本文主要是介绍一文读懂CRNN+CTC(Connectionist Temporal Classification)文字识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
先总结一把CTC,下面文档太长:
CTC是一种Loss计算方法,用CTC代替Softmax Loss,TF和pytorch都有对CTC的实现,从而解决OCR或者语音识别中序列对齐的问题。CTC特点:
- 引入blank字符,解决有些位置没有字符的问题
- 通过递推,快速计算梯度

- CTC在递推最终概率的时候, 使用前向后向算法,类似HMM中的前向后向算法
- CTC在最终求解的时候,使用beam search
-----------------------------------------
文字识别也是图像领域一个常见问题。然而,对于自然场景图像,首先要定位图像中的文字位置,然后才能进行识别。
所以一般来说,从自然场景图片中进行文字识别,需要包括2个步骤:
- 文字检测:解决的问题是哪里有文字,文字的范围有多少
- 文字识别:对定位好的文字区域进行识别,主要解决的问题是每个文字是什么,将图像中的文字区域进转化为字符信息。

图1 文字识别的步骤
文字检测类似于目标检测,即用 box 标识出图像中所有文字位置。对于文字检测不了解的读者,请参考本专栏文章:
场景文字检测—CTPN原理与实现674 赞同 · 54 评论文章正在上传…重新上传取消
本文的重点是如何对已经定位好的文字区域图片进行识别。假设之前已经文字检测算法已经定位图中的“subway”区域(红框),接下来就是文字识别。

图2 文字检测定位文字图像区域
基于RNN文字识别算法主要有两个框架:

图3 基于RNN文字识别2种基本算法框架
- CNN+RNN+CTC(CRNN+CTC)
- CNN+Seq2Seq+Attention
本文主要介绍第一种框架CRNN+CTC,对应TensorFlow 1.15实现代码如下。本文介绍的CRNN网络结构都基于此代码。另外该代码已经支持不定长英文识别。
bai-shang/crnn_ctc_ocr_tfgithub.com/bai-shang/crnn_ctc_ocr_tf正在上传…重新上传取消
需要说明该代码非常简单,只用于原理介绍,也无法识别中文。
CRNN基本网络结构
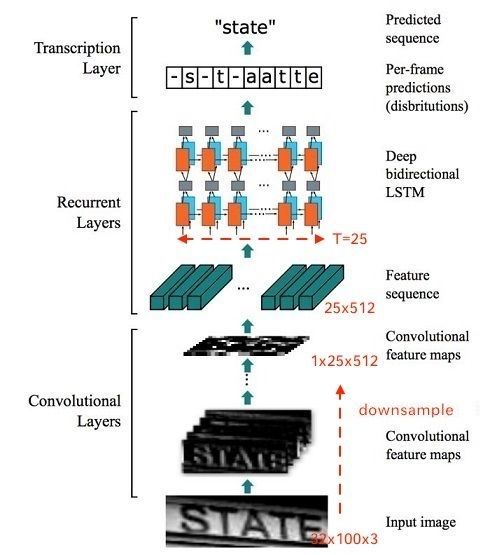
图4 CRNN网络结构(此图按照本文给出的github实现代码画的)
整个CRNN网络可以分为三个部分:
假设输入图像大小为 (32,100,3),注意提及图像都是 形式。
- Convlutional Layers
这里的卷积层就是一个普通的CNN网络,用于提取输入图像的Convolutional feature maps,即将大小为(32,100,3) 的图像转换为 (1,25,512) 大小的卷积特征矩阵,网络细节请参考本文给出的实现代码。
- Recurrent Layers
这里的循环网络层是一个深层双向LSTM网络,在卷积特征的基础上继续提取文字序列特征。对RNN不了解的读者,建议参考:
完全解析RNN, Seq2Seq, Attention注意力机制928 赞同 · 39 评论文章正在上传…重新上传取消
所谓深层RNN网络,是指超过两层的RNN网络。对于单层双向RNN网络,结构如下:
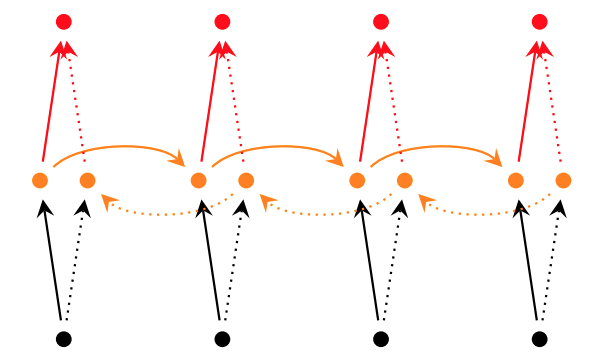
图5 单层双向RNN网络
而对于深层双向RNN网络,主要有2种不同的实现:
tf.nn.bidirectional_dynamic_rnn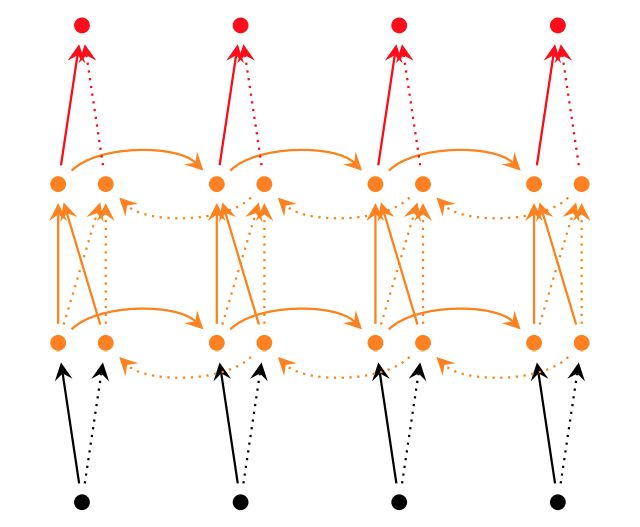
图6 深层双向RNN网络
tf.contrib.rnn.stack_bidirectional_dynamic_rnn
图7 stack形深层双向RNN网络
在CRNN中显然使用了第二种stack形深层双向结构。
由于CNN输出的Feature map是(1,25,512)大小,所以对于RNN最大时间长度 (即有25个时间输入,每个输入x_t列向量有D=512)。
- Transcription Layers
将RNN输出做softmax后,为字符输出。
关于代码中输入图片大小的解释:
在本文给出的实现中,为了将特征输入到Recurrent Layers,做如下处理:
- 首先会将图像在固定长宽比的情况下缩放到32×W×3大小( 代表任意宽度)
- 然后经过CNN后变为1×(W/4)×512
- 针对LSTM设置 T=(W/4) ,即可将特征输入LSTM。
所以在处理输入图像的时候,建议在保持长宽比的情况下将高缩放到32,这样能够尽量不破坏图像中的文本细节(当然也可以将输入图像缩放到固定宽度,但是这样由于破坏文本的形状,肯定会造成性能下降)。
考虑训练Recurrent Layers时的一个问题:

