本文主要是介绍【Intel校企合作课程】猫狗大战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1:作业简介:猫狗大战
1.1问题描述:
1.2预期解决方案:
1.3数据集
2:数据预处理
2.1数据集结构
2.2探索性数据分析
2.3提取数据集
2.4数据增强
3:使用卷积神经网络识别猫狗图像
3.1VGG-16架构
3.3卷积神经网络
3.3深度神经网络
3.4更改VGG-16网络结构
4:在CPU上训练
4.1参数设置
4.2在intel云平台CPU上训练50次
4.3查看test1数据集F1分数及时间
4.4使用模型进行测试
4.5保存模型
5:使用oneAPI组件
5.1Transfer Learning with oneAPI AI Analytics Toolkit进行迁移学习
5.2使用Intel Extension for PyTorch进行优化
5.3使用 Intel® Neural Compressor 量化模型
5.3使用量化后的模型在 CPU上进行推理
6:总结
1:作业简介:猫狗大战
1.1问题描述:
在这个问题中,你将面临一个经典的机器学习分类挑战——猫狗大战。你的任务是建立一个分类模型,能够准确地区分图像中是猫还是狗。
1.2预期解决方案:
你的目标是通过训练一个机器学习模型,使其在给定一张图像时能够准确地预测图像中是猫还是狗。模型应该能够推广到未见过的图像,并在测试数据上表现良好。我们期待您将其部署到模拟的生产环境中——这里推理时间和二分类准确度(F1分数)将作为评分的主要依据。
1.3数据集
链接:百度网盘 请输入提取码
提取码:jc34
2:数据预处理
2.1数据集结构
本项目数据集共由两部分组成,分别包含为test1,train文件夹。

