本文主要是介绍Stable Diffusion + Segment Anything试用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
安装
- 从continue-revolution/sd-webui-segment-anything安装插件
- 分割模型下载后放到这个位置:
${sd-webui}/extension/sd-webui-segment-anything/models/sam下,可以下载3个不同大小的模型,从大到小如下:vit_h is 2.56GB, vit_l is 1.25GB, vit_b is 375MB。如果显存不够的话,可以考虑使用小模型。当然效果也可能会有损失。 经过上述步骤后,插件就安装好了。
使用教程
图片分割
安装
- 从continue-revolution/sd-webui-segment-anything安装插件
- 分割模型下载后放到这个位置:
${sd-webui}/extension/sd-webui-segment-anything/models/sam下,可以下载3个不同大小的模型,从大到小如下:vit_h is 2.56GB, vit_l is 1.25GB, vit_b is 375MB。如果显存不够的话,可以考虑使用小模型。当然效果也可能会有损失。 经过上述步骤后,插件就安装好了。
使用教程
图片分割
手动方式
- 标注图片
左键标记成黑点代表想要的物体,右键标记成红点代表不需要分割的物体
- 分割结果 使用
Preview Segmentation按钮生成分割图
 根据分割的多个结果中选择1个最满意的节点
根据分割的多个结果中选择1个最满意的节点
使用GroundingDINO加提示词自动识别分割物
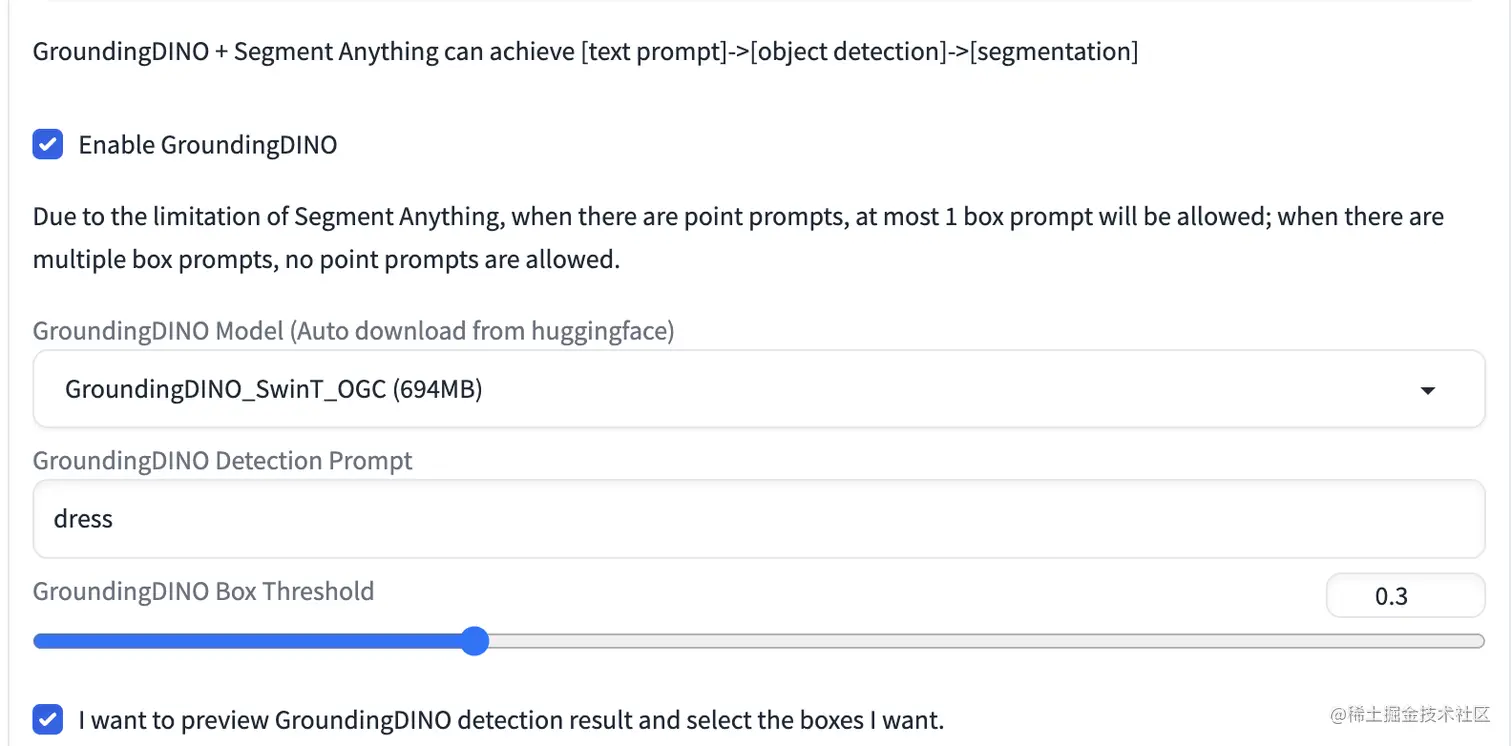
