本文主要是介绍政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(六)—— 二元分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: TensorFlow与Keras机器学习实战演绎
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
这篇文章咱们将深度学习应用到另一个常见任务中。
前言
在深度学习中,二元分类是一种常见的任务,旨在将输入数据分为两个类别之一。这两个类别可以是任意两个互斥的类别,例如“正面”和“负面”,“真”和“假”,或者任何其他可以用于区分数据的两个标签。
二元分类问题的目标是训练一个模型,使其能够根据输入数据的特征来预测其所属的类别。深度学习通过构建深度神经网络来解决这个问题。通常,一个深度神经网络由多个隐藏层组成,每个隐藏层都包含多个神经元。这些神经元通过学习权重和偏差来逐渐调整模型,以最大限度地减少分类错误。
在深度学习中,常用的二元分类算法包括逻辑回归、支持向量机、决策树和随机森林等。这些算法在处理不同类型的数据和任务时表现不同,所以选择适合特定问题的算法是很重要的。
为了训练一个二元分类模型,需要准备一个标记好的训练数据集,其中包含了输入数据和对应的类别标签。然后,将数据输入到深度神经网络中,通过反向传播算法和梯度下降优化算法来调整模型的参数,以使模型能够更好地预测新的未见过的数据样本的类别。
在实际应用中,二元分类可以应用于很多领域,例如情感分析、垃圾邮件过滤、疾病诊断等。通过深度学习的技术,可以提高模型的准确性和泛化能力,使其在复杂的数据集上取得更好的性能。
到目前为止,我们在本系列的文章中已经学习了神经网络如何解决回归问题。现在我们将把神经网络应用到另一个常见的机器学习问题:分类。我们之前学到的大部分内容仍然适用。主要的区别在于我们使用的损失函数以及我们希望最后一层产生什么样的输出。
二元分类
将数据分为两个类别是一种常见的机器学习问题。你可能想预测一个客户是否有可能购买,一笔信用卡交易是否存在欺诈,深空信号是否显示出一颗新行星的证据,或者一项医学测试是否有疾病的证据。这些都是二元分类问题。
在原始数据中,类别可能由字符串表示,例如 "Yes" 和 "No",或者 "Dog" 和 "Cat"。在使用这些数据之前,我们将为其分配一个类别标签:一个类别将被赋值为 0,另一个类别将被赋值为 1。将类别标签分配为数字将使数据能够被神经网络使用。
准确率和交叉熵
准确率是用于衡量分类问题成功程度的众多度量中的一种。准确率是正确预测数与总预测数的比值:准确率 = 正确预测数 / 总预测数。如果一个模型的预测始终正确,其准确率为1.0。其他条件相同的情况下,准确率是一个合理的度量指标,适用于数据集中的类别出现频率相近的情况。
准确率(以及大多数其他分类指标)的问题在于它不能用作损失函数。随机梯度下降(SGD)需要一个变化平滑的损失函数,但准确率作为一个计数比率,变化是“跳跃”的。因此,我们必须选择一个替代物来充当损失函数。这个替代物就是交叉熵函数。
现在,回想一下,损失函数定义了网络在训练过程中的目标。在回归中,我们的目标是最小化预期结果和预测结果之间的距离。我们选择了MAE来衡量这个距离。
对于分类任务,我们所希望的是概率之间的距离,而交叉熵提供了这种距离。交叉熵是一种衡量从一个概率分布到另一个概率分布的距离的方法。
(交叉熵对错误的概率预测进行惩罚。)

这个想法是我们希望我们的网络能以概率1.0预测出正确的类别。预测概率距离1.0越远,交叉熵损失就越大。
我们使用交叉熵的技术原因有点微妙,但从本节中要记住的主要事情就是:
对于分类损失,请使用交叉熵;
您可能关心的其他指标(如准确性)往往也会随之改善。
使用Sigmoid函数生成概率
交叉熵和准确率函数都需要概率作为输入,也就是0到1之间的数字。为了将密集层产生的实值输出转换为概率,我们需要使用一种新的激活函数,即sigmoid激活函数。
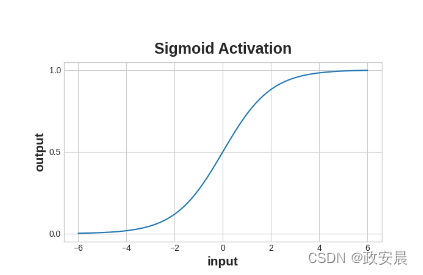
Sigmoid函数将实数映射到区间[0,1]中。
为了得到最终的类别预测,我们定义了一个阈值概率。通常情况下,这个阈值概率是0.5,这样四舍五入就可以给出正确的类别预测:小于0.5表示标签为0的类别,大于等于0.5表示标签为1的类别。0.5阈值是Keras在默认情况下使用的准确度指标。
示例 — 二元分类
让我们尝试下面这个例子:
电离层数据集包含从地球大气层的电离层层面上获取的雷达信号特征。任务是确定信号是否显示出某个物体的存在,还是只是空气。
import pandas as pd
from IPython.display import displayion = pd.read_csv('../input/dl-course-data/ion.csv', index_col=0)
display(ion.head())df = ion.copy()
df['Class'] = df['Class'].map({'good': 0, 'bad': 1})df_train = df.sample(frac=0.7, random_state=0)
df_valid = df.drop(df_train.index)max_ = df_train.max(axis=0)
min_ = df_train.min(axis=0)df_train = (df_train - min_) / (max_ - min_)
df_valid = (df_valid - min_) / (max_ - min_)
df_train.dropna(axis=1, inplace=True) # drop the empty feature in column 2
df_valid.dropna(axis=1, inplace=True)X_train = df_train.drop('Class', axis=1)
X_valid = df_valid.drop('Class', axis=1)
y_train = df_train['Class']
y_valid = df_valid['Class']| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | ... | V26 | V27 | V28 | V29 | V30 | V31 | V32 | V33 | V34 | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 0.99539 | -0.05889 | 0.85243 | 0.02306 | 0.83398 | -0.37708 | 1.00000 | 0.03760 | ... | -0.51171 | 0.41078 | -0.46168 | 0.21266 | -0.34090 | 0.42267 | -0.54487 | 0.18641 | -0.45300 | good |
