本文主要是介绍Cascaded Zoom-in Detector for High ResolutionAerial Images,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码地址 https://github.com/akhilpm/dronedetectron2
摘要
密集裁剪是一种广泛使用的方法来改进这种小物体检测,其中以高分辨率提取和处理拥挤的小物体区域。然而,这通常是通过添加其他可学习的组件来实现的,从而使标准检测过程中的训练和推理变得复杂。本文中,我们提出了一种高效的级联放大(CZ )检测器,该检测器将检测器本身重新用于密度引导的训练和推理。在训练过程中,密度裁剪物被定位,标记为一个新的类,并用于增强训练数据集。在推理过程中,密度裁剪物首先与基类对象一起被检测,然后被输入用于第二阶段的推理。这种方法很容易集成到任何检测器中,并且不会对标准检测过程产生显著变化,就像航空图像检测中流行的均匀裁剪方法一样。
总结
密集裁剪可以用来改进小物体检测,但是这通常是通过添加其他可学习的组件来实现的。但是,我们提 出了一种高效的级联放大( CZ )检测器,该检测器将检测器本身重新用于密度引导的训练和推理。
1、介绍
航空图像是高分辨率拍摄的,这些物体稀疏地分布在拥挤的物体区域,通常由许多小物体组成。高分辨率图像和微小物体给航空图像中的物体检测带来了一些挑战,包括由于重新缩放和特征下采样导致的信息丢失、对边界框偏移的低容忍度以及噪声特征表示[5 , 8] 等。由于计算成本和大的内存占用,很难将高分辨率航空图像直接输入到检测器,因此通常会将其调整为标准分辨率范围(见图第2 ( a )段)。

(a) 将图像缩放到探测器的尺寸下 。这种重新缩放,再加上 ConvNetx 中的特征下采样,通常会导致与小对象相关的特征表示因噪声背景激活而减少或损坏。关于边界框偏移的容差,边界框中的小偏移可能会导致并集上的交集(IoU )大幅下降,从而增加假阳性检测 [5] 。( 但是这种缩放不好,会导致小对象的 特征丢失 )
为了利用更高的分辨率,并减轻信息损失,一种流行的方法是将输入图像裁剪成均匀的补丁,然后通过上采样对这些补丁进行高分辨率的对象检测(见图2 ( b ))( b) 图像被分割成均匀、可能重叠的补丁, 每个补丁都有检测器处理 。
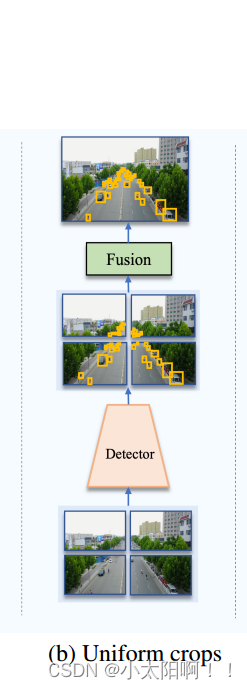
尽管这些均匀的补丁有助于提高精度,但 这种方法不考虑图像中对象的分布,因此实现的尺度归一化不 是最佳的 [17 , 37] 。由于航空图像中的物体通常出现在图像稀疏分布的区域中,因此需要执行基于密度的裁剪,然后处理这些拥挤物体区域的高分辨率版本以获得更好的比例平衡。
为了提取这些密度裁剪,现有的方法利用了额外的可学习模块(见图 2 ( c )),( c) 外部可学习模块将 图像裁剪成密集的对象区域(也就是说只裁剪图像中的密集区域) 。 每种裁剪都会按照探测器的分辨率 重新缩放和处理 。
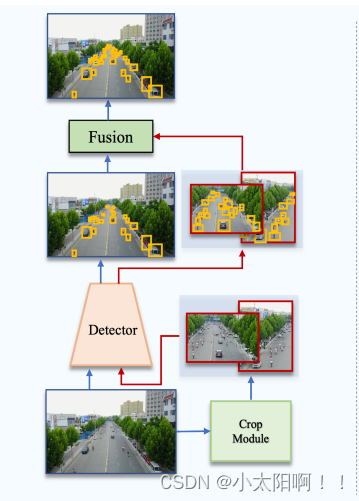
如密度图 [17] 、聚类建议网络 [37] 、全局局部检测管道 [8] 等。这通常会在管道中产生额外的可学习组件,通常需要多个阶段的训练。即使使用单级端到端方法,所获得的裁剪在一开始也是有噪声的,并且仅在训练的后期阶段用于辅助小目标检测[37] 。此外,随着学习的发展,裁剪也在进化,因此该模型没有得到关于什么是“ 密度裁剪 ” 的一致指示。