勾选Enable GroundingDINO,就会出现下面的GroundingDINO Model (Auto download from huggingface)和GroundingDINO Detection Prompt,其中GroundingDINO Detection Prompt填上想要分割的物体,比如"dress" 点击Generate bounding box按钮,就可以看到分割效果,如下所示:
-
分割结果 使用
Preview Segmentation按钮生成分割图,和上面一样。 -
扩充(可选)
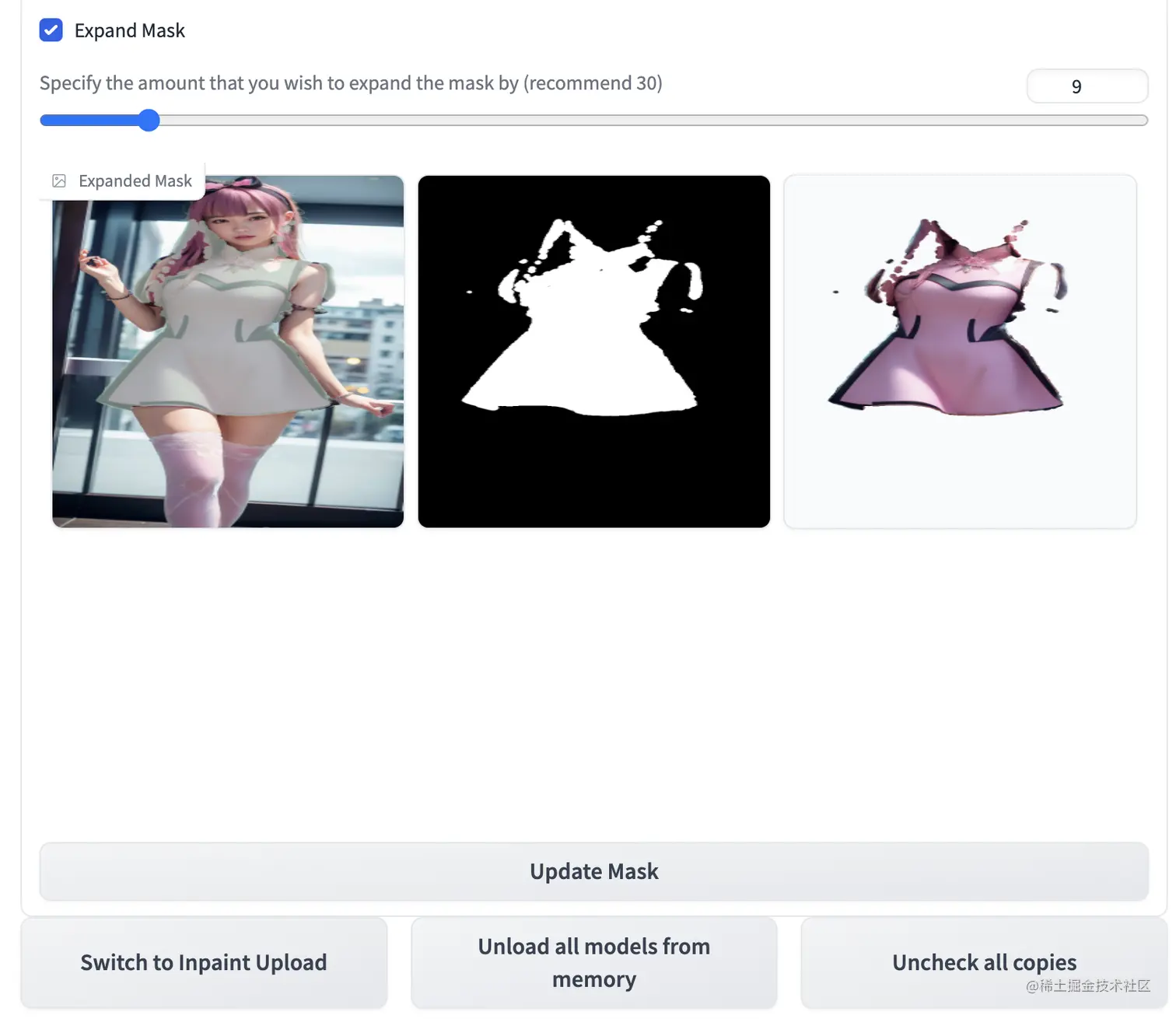
如果分割图里面会有一些点没有完全覆盖的话,可以考虑扩充mask来使分割结果更好。比如上面手动分割图中裙子会有一些点没有覆盖到,可以考虑扩充像素。
点击Switch to Inpaint Upload,接下来就是使用【局部重绘(上传蒙版)】来做局部重绘了。
局部重绘(上传蒙版)
- 除了把“重绘区域”修改成“仅蒙版”,这里大部分使用默认的参数。
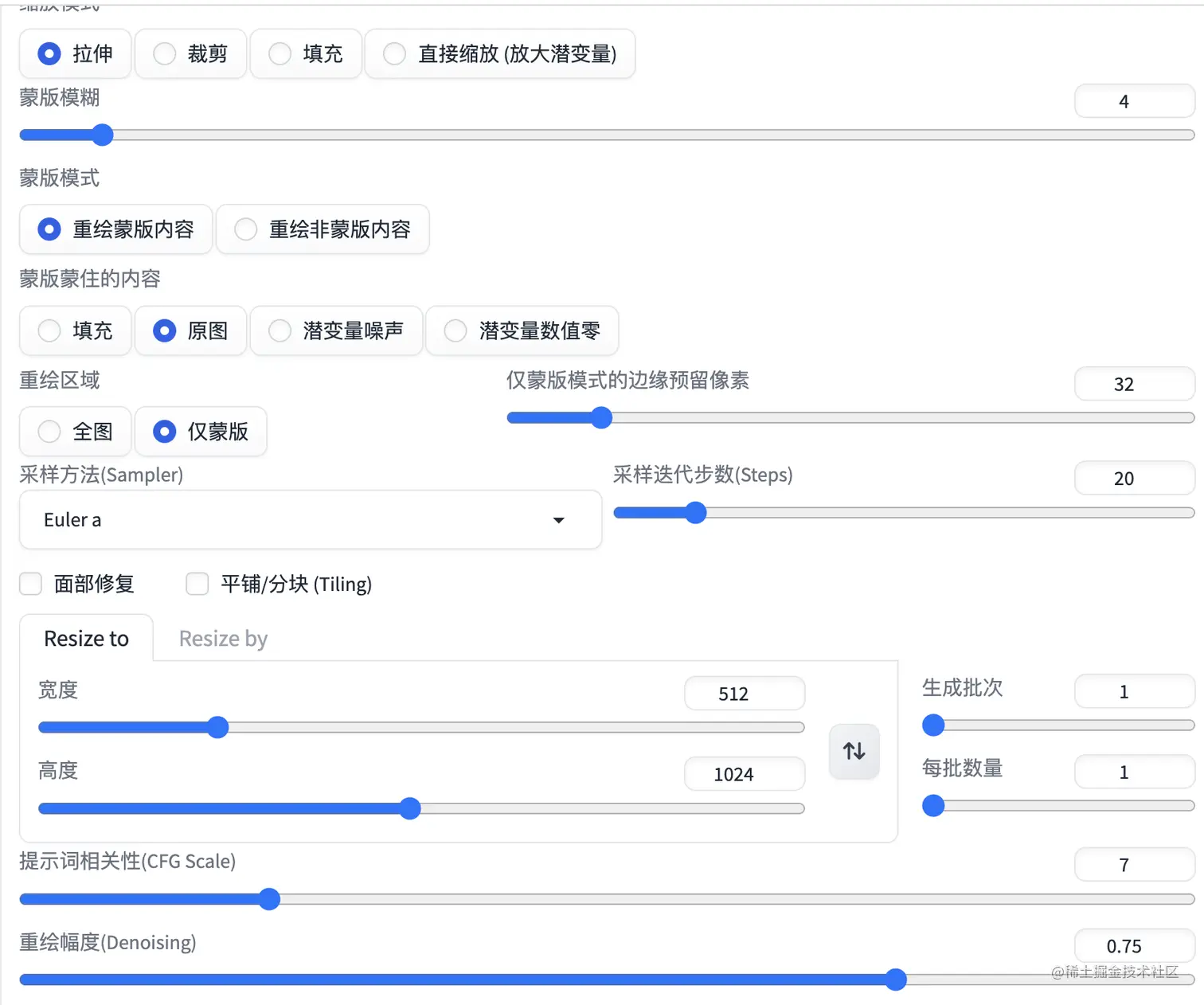
- 选择对应的controlNet,比如上面选择的是第1个分割结果,那就选择
ControlNet Unit 1:
- 勾选启用、勾选
Pixel Perfect,如果显存不够可以勾选低显存优化 - 选择预处理:inpait_global_harmonious,模型:control_v11_sd15_inpaint
- 其他参数默认
效果
使用X/Y/Z Plot脚本来替换提示词,如下:
red dress, pink dress,white dress,blue dress, frilled dress效果如下:

可以看到还是比较完美的做了换装。
总结
本文简单使用了stable diffusion webui的Segment Anything来实验了换装操作,整体效果还是比较好的,当然目前选择的还是比较简单的图片,如果比较复杂的图片,是否还有这么好的效果,还需继续研究和试验。 当然作者认为它主要是为了方便做局部重绘时需要手动标记重绘区域时的不便,有了Segment Anything可以提高标记效率。
附录
遇到的问题
- 显存不够
torch.cuda.OutOfMemoryError: CUDA out of memory. ......查看后台运行程序可能会时长出现上面的问题,这就是显存不够导致的,可以尝试把SAM Model修改成最小的vit_b,让流程跑起来。当然也可能目前该扩展还有一些显存的问题,看Issue上面也有挺多人遇到类似问题。
- 安装的版本不对
The detected CUDA version (12.1) mismatches the version that was used to compile PyTorch (11.7). Please make sure to use the same CUDA versions.- 需要保证保证
nvcc --version显示的版本和nvidia-smi显示的版本保持一致。如果不一致,可能需要重新编译cuda版本。
写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。

一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这篇关于Stable Diffusion + Segment Anything试用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