![]()
训练集test下有两个文件夹,分别为cat和dog,cat表示猫的训练图片,dog表示狗的训练图片

2.2探索性数据分析
在这里,我分别取了train数据集下的随机不重样3个猫,3个狗的图像进行展示。
import cv2train_dir = 'train' # 图片路径# 正常和肺炎的路径
cat_imgs = [fn for fn in os.listdir(f'{train_dir}/cat') if fn.endswith('.jpg')]
dog_imgs = [fn for fn in os.listdir(f'{train_dir}/dog') if fn.endswith('.jpg')]print(f'猫的数量为: {len(cat_imgs)}')
print(f'狗的数量为: {len(dog_imgs)}')# 随机不重样的抽选3个猫,3个狗
select_CAT = np.random.choice(cat_imgs, 3, replace=False)
select_DOG = np.random.choice(dog_imgs, 3, replace=False)# 使用pit打印出来
fig = plt.figure(figsize=(20, 10))
for i in range(6):if i < 3:fp = f'{train_dir}/cat/{select_CAT[i]}'label = 'CAT'else:fp = f'{train_dir}/dog/{select_DOG[i - 3]}'label = 'DOG'ax = fig.add_subplot(2, 3, i + 1) # 两行三列# to plot without rescaling, remove target_sizefn = cv2.imread(fp)fn_gray = cv2.cvtColor(fn, cv2.COLOR_BGR2GRAY)plt.imshow(fn, cmap='Greys_r')plt.title(label)plt.axis('off')
plt.show()# 总的训练集样本数
print(f'猫数量为: {len(cat_imgs)}')
print(f'狗数量为: {len(dog_imgs)}') 2.3提取数据集
2.3提取数据集
在本项目中,为了更好地提取出图像,我构建了一个函数,能够将每个主文件夹下的图片提取出来,并且打好了标签。
# 创建自定义数据集
class SelfDataset(Dataset):def __init__(self, root_dir, flag, transform=None):self.root_dir = root_dirself.transform = transformself.classes = ['cat', 'dog']self.flag=flagself.data = self.load_data()def load_data(self):data = []class_path = self.root_dirfor class_idx, class_name in enumerate(self.classes):if self.flag:class_path = os.path.join(self.root_dir, class_name)for file_name in os.listdir(class_path):file_path = os.path.join(class_path, file_name)if os.path.isfile(file_path) and file_name.lower().endswith('.jpg'):data.append((file_path, class_idx))return datadef __len__(self):return len(self.data)def __getitem__(self, idx):img_path, label = self.data[idx]img = Image.open(img_path).convert('RGB')if self.transform:img = self.transform(img)return img, label2.4数据增强
在图像预处理阶段,我首先采用transforms.RandomResizedCrop(64)对图像进行随机裁剪,并确保裁剪后的图像大小为64x64像素。这种处理方法旨在增强模型对物体不同尺寸和位置的鲁棒性,从而提高其泛化能力。
其次,我利用transforms.RandomHorizontalFlip对图像进行随机水平翻转。这一步旨在通过一定概率水平翻转图像来扩充训练数据。这有助于模型学习物体在水平方向上的不变性,进一步提升其泛化能力。
# 数据集路径
train_dataset_path = 'train'
test_dataset_path = 'test1'# 数据增强
transform = transforms.Compose([transforms.RandomResizedCrop(64),transforms.RandomHorizontalFlip(),transforms.ToTensor(),
])# 创建数据集实例
train_dataset = SelfDataset(root_dir=train_dataset_path, flag=True, transform=transform)
test_dataset = SelfDataset(root_dir=test_dataset_path, flag=False, transform=transform)# 创建 DataLoader
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
print(len(train_loader))
print(len(test_loader))3:使用卷积神经网络识别猫狗图像
3.1VGG-16架构
VGG-16是一个深度卷积神经网络模型,由16层组成,包括13个卷积层和3个全连接层。该模型通过反复堆叠3x3的小型卷积核和2x2的最大池化层,实现了深度的增加。VGG-16在ImageNet图像分类挑战赛中取得了优异的成绩,并成为了深度学习领域中的经典模型之一。
3.3卷积神经网络
卷积神经网络(CNN)是一种深度学习算法,通过模拟人脑视觉机制来识别图像。它利用卷积核在输入图像上滑动,提取局部特征,并通过多层卷积和池化操作逐步抽象出高级特征。广泛应用于图像分类、目标检测、人脸识别等领域。
3.3深度神经网络
深度神经网络(DNN)是一种复杂的神经网络结构,具有许多隐藏层。通过增加网络的深度,DNN能够更好地学习和表示复杂的特征,提高了分类和预测的准确率。然而,随着深度的增加,训练难度和过拟合的风险也随之增大。为了解决这些问题,研究者们提出了许多改进方法,如残差连接、批量归一化等。
3.4更改VGG-16网络结构
为了适应本项目需求,我对传统的VGG-16网络进行了调整,将其输出大小改为2,并优化了部分网络结构。
vgg16_model = models.vgg16(pretrained=True)# 如果需要微调,可以解冻最后几层
for param in vgg16_model.features.parameters():param.requires_grad = False# 修改分类层
num_features = vgg16_model.classifier[6].in_features
vgg16_model.classifier[6] = nn.Sequential(nn.Linear(num_features, 512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512, 2)
)
4:在CPU上训练
4.1参数设置
在提升训练精度方面,我采取了以下策略:
- 采用了交叉熵损失函数(nn.CrossEntropyLoss)来衡量模型的预测与真实标签之间的差异,这是分类任务中常用的损失函数。
- 使用Adam优化器(optim.Adam),一种基于梯度的优化算法,它在深度学习领域通常表现出色。
- 采用ReduceLROnPlateau学习率调度器(optim.lr_scheduler.ReduceLROnPlateau),该调度器通过监测验证集上的模型性能,并在性能停滞时降低学习率,以优化训练过程。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(vgg16_model.parameters(), lr=0.001, weight_decay=1e-4)# 添加学习率调度器
# 使用 ReduceLROnPlateau 调度器
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', factor=0.1, patience=3, verbose=True)# 训练参数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
vgg16_model.to(device)