在这篇论文中, 我们试图通过提出一种高效的级联放大( CZ )检测方法来弥合研究和实践之间的差距, 该方法可以在标准检测器的训练中利用密度裁剪,提供均匀种植的简单性,同时提供密度裁剪的好处 (见图2 ( d ) ) 。 (d) 我们提出的 CZ 检测器被重新用于检测密度作物和基类对象,从而消除了对外部模块的需求(对于密度裁剪区域,我们不用额外的可学习模块了,只用自己的 detector 来对密度裁剪区域进 行 detector )。在 第二阶段的推理 中, 每个裁剪区域都被重新缩放并以检测器的分辨率进行处理。蓝色 箭头表示原始图像的路径,红色箭头表示密度作物的路径。(感觉像是双通道的物体检测器,一条路径 对原始图像进行,一条路径对从原始图片中裁剪到的密集区域进行检测)
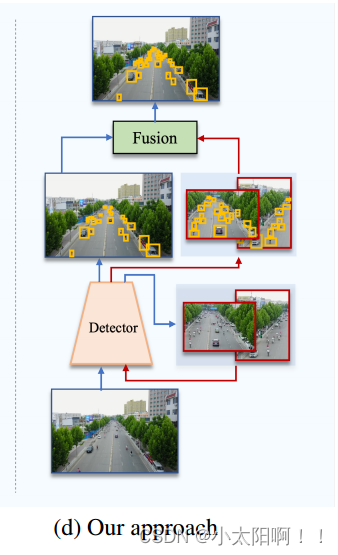
我们只是 简单地利用现有的探测器本身来发现密度作物 , 将 “ 作物 ” 作为一个新的类别添加到探测器中 。 作物被标记为使用作物标记算法的预处理步骤,因此检测器接收到作物组成的一致标志。在推理过程中,虽然其他方法需要复杂的后处理来过滤有噪声的作物,但我们可以简单地根据检测器中 “ 作物 ” 类的 置信度 来执行它。图1 说明了我们的方法的训练和测试。

图示 : 我们提出的级联放大检测器概述。在训练期间(顶部),提取密度作物,并在原始图像上标记为新类(红框)。训练集用重新缩放的密度作物和这些作物中相应的地面实况框来扩充。 在推理的第一阶段(底部),在整个图像上检测基类对象和密度裁剪(红框)。在第二阶段,密度作物被重新缩放到共同的较大尺寸,并执行第二推断。最后,将对密度作物的检测与对整个图像的检测相结合首先,使用我们的作物标记算法,从每个训练图像中提取密度作物作为预处理步骤 。这些 密度裁剪被添 加为要在相应图像中检测的新类别。 然后,我们 用密度作物的更高分辨率版本和作物内物体的相应地面 实况( GT )框来扩充训练集。然后,像往常一样训练探测器。 与标准检测器训练相比,这种训练过程的开销几乎可以忽略不计,并且与基于均匀作物的训练类似。推理分两个阶段进行 。在第一阶段,从每个输入图像中检测基类对象和密度裁剪。并对这些作物的上采样版本执行另一个基于推理的推理。最后,将来自第一阶段和第二阶段的检测融合以获得输出检测。与标准的目标检测器学习相比,训练时需要的 额外工作是作物标记,这可以作为预处理步骤来执行(也就是说在预处理时标记好密度作物) 。 在进行 预测时,所需的额外工作是再进行一次推理 。由于这两个过程都不需要对普通物体检测管道进行任何重大修改,类似于均匀裁剪,我们的方法可以很容易地用于加速小物体检测。
总结
首先,从每个输入图像中检测基类对象和密度裁剪。然后,基于高质量密度作物的置信度分数来选择它们,并对这些作物的上采样版本执行另一个基于推理的推理。最后,将第一阶段和第二阶段的检测结果进行融合,得到输出检测结果。
贡献
针对高分辨率航空图片,提出了一种基于密度裁剪的高效级联放大( CZ )对象检测器,其中给定的检测器被重新用于提取密度裁剪(因此不使用额外的模块)以及基类对象。在训练时,这种方法依赖于密度作为标记的简单预处理步骤,而在测试时,需要额外的推理步骤来处理预测的密度作物。
2、相关工作
由于小物体在高分辨率图像中稀疏位置的密集分布,密度裁剪是航空图像检测中的一种流行策略 [8 , 9 ,17, 37] 。但这通常是通过额外的可学习成分和多阶段训练来实现的,因此,这种方法比均匀种植更复杂。我们也使用密度种植策略,但将检测器本身重新用于提取作物,因此不需要额外的可学习组件。因此,我们相信我们的方法具有均匀裁剪策略的实用简单性,但保留了密度引导检测的优点。
3、提出的方法