图8 感受野与RNN标签的关系
对于Recurrent Layers,如果使用常见的Softmax cross-entropy loss,则每一列输出都需要对应一个字符元素。那么训练时候每张样本图片都需要标记出每个字符在图片中的位置,再通过CNN感受野对齐到Feature map的每一列获取该列输出对应的Label才能进行训练,如图9。
在实际情况中,标记这种对齐样本非常困难(除了标记字符,还要标记每个字符的位置),工作量非常大。另外,由于每张样本的字符数量不同,字体样式不同,字体大小不同,导致每列输出并不一定能与每个字符一一对应。
当然这种问题同样存在于语音识别领域。例如有人说话快,有人说话慢,那么如何进行语音帧对齐,是一直以来困扰语音识别的巨大难题。

图9
所以CTC提出一种对不需要对齐的Loss计算方法,用于训练网络,被广泛应用于文本行识别和语音识别中。
Connectionist Temporal Classification(CTC)详解
在分析过程中尽量保持和原文符号一致。
Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networksftp://ftp.idsia.ch/pub/juergen/icml2006.pdf
整个CRNN的流程如图10。先通过CNN提取文本图片的Feature map,然后将每一个channel作为 的时间序列输入到LSTM中。
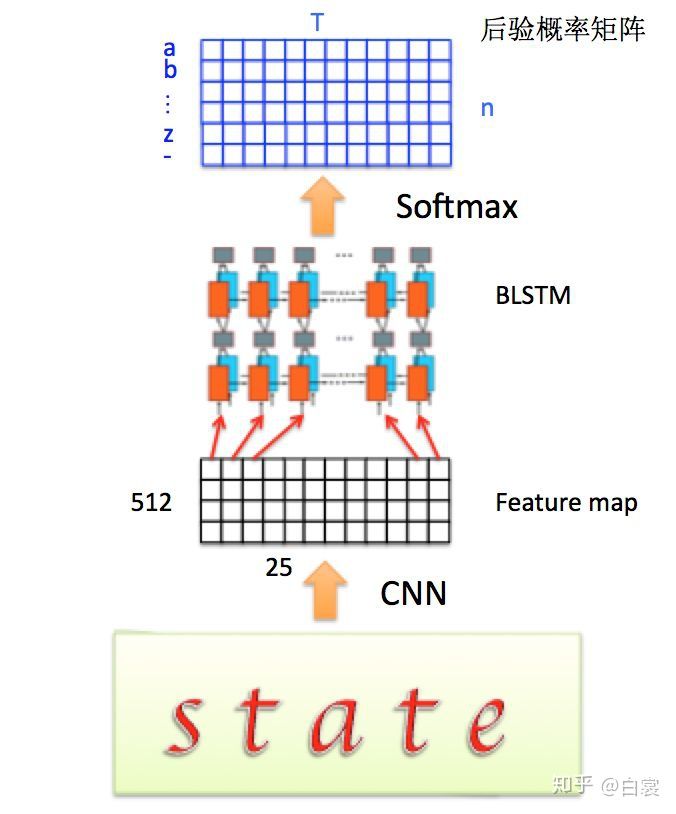
图10 CRNN+CTC框架
为了说明问题,我们定义:
- CNN Feature map
Feature map的每一列作为一个时间片输入到LSTM中。设Feature map大小为mT (图11中 m=512 ,T=25 )。下文中的时间序列t都从t=1开始,即1<=t<=T。
定义为:

