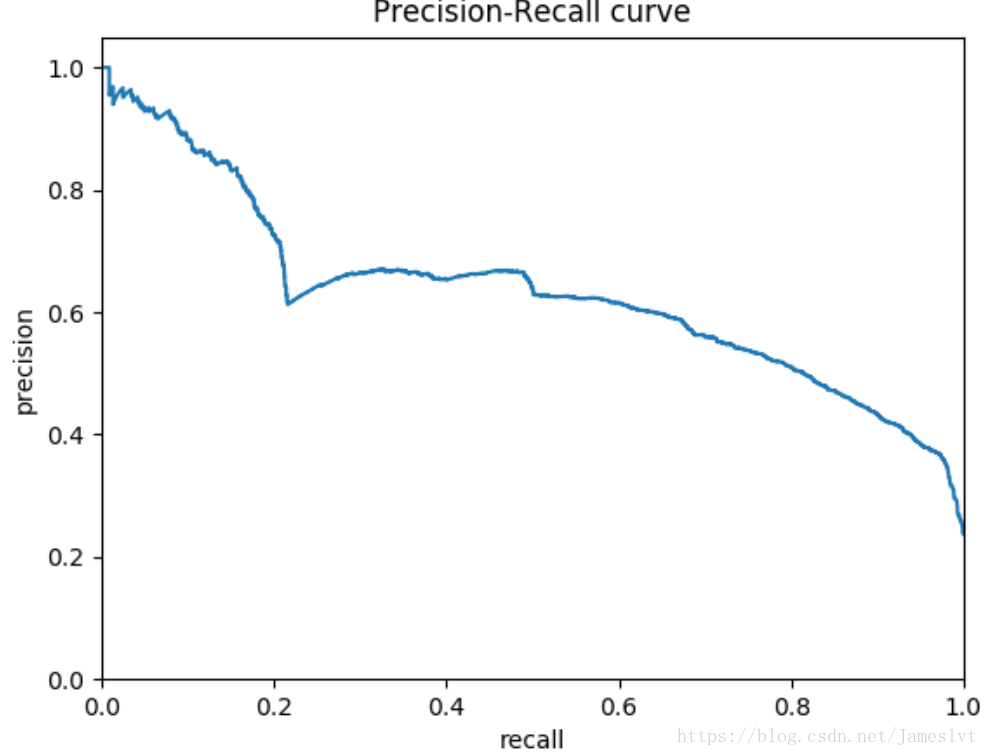
那么用生活中的两类场景来举例子:
-
搜索场景,保证召回的前提下,再提高准确率
-
疾病检测,保证准确性前提,提升召回
PR曲线是个评测指标,用来协助你去选择阀值的,那么我们看下ROC曲线的评测指标

纵轴:真阳率,召回率,TP/(TP+FN) 横轴:假阳率FP/(FP+FN)
那么ROC曲线有什么用,其实ROC曲线是为了得到AUC曲线,即ROC曲线下的面积
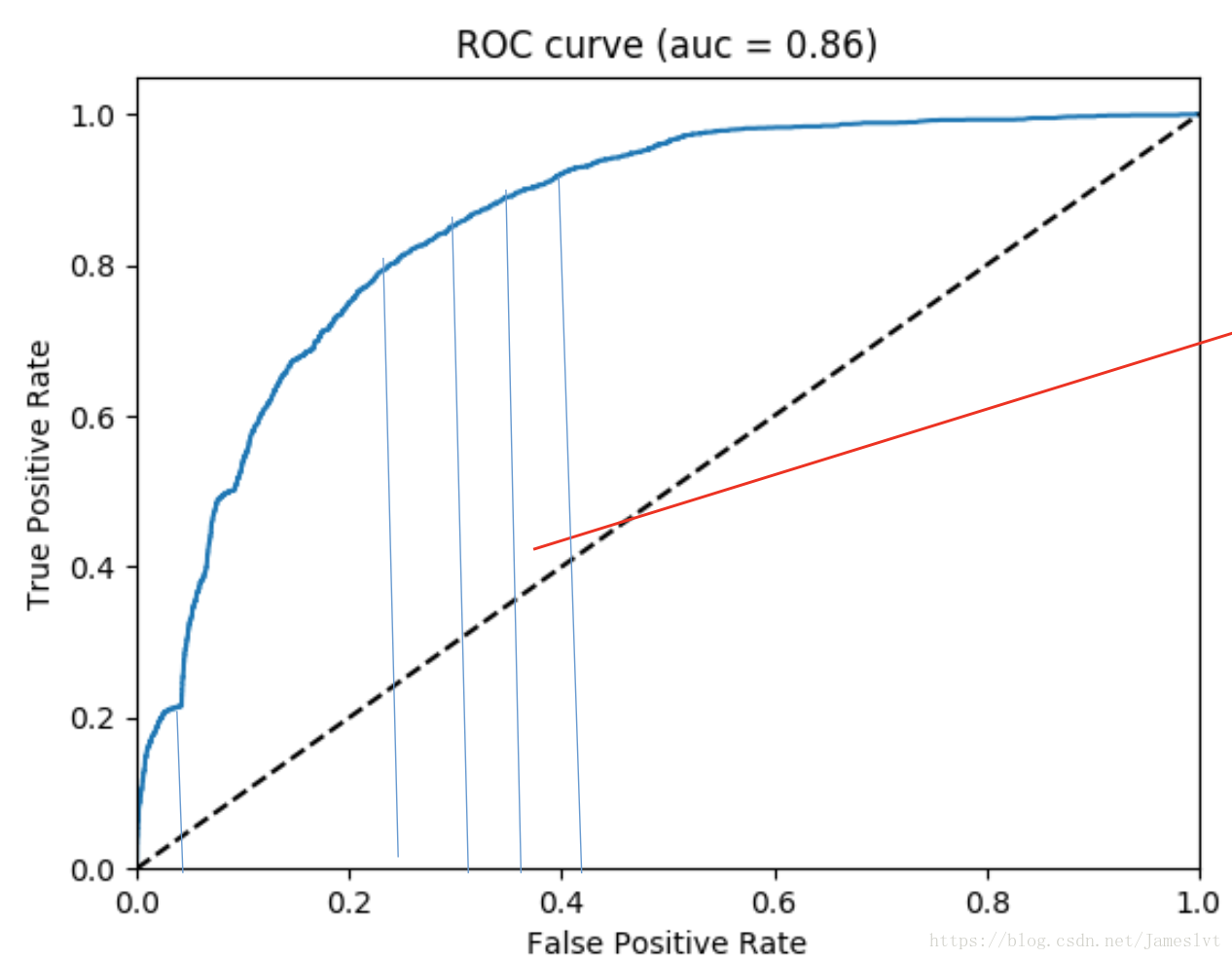

但是这样计算比较麻烦,我们可以利用其他方式去理解AUC,即负样本排在正样本前面的概率,假如A 0.1 B 0.9 我们假设负样本排正样本前面的概率认为正确,即A在B前面,认为是一次正确,B排在A前面,认为是一次错误。我们可以通过一个AWK来计算
cat auc.raw | sort -t$'\t' -k2g |awk -F'\t' '($1==-1){++x;a+=y;}($1==1){++y;}END{print 1.0-a/(x*y);}'