4.2在intel云平台CPU上训练50次
在这里,我使用了两个数据集,分别为train,test1。
训练集train主要用于训练机器学习模型,模型通过学习训练集中的样本,调整参数,以捕捉输入数据的模式和特征。训练集通常规模最大,且高质量、多样性的训练集有助于提高模型的泛化能力。
测试集test1则用于评估训练好的模型的性能。测试集中的样本是模型在训练和验证过程中未曾见过的数据,因此测试集上的性能评估更接近模型在真实场景中的表现。测试集应完全独立于训练集和验证集,确保评估不受过拟合或过度调整的影响。
# 训练循环
num_epochs = 0
consecutive_f1_count = 0while num_epochs < 50:print(f'第{num_epochs+1}次训练开始了')vgg16_model.train() # 设置模型为训练模式train_loss = 0.0for inputs, labels in train_loader:inputs, labels = inputs.to(device), labels.to(device)# 将数据传递给模型outputs = vgg16_model(inputs)# 计算损失loss = criterion(outputs, labels)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()train_loss += loss.item()avg_train_loss = train_loss / len(train_loader)# 打印训练过程中的损失和验证损失print(f'Epoch [{num_epochs+1}], 第{num_epochs+1}轮:训练集损失: {avg_train_loss:.4f}')# 在模型训练完后,使用测试集进行最终评估vgg16_model.eval()all_predictions = []all_labels = []start_time = time.time() # 记录开始时间with torch.no_grad():for inputs, labels in test_loader:inputs, labels = inputs.to(device), labels.to(device)# 在测试集上进行推理outputs = vgg16_model(inputs)# 将预测结果和真实标签保存_, predicted = torch.max(outputs, 1)all_predictions.extend(predicted.cpu().numpy())all_labels.extend(labels.cpu().numpy())end_time = time.time() # 记录结束时间elapsed_time = end_time - start_timeprint(f'测试集用的时间为: {elapsed_time:.2f} seconds')# 计算F1分数f1 = f1_score(all_labels, all_predictions, average='binary') # 适用于二分类问题# 打印每轮的测试F1分数print(f'第{num_epochs+1}轮的测试F1分数: {f1:.4f}')# 调整学习率scheduler.step(f1)# 增加训练次数num_epochs += 14.3查看test1数据集F1分数及时间
在CPU上查看F1分数和时间时,大概F1分数达到0.5左右,时间为280s左右。

4.4使用模型进行测试
使用test1数据集里面的图像进行推理测试并打印出相应的图像。
import matplotlib.pyplot as plt
import numpy as np
# 选择一张 test_loader 中的图片
sample_image, true_label = next(iter(test_loader))# 将图片传递给模型进行预测
sample_image = sample_image.to(device)
with torch.no_grad():model_output = vgg16_model(sample_image)# 获取预测结果
_, predicted_label = torch.max(model_output, 1)# 转换为 NumPy 数组
sample_image = sample_image.cpu().numpy()[0] # 将数据从 GPU 移回 CPU 并取出第一张图片
predicted_label = predicted_label[0].item()true_label = true_label[0].item() # 直接获取标量值# 获取类别标签
class_labels = ['dog', 'cat']# 显示图像
plt.imshow(np.transpose(sample_image, (1, 2, 0))) # 转置图片的维度顺序
plt.title(f'TRUE LABEL IS: {class_labels[true_label]}, PREDICT LABEL IS: {class_labels[predicted_label]}')
plt.axis('off')
plt.show()

4.5保存模型
# 保存模型
torch.save(vgg16_model.state_dict(), 'vgg16_model.pth')# 打印保存成功的消息
print("模型已保存为 vgg16_model.pth")
5:使用oneAPI组件
5.1Transfer Learning with oneAPI AI Analytics Toolkit进行迁移学习
class CustomVGG16(nn.Module):def __init__(self):super(CustomVGG16, self).__init__()self.vgg16_model = models.vgg16(pretrained=True)for param in self.vgg16_model.features.parameters():param.requires_grad = Falsenum_features = self.vgg16_model.classifier[6].in_featuresself.vgg16_model.classifier[6] = nn.Sequential(nn.Linear(num_features, 512),nn.ReLU(),nn.Dropout(0.5),nn.Linear(512, 2))def forward(self, x):return self.vgg16_model(x)# 创建 CustomVGG16 模型实例
vgg16_model = CustomVGG16()# 创建 CustomVGG16 模型实例# 加载权重
vgg16_model.vgg16_model.load_state_dict(torch.load('vgg16_model.pth', map_location=torch.device('cpu')))