其中 每一列 为:

- LSTM
LSTM的每一个时间片后接softmax,输出 y 是一个后验概率矩阵,定义为:
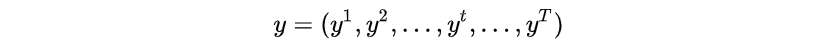

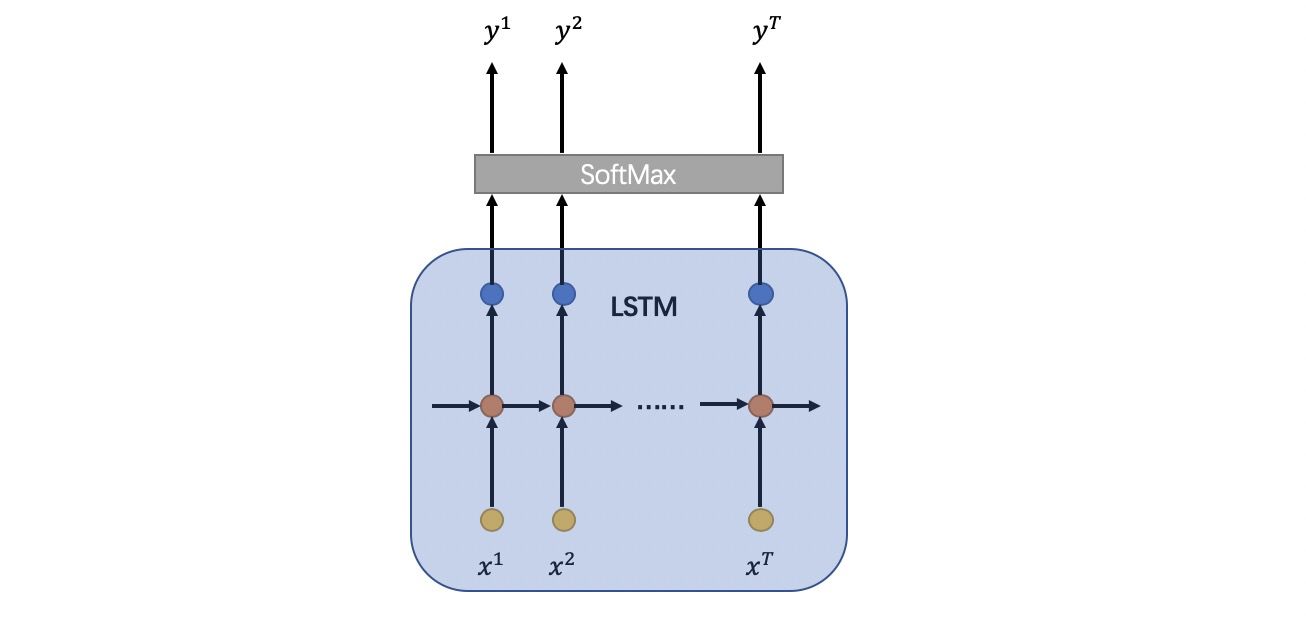
图11


那么CTC怎么做?