介绍如何变换任何探测器,使其能够利用密集作物有效处理许多小物体的高分辨率图像。 我们提出的级 联放大( CZ )对象检测器允许重新调整检测器的用途,以提取密度作物和基类对象 。让我们考虑保持其高分辨率的原始图像、下采样图像和裁剪图像,下采样图像是包含与原始图像相同的视图但缩小到检测器输入分辨率的图像,裁剪图像是放大到检测器分辨率的图像的选定区域。我们流水线的第一个组成部 分是密度裁剪标记算法 ,该 算法将拥挤的对象区域标记为 ” 密度作物 “ 并且通过将这些区域的放大版本相 加来扩充训练数据 。然后, 密度裁剪也被添加到原始图像中,作为要检测的新类别 。因此,增强训练集将包括包含拥挤小物体的区域的高分辨率版本,从而允许检测器以高分辨率看到这些小物体。一旦训练 了模型,推理就包括在原始图像上检测基类和 “ 密度作物 ” 类, 然后 在放大后对预测的密度作物进行第二 次检测。最后,将原始图像的检测和密度裁剪相结合,产生输出检测 。
总结
先用密度裁剪标记算法,将拥挤的对象区域标记为 “ 密度作物 ” 。并且通过将这些区域的放大版本相加来扩充训练数据,密度裁剪的区域也被添加到原始图像中,作为要检测的新类别。
在放大后对密度作物进行第二次检测,最后将原始图像的检测和密度裁剪相结合,产生输出检测。
3.1 密度作物训练
为了在我们的方法中使用标准检测器,我们需要在训练注释中添加一个称为 “ 密度裁剪 ” 的新类 。通过这种方式,我们的方法是检测器不可知的(因为我们不改变检测器的内部结构,所以我们只需向目标类列表中添加一个额外的类),并且不需要检测器本身以外的任何额外组件。密集裁剪类应该标记图像中包含许多小对象的部分,并将它们包含在边界框中。这将允许训练和推理通过以更高的分辨率分析这些部分来关注这些部分。可以考虑不同的方法来定义密度作物。我们用来定义密度作物的质量约束是:
(i) 它们应该包含一组小目标对象
(ii) 它们在推理时很容易定位
(iii) 它们在数量上是最优的,以降低计算成本
算法 1 描述了我们用于 ground truth 注释中发现和标记密度作物的过程。总之,我们对 GT 框进行迭代合并,以发现密度作物。所有GT 框 B通过将框的最小和最大坐标扩展为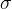 像素来缩放(缩放(
像素来缩放(缩放( ))。然后,我们将O中缩放框(pairwise_IoU(D))之间的成对交集并集(IoU)计算为
))。然后,我们将O中缩放框(pairwise_IoU(D))之间的成对交集并集(IoU)计算为 矩阵。通过在成对IoU矩阵中对阈值
矩阵。通过在成对IoU矩阵中对阈值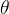 以上 的所有重叠值分配 1 ,连接在 C 中被标
以上 的所有重叠值分配 1 ,连接在 C 中被标
记 。
然后,我们在C中选择具有最大连接数的行 (说明涉及的密集框最多)、通过找到连接到的所有裁剪成员的最小和最大坐标来计算封闭框(enclosing_box(Cm*)。
(说明涉及的密集框最多)、通过找到连接到的所有裁剪成员的最小和最大坐标来计算封闭框(enclosing_box(Cm*)。 
新获得的
裁剪框被添加到裁剪列表中,行Cm*被设置为 0 。随后,从列表 D 中移除大于最大阈值 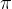 的裁剪
的裁剪  。 该迭代合并过程被执行 N 次。这里使用的裁剪尺寸阈值 是裁剪 面积与图像面积的比率。
。 该迭代合并过程被执行 N 次。这里使用的裁剪尺寸阈值 是裁剪 面积与图像面积的比率。
作物的质量对我们的方法很重要。事实上,正是迭代合并带来了更好质量的作物。根据缩放因子的值,天真的缩放和合并以找到基于成对IoU 的最大封闭框会导致坏的作物太多或太多的小作物(其中的对象较少)。迭代合并产生了高质量的作物 ,包围了符合质量约束的小对象组。我们还证明了该算法的超参数可以很容易地设置。注意,通过预先标记密度作物,我们在整个训练期间为检测器提供了构成“ 密度作物” 的一致信号,这与其他方法不同,在其他方法中,密度作物也在训练过程中进化 [9 , 17 , 37] 。这与[39]中的观察结果一致,即可以在训练期间给出一致的基本事实标签的简单启发式方法优于不断进化的基于复杂预测的基本事实标记。