5.2使用Intel Extension for PyTorch进行优化
使用CPU进行训练相对较慢,而通过运用Intel Extension for PyTorch,我们显著提高了训练速度。相较于纯CPU训练,速度提升近一倍,同时F1值保持不变,确保了模型性能的稳定性。
# 保存模型参数
torch.save(vgg16_model.state_dict(), 'vgg16_optimized.pth')# 加载模型参数
loaded_model = CustomVGG16()
loaded_model.load_state_dict(torch.load('vgg16_optimized.pth'))
device = torch.device('cpu')
vgg16_model.to(device)# 重新构建优化器
optimizer = optim.Adam(vgg16_model.parameters(), lr=0.001, weight_decay=1e-4)# 使用Intel Extension for PyTorch进行优化
vgg16_model, optimizer = ipex.optimize(model=vgg16_model, optimizer=optimizer, dtype=torch.float32)5.3使用 Intel® Neural Compressor 量化模型
from neural_compressor.config import PostTrainingQuantConfig, AccuracyCriterion
from neural_compressor import quantization
import os# 加载模型
model = CustomVGG16()
model.load_state_dict(torch.load('vgg16_optimized.pth'))
model.to('cpu') # 将模型移动到 CPU
model.eval()# 定义评估函数
def eval_func(model):with torch.no_grad():y_true = []y_pred = []for inputs, labels in train_loader:inputs = inputs.to('cpu')labels = labels.to('cpu')preds_probs = model(inputs)preds_class = torch.argmax(preds_probs, dim=-1)y_true.extend(labels.numpy())y_pred.extend(preds_class.numpy())return accuracy_score(y_true, y_pred)# 配置量化参数
conf = PostTrainingQuantConfig(backend='ipex', # 使用 Intel PyTorch Extensionaccuracy_criterion=AccuracyCriterion(higher_is_better=True, criterion='relative', tolerable_loss=0.01))# 执行量化
q_model = quantization.fit(model,conf,calib_dataloader=train_loader,eval_func=eval_func)# 保存量化模型
quantized_model_path = './quantized_models'
if not os.path.exists(quantized_model_path):os.makedirs(quantized_model_path)q_model.save(quantized_model_path)
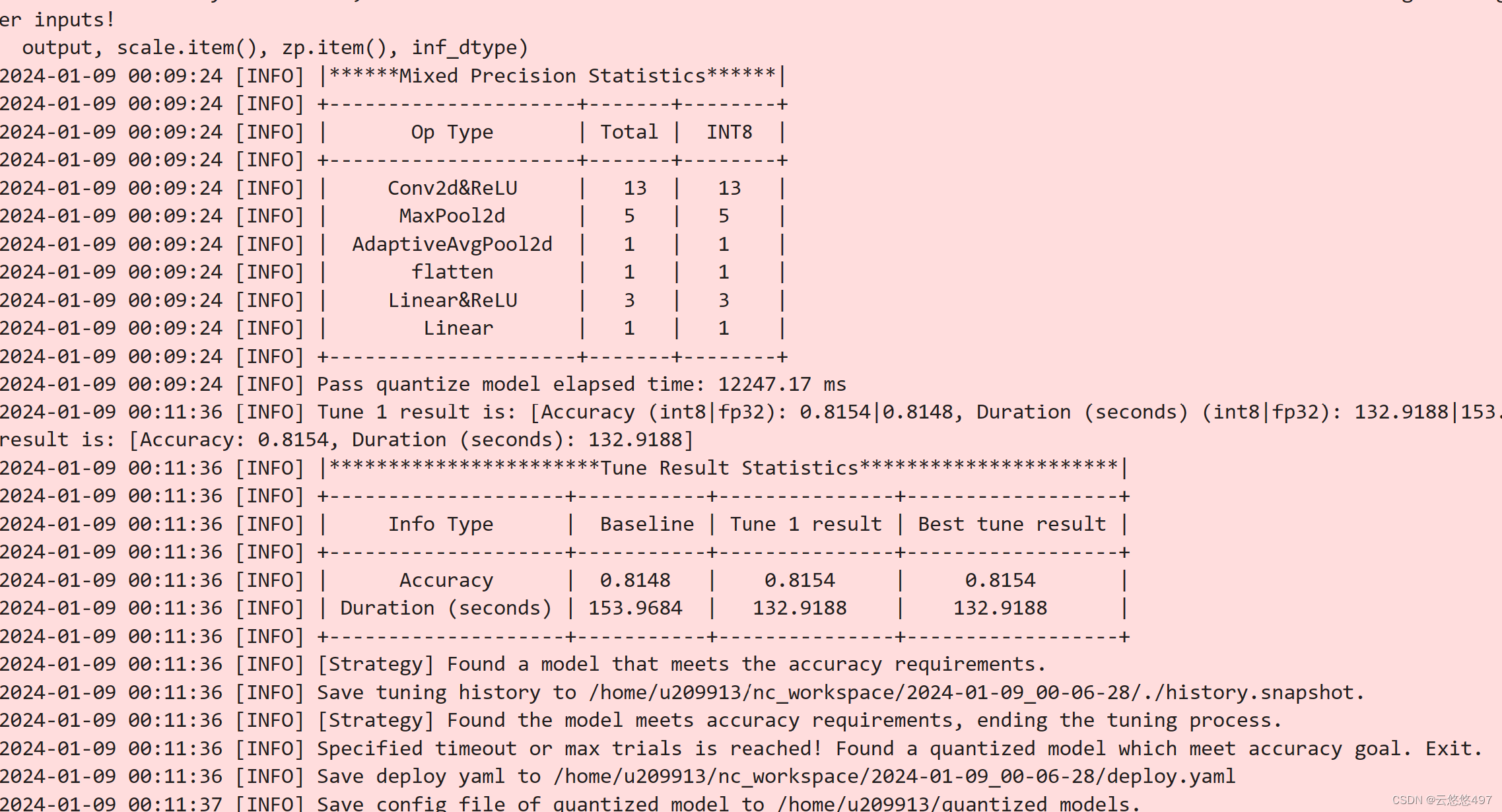

