本文主要是介绍【intel校企合作课程】预测淡水质量,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.项目简介
- 1.1项目描述
- 1.2数据集展示
- 1.3预期处理方案
- 1.4Intel加速组件介绍
- 1.4.1 Modin
- 1.4.2 Daal4py
- 1.4.3 Scikit-learn
- 1.4.4 XGBoost
- 2.数据探索
- 2.1 数据集查看
- 2.1查看数据描述性统计信息
- 2.3将部分非数值型特征值转换为数值型特征值
- 2.4数据可视化
- 2.4.1 饼状图
- 2.4.2 热力图
- 2.4.3 条形图
- 2.5相关性分析
- 2.6删除不相关列
- 3.数据预处理
- 3.1 查看样本缺失值和重复行情况
- 3.2处理样本缺失值和重复行情况
- 3.3平衡数据
- 4.XGBoost算法
- 5.总结
1.项目简介
1.1项目描述
淡水是我们最重要和最稀缺的自然资源之一,仅占地球总水量的 3%。它几乎触及我们日常生活的方方面面,从饮用、游泳和沐浴到生产食物、电力和我们每天使用的产品。获得安全卫生的供水不仅对人类生活至关重要,而且对正在遭受干旱、污染和气温升高影响的周边生态系统的生存也至关重要。
1.2数据集展示
数据集链接:https://filerepo.idzcn.com/hack2023/datasetab75fb3.zip
1.3预期处理方案
通过参考英特尔的类似实现方案,预测淡水是否可以安全饮用和被依赖淡水的生态系统所使用,从而可以帮助全球水安全和环境可持续性发展。这里分类准确度和推理时间将作为评分的主要依据。
1.4Intel加速组件介绍
1.4.1 Modin
Modin是一个强大的工具,可以帮助用户加速大规模数据分析的处理速度。它提供了与pandas兼容的API,使得用户可以无缝地在Modin和pandas之间切换,同时还提供了并行计算、可扩展性和易于使用等特性。
1.4.2 Daal4py
daal4py 是 Intel 提供的一个 Python 库,用于实现快速的数据分析和机器学习算法。
1.4.3 Scikit-learn
Scikit-learn组件为使用Scikit-learn进行机器学习的用户提供了显著的性能提升。通过利用Intel的硬件优化技术和跨设备兼容性,这个组件使得处理大规模数据集和运行复杂算法变得更加高效和便捷。
1.4.4 XGBoost
XGBoost组件为使用XGBoost进行机器学习的用户提供了更高的性能。通过利用Intel的硬件优化技术和改进数据加载处理方式,这个组件使得处理大规模数据集和运行复杂算法变得更加高效和快速。
2.数据探索
!pip install modin dask
import modin.pandas as pd
import os
import daal4py as d4p
os.environ["MODIN_ENGINE"] = "dask"from modin.config import Engine
Engine.put("dask")from sklearnex import patch_sklearn
patch_sklearn()
2.1 数据集查看
!pip install "dask[distributed]" --upgrade
data = pd.read_csv('Water/dataset.csv')
print('数据规模:{}\n'.format(data.shape))
display(data.head())

data.info()
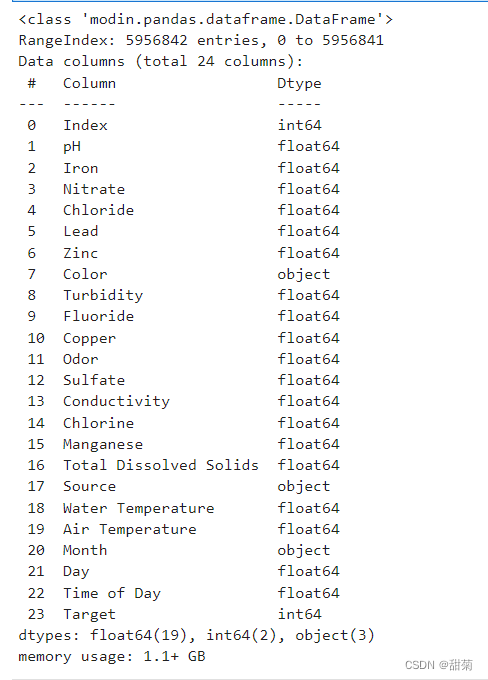
该数据集总共有5956842条数据,代码展示了前5行的数据可以看到每条数据总共有24个特征。其中float64类型的特征有19列,int64类型的特征有2列,object类型的特征有3列,内存空间大约占了1.1GB。
2.1查看数据描述性统计信息
desc=data.describe()
# 显示描述性统计信息
print(desc)
 查看数据集各个特征的非空值的数量、平均值、标准差、最小值、第一四分位数、中位数、第三四分位数、最大值。
查看数据集各个特征的非空值的数量、平均值、标准差、最小值、第一四分位数、中位数、第三四分位数、最大值。
2.3将部分非数值型特征值转换为数值型特征值

'Color’列特征值和’Source’列特征值通过factorize()函数从最开始的文本标签被替换成了整数标签。因为月份有特定的对应关系所以单独将’Month’对应映射到了1~12。
2.4数据可视化
2.4.1 饼状图