| 2 | 1 | 0 | 1.00000 | -0.18829 | 0.93035 | -0.36156 | -0.10868 | -0.93597 | 1.00000 | -0.04549 | ... | -0.26569 | -0.20468 | -0.18401 | -0.19040 | -0.11593 | -0.16626 | -0.06288 | -0.13738 | -0.02447 | bad |
| 3 | 1 | 0 | 1.00000 | -0.03365 | 1.00000 | 0.00485 | 1.00000 | -0.12062 | 0.88965 | 0.01198 | ... | -0.40220 | 0.58984 | -0.22145 | 0.43100 | -0.17365 | 0.60436 | -0.24180 | 0.56045 | -0.38238 | good |
| 4 | 1 | 0 | 1.00000 | -0.45161 | 1.00000 | 1.00000 | 0.71216 | -1.00000 | 0.00000 | 0.00000 | ... | 0.90695 | 0.51613 | 1.00000 | 1.00000 | -0.20099 | 0.25682 | 1.00000 | -0.32382 | 1.00000 | bad |
| 5 | 1 | 0 | 1.00000 | -0.02401 | 0.94140 | 0.06531 | 0.92106 | -0.23255 | 0.77152 | -0.16399 | ... | -0.65158 | 0.13290 | -0.53206 | 0.02431 | -0.62197 | -0.05707 | -0.59573 | -0.04608 | -0.65697 | good |
我们将和回归任务一样定义我们的模型,只有一个例外。在最后一层中包括一个'sigmoid'激活函数,以便模型能够产生类别概率。
from tensorflow import keras
from tensorflow.keras import layersmodel = keras.Sequential([layers.Dense(4, activation='relu', input_shape=[33]),layers.Dense(4, activation='relu'), layers.Dense(1, activation='sigmoid'),
])将交叉熵损失和准确度度量指标添加到模型中,并使用compile方法。
对于两类问题,请确保使用“binary”版本。(对于更多类别的问题会稍有不同。)Adam优化器在分类问题上效果很好,因此我们将继续使用它。
model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['binary_accuracy'],
)在这个特定问题中,模型可能需要很多个时期来完成训练,因此我们将包含一个提前停止的回调函数以方便操作。
early_stopping = keras.callbacks.EarlyStopping(patience=10,min_delta=0.001,restore_best_weights=True,
)history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=512,epochs=1000,callbacks=[early_stopping],verbose=0, # hide the output because we have so many epochs
)我们将像往常一样查看学习曲线,还会检查在验证集上获得的损失和准确率的最佳值。(请记住,提前停止训练会恢复权重到获得这些值的状态。)
history_df = pd.DataFrame(history.history)
# Start the plot at epoch 5
history_df.loc[5:, ['loss', 'val_loss']].plot()
history_df.loc[5:, ['binary_accuracy', 'val_binary_accuracy']].plot()print(("Best Validation Loss: {:0.4f}" +\"\nBest Validation Accuracy: {:0.4f}")\.format(history_df['val_loss'].min(), history_df['val_binary_accuracy'].max()))
做个练习:二元分类
介绍
在这个练习中,你将使用一个二元分类器来预测酒店取消预订。
# Setup plotting
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
# Set Matplotlib defaults
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',titleweight='bold', titlesize=18, titlepad=10)
plt.rc('animation', html='html5')# Setup feedback system
from learntools.core import binder
binder.bind(globals())
from learntools.deep_learning_intro.ex6 import *首先,加载“酒店取消”数据集。
import pandas as pdfrom sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import make_pipeline
from sklearn.compose import make_column_transformerhotel = pd.read_csv('../input/dl-course-data/hotel.csv')X = hotel.copy()