x*y是正负样本pair对,a代表错误的个数,a/x*y 错误的概率,1-a/x*y 正确概率
解释一下这个linux命令,按照第二个模型打的分数进行循环判断,小的排在前面,大的分数排在后面,当有的分数是比较小,但是不是该类的,这个a就加一个y,y从0开始加,直到结束,能够找到有多少a,进而计算评估的正确率
例如:来了个文章,我们假如是军事类为+1,财经为-1,当然这个文章是军事类文章,即+1,然后我们设置一个阀值为0,即分类预测的分数 >0 认为是+1,<=0 认为是-1,x是负样本的个数,y是所有正样本个数,a是错误的样本个数
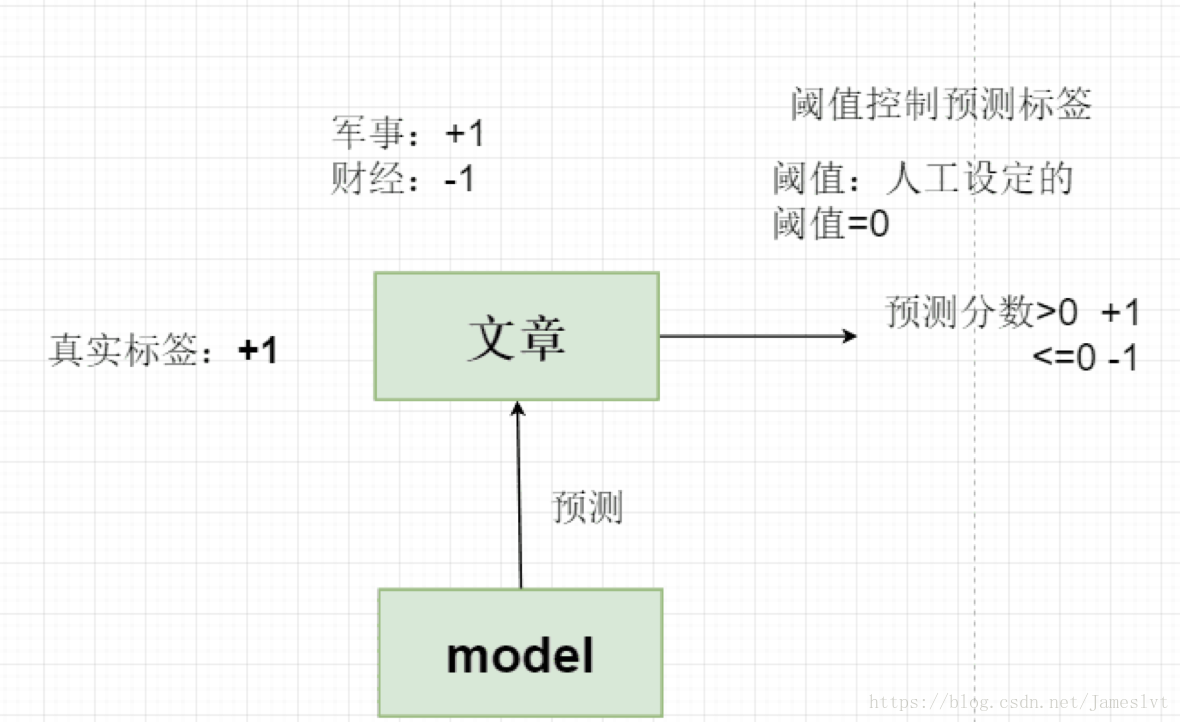
那么这个最差就是0.5,压根不知道好坏,评测是到底是正确的评测还是错误的评测。最完美就是1或者0了
这篇关于分类算法-NB(NaiveBeyesian Classification)分类器及AUC效果评估的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