利用新获得的裁剪标签,我们还可以用额外的图像裁剪来增强训练集 。使用最大训练分辨率 W×H 来缩小原始图像及其注释B 。注意, 预期检测器不会在缩小的图像中检测到许多小物体。但是,给定图像的密集裁剪 的放 大版本将使那些小物体以更高的分辨率落在裁剪内 。作物标记可以作为预处理步 骤执行。密度作物的放大版本增强只是一个数据增强过程。因此,我们的方法不会对标准检测器的训练 管道进行任何更改,除了增加新的类别 “ 密度作物 ” 。
的放 大版本将使那些小物体以更高的分辨率落在裁剪内 。作物标记可以作为预处理步 骤执行。密度作物的放大版本增强只是一个数据增强过程。因此,我们的方法不会对标准检测器的训练 管道进行任何更改,除了增加新的类别 “ 密度作物 ” 。
3.2多阶段推理
由于检测器被训练来识别密度作物,因此在推断时,我们可以从其预测本身获得密度作物 。图 1 底部详细解释了我们的推理过程。它由两个阶段组成。在第一阶段,它预测输入图片上的基类和密度裁剪,然后 我们根据它们的置信度分数来选择高质量的密度作物 。在第二阶段, 放大的密度作物再次通过同一个检 测器,对密度作物进行小物体检测。 最后,我们 将作物上的检测重新投影到原始图像,并将它们与原始 图像上的检测连接起来。设 是由其在原始图像中的边界框坐标
是由其在原始图像中的边界框坐标 定义的大小为
定义的大小为 的放大裁剪图像。给定缩放因子
的放大裁剪图像。给定缩放因子 ,重投影 pi 按比例缩小并将其裁剪 c 中的检测
,重投影 pi 按比例缩小并将其裁剪 c 中的检测 
盒 移位为:
移位为:
然后应用非最大抑制( NMS )来去除重复检测。
虽然其他方法需要复杂的后处理来过滤有噪声的作物 [37] ,但我们可以简单地使用密度作物的置信度得分来进行同样的处理(我们可以应用密度作物的置信度得分来去除重复检测 )。推理的第一阶段是任何检测器中的标准推理过程。利用检测器给出的置信度分数可以容易地执行对噪声作物的滤波。推理的第二阶段使用相同的检测器,但使用不同的输入(按比例放大的密度作物)。因此,我们只是再次重复检测器的标准推理程序。所有这些操作都可以很容易地封装在任何检测器的推理过程之上,从而在推理时
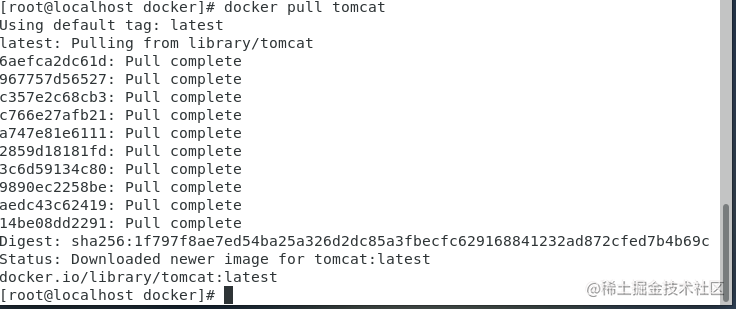
4、实验
python train_net.py --num-gpus 1 --config-file "D:\Project\DroneDetectron2-main\configs\Base
RCNN-FPN.yaml" OUTPUT_DIR outputs_FPN_VisDrone
也保持了统一裁剪方法的简单性。 这篇关于Cascaded Zoom-in Detector for High ResolutionAerial Images的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]Single Shot Text Detector with Regional Atterntion](https://img-blog.csdn.net/20171130092242746?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMzI1MDQxNg==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/Center)