import matplotlib.pyplot as pltdef plot_target(target_col):tmp=data[target_col].value_counts(normalize=True)target = tmp.rename(index={1:'Target 1',0:'Target 0'})wedgeprops = {'width':0.5, 'linewidth':10}plt.figure(figsize=(6,6))plt.pie(list(tmp), labels=target.index,startangle=90, autopct='%1.1f%%',wedgeprops=wedgeprops)plt.title('Label Distribution', fontsize=16)plt.show() plot_target(target_col='Target')
 使用饼图来直观展示不同类别在目标列中的比例。
使用饼图来直观展示不同类别在目标列中的比例。
2.4.2 热力图
import seaborn as sns
# 设置图形大小和 DPI
fig, ax = plt.subplots(figsize=(30, 20), dpi=128)
corr= sns.heatmap(data.corr(method='spearman'),annot=True,square=True)
plt.title('Spearman Correlation Heatmap')
#显示图表
plt.show()
 通过热力图可以很直观的看出不同特征之间的相关性。
通过热力图可以很直观的看出不同特征之间的相关性。
2.4.3 条形图
import numpy as np # 导入numpy库并设置别名np
bar = data.corr()['Target'].abs().sort_values(ascending=False)[1:]
# 设置图形大小
plt.rcParams.update({'figure.figsize': (10, 5)})
plt.bar(bar.index, bar, width=0.5)
plt.xticks(bar.index, bar.index, rotation=-60, fontsize=8)
# 显示图形标题
plt.title('Absolute Correlation with Target')
plt.show()
 条形图主要目的是展示数据集中除了’Target’列之外的其他列与’Target’列之间的绝对相关性的大小。
条形图主要目的是展示数据集中除了’Target’列之外的其他列与’Target’列之间的绝对相关性的大小。
2.5相关性分析
通过热力图和条形图来看’Day’列、'Time of Day’列、'Month’列、'Water Temperature’列、'Source’列、'Conductivity’列、'Air Temperature’列与’Target’列的相关性很差,为了保留与目标变量有较强的关联的特征就将这些列从数据集中删除。
2.6删除不相关列
#删除不相关的列
data = data.drop(columns=['Day', 'Time of Day', 'Month', 'Water Temperature', 'Source' , 'Conductivity' , 'Air Temperature'])
3.数据预处理
3.1 查看样本缺失值和重复行情况
data = data.drop(columns=['Index'])
要先将’index’列删除,不然每条数据至少索引值是不同的就会得到重复值为0。
 不管是缺失还是重复数据数量都很大,缺失数据达到了1603858个,重复数据达到了143032条。
不管是缺失还是重复数据数量都很大,缺失数据达到了1603858个,重复数据达到了143032条。
3.2处理样本缺失值和重复行情况
常见的处理缺失值方法:
1.删除含有缺失值的行或列:
如果缺失值很多,或者某一列缺失值过多,可以考虑直接删除该列或含有缺失值的行。
2.填充缺失值:
使用常数(如0、平均值、中位数、众数等)填充缺失值。
使用其他列的值来填充缺失值,例如使用同一分类下的其他列的平均值。
使用插值方法(如线性插值、多项式插值等)来预测缺失值。
使用机器学习算法(如KNN、决策树等)来预测缺失值。
3.不处理:
在某些情况下,缺失值可能表示某种信息,如用户未填写某项信息等。这种情况下,可以保留缺失值,不进行任何处理。
常见的处理重复行方法:
1.删除重复行:
使用 DataFrame.drop_duplicates() 方法删除重复行。
2.标记重复行:
使用 DataFrame.duplicated() 方法标记重复行,返回一个布尔型序列,表示每行是否是重复行。
标记后,可以根据需要进行进一步处理,如删除、高亮显示等。
3.合并重复行:
如果重复行包含不同的信息,可以考虑合并这些行。
可以使用 groupby 和 agg 方法对重复行进行分组和聚合操作,例如求和、求平均值等。
# 首先删除重复的行
data = data.drop_duplicates() # 然后计算每列的均值
mean_values = data.mean() # 使用每列的均值来填充该列的缺失值