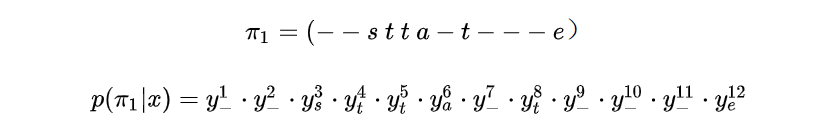
实际情况中一般手工设置 ,所以有非常多条 路径,即 非常大,无法逐条求和直接计算 。所以需要一种快速计算方法。
CTC的训练目标
图14


图14

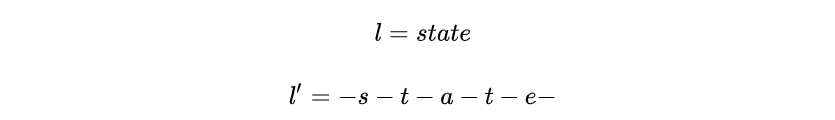

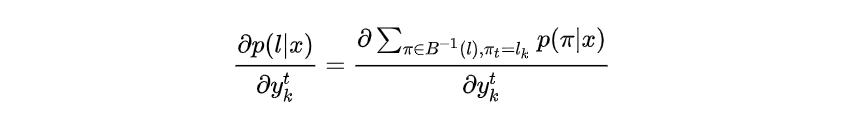


图15

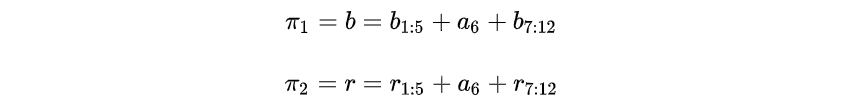
那么 可以表示为:
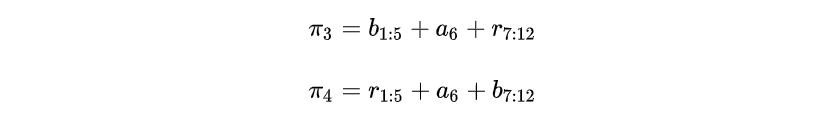
计算:
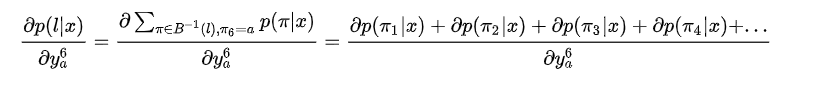
为了观察规律,单独计算 。
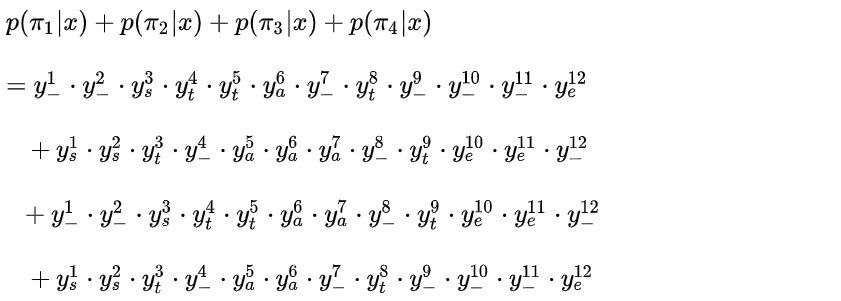
不妨令:
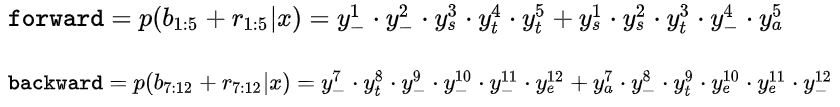