y = X.pop('is_canceled')X['arrival_date_month'] = \X['arrival_date_month'].map({'January':1, 'February': 2, 'March':3,'April':4, 'May':5, 'June':6, 'July':7,'August':8, 'September':9, 'October':10,'November':11, 'December':12})features_num = ["lead_time", "arrival_date_week_number","arrival_date_day_of_month", "stays_in_weekend_nights","stays_in_week_nights", "adults", "children", "babies","is_repeated_guest", "previous_cancellations","previous_bookings_not_canceled", "required_car_parking_spaces","total_of_special_requests", "adr",
]
features_cat = ["hotel", "arrival_date_month", "meal","market_segment", "distribution_channel","reserved_room_type", "deposit_type", "customer_type",
]transformer_num = make_pipeline(SimpleImputer(strategy="constant"), # there are a few missing valuesStandardScaler(),
)
transformer_cat = make_pipeline(SimpleImputer(strategy="constant", fill_value="NA"),OneHotEncoder(handle_unknown='ignore'),
)preprocessor = make_column_transformer((transformer_num, features_num),(transformer_cat, features_cat),
)# stratify - make sure classes are evenlly represented across splits
X_train, X_valid, y_train, y_valid = \train_test_split(X, y, stratify=y, train_size=0.75)X_train = preprocessor.fit_transform(X_train)
X_valid = preprocessor.transform(X_valid)input_shape = [X_train.shape[1]]1. 定义模型
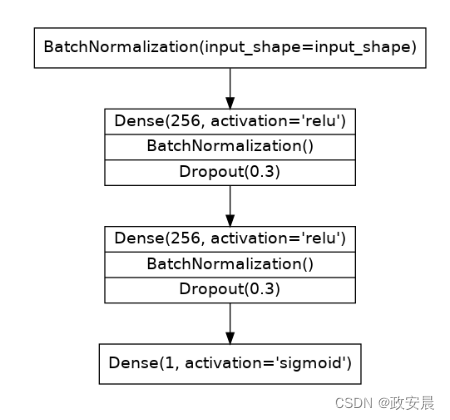
这次我们将使用的模型将包含批量归一化(batch normalization)和丢弃层(dropout)。
为了方便阅读,我们已将图表分成了几个块,但你可以按照通常的方式逐层定义它。
定义一个模型,其架构由以下图表给出:
(二分类器的图示。)
from tensorflow import keras
from tensorflow.keras import layers# YOUR CODE HERE: define the model given in the diagram
model = ____# Check your answer
q_1.check()2. 添加优化器、损失函数和评估指标
现在使用Adam优化器和交叉熵损失函数和准确度指标的二进制版本来编译模型。
# YOUR CODE HERE
____# Check your answer
q_2.check()# Lines below will give you a hint or solution code
#q_2.hint()
#q_2.solution()最后,运行这个单元格来训练模型并查看学习曲线。这可能需要大约60到70个epochs,可能需要一到两分钟。
early_stopping = keras.callbacks.EarlyStopping(patience=5,min_delta=0.001,restore_best_weights=True,
)
history = model.fit(X_train, y_train,validation_data=(X_valid, y_valid),batch_size=512,epochs=200,callbacks=[early_stopping],
)history_df = pd.DataFrame(history.history)
history_df.loc[:, ['loss', 'val_loss']].plot(title="Cross-entropy")
history_df.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot(title="Accuracy")3. 训练和评估
你对学习曲线有什么看法?模型是否欠拟合或过拟合?交叉熵损失是否是准确度的一个很好的替代指标?
结论
恭喜您,这是咱们这个系列的最后一篇文章,如果您都看完了,凭借您的新技能,您可以开始进行更高级的应用了,如计算机视觉和情感分类。您想下一步做什么呢?(呵呵)
本系列总共六篇文章,前五篇分别是:
【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(一)—— 单个神经元
【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(二)—— 深度神经网络
【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(三)—— 随机梯度下降
【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(四)—— 过拟合和欠拟合
【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(五)—— Dropout和批归一化
这篇关于政安晨:【深度学习实践】【使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络】(六)—— 二元分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