data_filled = data.fillna(mean_values) # 我直接修改原始的DataFrame,而不是创建一个新的DataFrame
data = data_filledmissing=data.isna().sum().sum()
duplicates=data.duplicated().sum()
print("\n数据集中有{:,.0f} 缺失值.".format(missing))
print("数据集中有 {:,.0f} 重复值.".format(duplicates))

3.3平衡数据

通过饼状图也可以直观看到Target 0:Target1 = 2.31:1,当类别不平衡时,模型的性能可能会受到影响所以需要后续数据的平衡。
常见的平衡数据的方法:
1.上采样:对于数量较少的类别,通过复制样本或生成合成样本来增加其数量。常用的上采样方法有SMOTE(Synthetic Minority Over-sampling Technique)等。
2.下采样:对于数量较多的类别,随机选择部分样本来减少其数量,使得数据达到平衡状态。但这种方法可能会导致信息丢失。
3.调整分类器权重:
在训练过程中,可以为不同的类别设置不同的权重,使得模型在训练时更加关注少数类样本。例如,在使用支持向量机(SVM)时,可以通过设置不同的惩罚参数C来调整对不同类别的重视程度。
4.使用集成学习方法:
集成学习方法,如随机森林、梯度提升树等,可以通过组合多个基本分类器的预测结果来提高整体性能。在构建集成模型时,可以采用不同的采样策略来平衡数据,如Bagging、Boosting等。
5.生成对抗网络(GANs):
生成对抗网络可以用于生成新的样本,从而增加少数类样本的数量。通过训练一个生成器和一个判别器,GANs可以生成与真实数据分布相似的样本,从而缓解数据不平衡问题。
6.使用代价敏感学习(Cost-sensitive Learning):
代价敏感学习是一种让模型在训练时考虑到不同类别样本的误分类成本的方法。通过为不同类别的误分类设置不同的代价,可以使得模型在训练时更加关注少数类样本。
# 导入必要的库
from imblearn.over_sampling import ADASYN
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
# 分割特征和标签
X = data.drop('Target', axis=1).values
y = data['Target'].values # 初始化ADASYN采样器
adasyn = ADASYN(random_state=21) # 使用ADASYN对特征和标签进行拟合和重采样
X_resampled, y_resampled = adasyn.fit_resample(X, y) # 将y_resampled转换为Pandas Series以便进行统计
y_resampled_series = pd.Series(y_resampled) # 查看平衡后的类别比例
class_counts = y_resampled_series.value_counts()
print("Balanced Class Counts:")
print(class_counts)
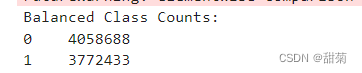
我使用的是ADASYN方法,它的主要思想是根据每个少数类别样本的邻近情况生成合成样本。ADASYN 为每个少数类别样本分配了一个权重,该权重表示该样本需要生成多少个合成样本。权重的计算基于该样本的邻近样本中多数类别的比例。如果一个少数类别样本的邻近样本中多数类别占据主导地位,那么它将获得更高的权重,从而生成更多的合成样本。通过结果可以看出经过平衡数据的处理Target 0:Target 1 = 1:1。
4.XGBoost算法
XGBoost算法介绍:
XGBoost采用集成思想——Boosting思想,将多个弱学习器通过一定的方法整合为一个强学习器,即用多棵树共同决策。每棵树的结果都是目标值与之前所有树的预测结果之差,并将所有的结果累加即得到最终的结果,以此达到整个模型效果的提升。
XGBoost算法特点:
1.效果好:在各种数据竞赛中大放异彩,而且在工业界也是应用广泛,这主要得益于其优异的效果
2.使用简单:用户只需调用几个函数即可实现强大的功能。
3.速度快:在处理大规模数据集时,XGBoost展现了其高效性。
4.可扩展性:XGBoost能够处理多种类型的数据,包括文本、数值等,这使得它在处理复杂问题时具有很高的灵活性。
import xgboost as xgb
from sklearn.metrics import accuracy_score, f1_score, classification_report
from time import time # 将数据转换为DMatrix格式