5.3使用量化后的模型在 CPU上进行推理
import torch
from sklearn.metrics import f1_score
import time# 假设 test_loader 是你的测试数据加载器
# 请确保它返回 (inputs, labels) 的形式# 将模型设置为评估模式
vgg16_model.eval()# 初始化变量用于存储真实标签和预测标签
y_true = []
y_pred = []# 开始推理
start_time = time.time()# 设置 batch_size
batch_size = 64# 使用 DataLoader 时设置 batch_size
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 在推理时处理每个批次with torch.no_grad():for inputs, labels in test_loader:# 将输入数据移动到 CPU(如果尚未在 CPU 上)inputs = inputs.to('cpu')labels = labels.to('cpu')# 获取模型预测preds_probs = vgg16_model(inputs)preds_class = torch.argmax(preds_probs, dim=-1)# 扩展真实标签和预测标签列表y_true.extend(labels.numpy())y_pred.extend(preds_class.numpy())# 计算 F1 分数
f1 = f1_score(y_true, y_pred, average='weighted')# 计算推理时间
inference_time = time.time() - start_time# 打印结果
print(f"F1 Score: {f1}")
print(f"Inference Time: {inference_time} seconds")

import matplotlib.pyplot as plt
import numpy as np# 选择一张 test_loader 中的图片
sample_image, true_label = next(iter(test_loader))# 将图片传递给模型进行预测
sample_image = sample_image.to(device)
with torch.no_grad():model_output = vgg16_model(sample_image)# 获取预测结果
_, predicted_label = torch.max(model_output, 1)# 转换为 NumPy 数组
sample_image = sample_image.cpu().numpy()[0] # 将数据从 GPU 移回 CPU 并取出第一张图片
predicted_label = predicted_label[0].item()true_label = true_label[0].item() # 直接获取标量值# 获取类别标签
class_labels = ['dog', 'cat']# 显示图像
plt.imshow(np.transpose(sample_image, (1, 2, 0))) # 转置图片的维度顺序
plt.title(f'TRUE LABEL IS: {class_labels[true_label]}, PREDICT LABEL IS: {class_labels[predicted_label]}')
plt.axis('off')
plt.show()

6:总结
在使用oneAPI的优化组件以后,推理的时间大幅度下降,从原来的180s到目前的169s,其次,在使用量化工具以后,F1分数的值一直稳定在0.5左右,这是一个非常好的现象。证明了oneAPI优秀的模型压缩能力,在保证模型精确度,F1值的基础上还能够缩小模型的规模。
这篇关于【Intel校企合作课程】猫狗大战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