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test) # 设置XGBoost参数
param = { 'max_depth': 3, # 树的最大深度 'eta': 0.3, # 学习率 'objective': 'multi:softmax', # 多分类的目标函数 'num_class': len(set(y_train)) # 类别数,设置为训练集中唯一标签的数量
} # 设置评估指标
evals = [(dtrain, 'train'), (dtest, 'test')] # 训练模型
num_boost_round = 100
bst = xgb.train(param, dtrain, num_boost_round=num_boost_round, evals=evals, early_stopping_rounds=10) # 获取最佳迭代次数
best_iteration = bst.best_iteration # 使用最佳迭代次数进行预测
y_pred_proba = bst.predict(dtest, ntree_limit=best_iteration) # 将预测的概率转换为类别标签
y_pred = [np.argmax(x) for x in y_pred_proba] # 计算分类准确度
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}") # 计算F1分数
f1 = f1_score(y_test, y_pred, average='macro')
print(f"F1 Score: {f1:.2f}") # 打印完整的分类报告
report = classification_report(y_test, y_pred)
print(report)
# 计算推理时间
start_time = time() # 使用最佳迭代次数进行预测
y_pred_proba = bst.predict(dtest, iteration_range=(0, best_iteration + 1)) # 确保 y_pred_proba 是一个二维数组
if y_pred_proba.ndim == 1: # 如果是一维数组,则将其重塑为二维数组,每行一个样本 y_pred_proba = y_pred_proba.reshape(-1, 1) # 找到每行最大值的索引作为预测类别
y_pred = np.argmax(y_pred_proba, axis=1) end_time = time()
inference_time = end_time - start_time
print(f"Inference time: {inference_time:.2f} seconds") 直接使用XGBoost算法训练模型发现最后的效果不是很好,所以考虑到使用参数优化来优化模型。
常见参数优化的方法:
1.网格搜索(Grid Search):这是最简单和最直接的方法,它通过穷举所有可能的参数组合来找到最优的参数。然而,由于需要尝试的参数组合可能非常多,因此这种方法可能会非常耗时。
2.随机搜索(Random Search):随机搜索是一种更高效的参数优化方法,它随机选择参数组合而不是穷举所有可能。这种方法通常比网格搜索更快,因为它不需要尝试所有的参数组合。
3.贝叶斯优化(Bayesian Optimization):贝叶斯优化是一种基于概率模型的优化方法,它使用先前的结果来预测下一个可能的最佳参数。这种方法通常比网格搜索和随机搜索更有效,因为它能够在探索(寻找新的可能的最优解)和利用(在已知的最优解附近寻找更好的解)之间找到平衡。
4.梯度下降(Gradient Descent):这是一种迭代方法,通过计算损失函数对参数的梯度,然后按照梯度的反方向更新参数,从而找到使损失函数最小的参数。这种方法通常用于优化连续参数。
5.遗传算法(Genetic Algorithms):遗传算法是一种模拟自然选择和遗传学原理的优化方法。它通过选择、交叉和变异等操作来生成新的参数组合,并保留表现最好的参数组合。这种方法通常用于处理复杂的优化问题。
6.自适应优化算法(Adaptive Optimization Algorithms):这些算法如Adam、RMSprop等,它们通过调整学习率等参数来优化模型的训练过程。这些算法通常能够更快地收敛到最优解,并且在处理大规模数据集时表现良好。
使用随机搜索参数优化
import xgboost as xgb
from sklearn.model_selection import RandomizedSearchCV
from sklearn.metrics import make_scorer, accuracy_score
from time import time # 将数据转换为DMatrix格式
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test) # 定义参数网格
param_grid = { 'max_depth': [3, 5, 7], 'eta': [0.1, 0.2, 0.3], 'gamma': [0, 0.25, 1.0], 'colsample_bytree': [0.5, 0.75, 1.0], 'subsample': [0.5, 0.75, 1.0]
} # 设置评估指标为准确率
scoring = make_scorer(accuracy_score) # 使用RandomizedSearchCV进行参数优化
n_iter_search = 20 # 随机采样的参数组合数量
random_search = RandomizedSearchCV( estimator=xgb.XGBClassifier(objective='multi:softmax', num_class=len(set(y_train))), param_distributions=param_grid, n_iter=n_iter_search, scoring=scoring, n_jobs=-1, # 使用所有可用的CPU核心 cv=5, # 使用5折交叉验证 verbose=0, # 不输出优化过程的信息 . random_state=42 # 保证结果的可复现性
)
random_search.fit(X_train, y_train) # 使用最佳参数重新训练模型
best_model = random_search.best_estimator_
模型保存
model_filename = 'best_xgb_model.model'
best_model.save_model(model_filename)
使用验证集评估模型(数据集处理略)
import xgboost as xgb
import numpy as np
from sklearn.metrics import accuracy_score, f1_score, classification_report
from time import time # 加载模型
loaded_model = xgb.Booster() # 实例化Booster类
loaded_model.load_model(model_filename) # 加载训练好的模型文件# 记录开始时间
start_time = time() # 使用模型进行预测
y_pred_proba_validation = loaded_model.predict_proba(X_validation)
y_pred_validation = [np.argmax(x) for x in y_pred_proba_validation] # 记录结束时间
end_time = time() # 计算推理时间
inference_time = end_time - start_time
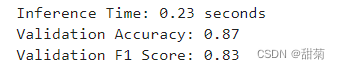
print(f"Inference Time: {inference_time:.2f} seconds") # 计算验证集上的分类准确度
accuracy_validation = accuracy_score(y_validation, y_pred_validation)
print(f"Validation Accuracy: {accuracy_validation:.2f}") # 计算F1分数
f1_validation = f1_score(y_validation, y_pred_validation, average='macro')
print(f"Validation F1 Score: {f1_validation:.2f}")
结果展示
5.总结
Intel的oneAPI在机器学习与数据挖掘领域中的作用不可忽视。它提供了一个统一的编程模型、一系列优化过的库和工具,以及与多种机器学习框架的集成能力,这些都有助于加速机器学习和数据挖掘应用的开发和执行效率。
通过本次项目实践,我对机器学习的基本步骤有了一个更深层次的理解。主要是从饼状图、热力图和条形图作为切入点进行数据可视化进一步分析了相关性。将相关性不高的列进行删除。本数据集有大量的缺失数据和重复行我采取的措施是删除重复行,对缺失数据进行均值填充。平衡数据我所采取的方法是ADASYN方法,ADASYN方法在处理不平衡数据集时具有显著的优势,可以提高模型的分类性能,特别是对于少数类别的学习效果。模型训练采用的是XGBoost算法,直接使用XGBoost算法训练模型效果不好。所以我考虑使用随机搜索参数优化,将训练好的模型进行保存然后用验证集进行评估,结果是准确率在0.87左右,f1分数在0.83左右。
这篇关于【intel校企合作课程】预测淡水质量的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