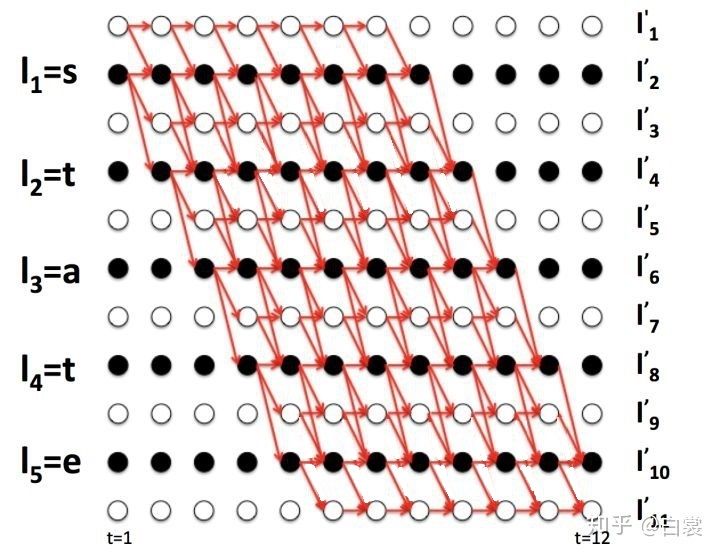
图16

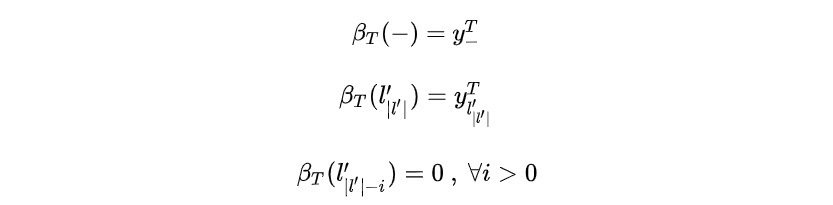

那么forward和backward相乘有:
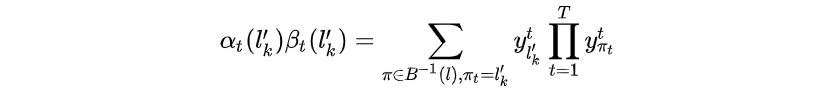
或:
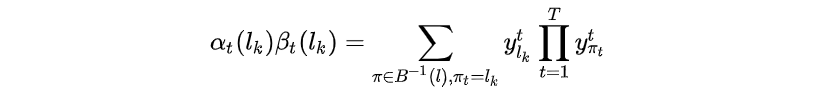


则有:
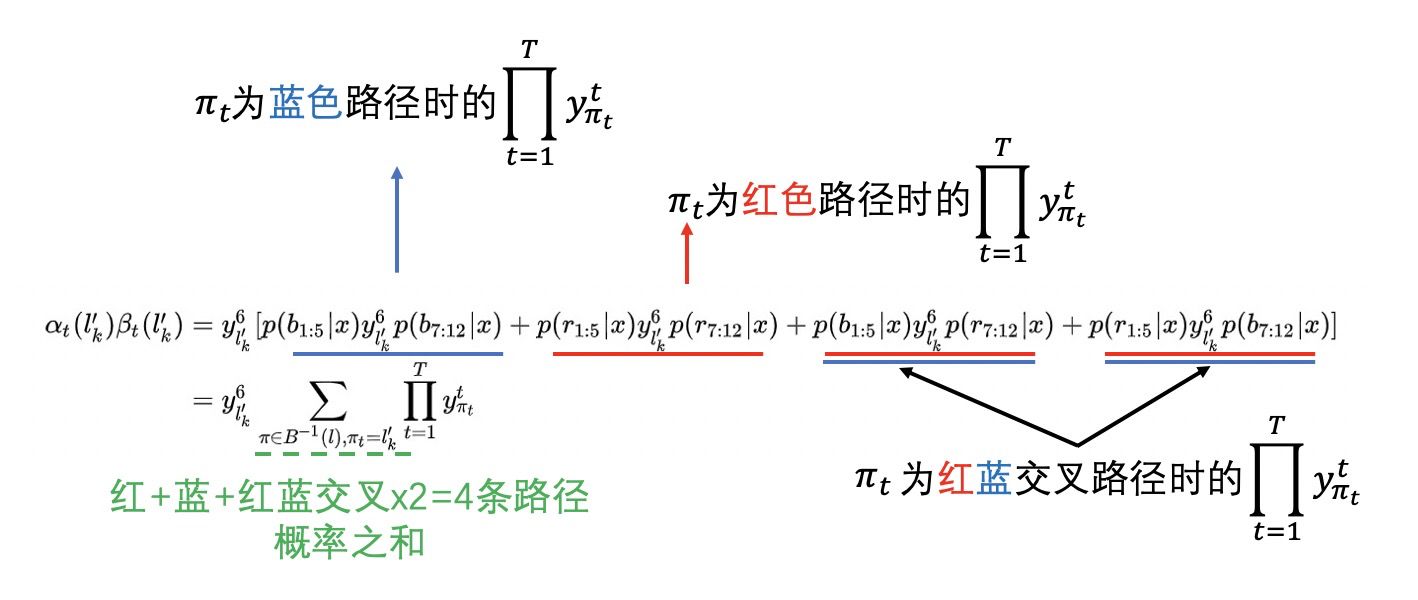
训练CTC

CTC编程接口
在Tensorflow中官方实现了CTC接口:
tf.nn.ctc_loss(labels,inputs,sequence_length,preprocess_collapse_repeated=False,ctc_merge_repeated=True,ignore_longer_outputs_than_inputs=False,time_major=True
)在Pytorch中需要使用针对框架编译的warp-ctc:https://github.com/SeanNaren/warp-ctc
2020.4更新,目前Pytorch已经有CTC接口:
torch.nn.CTCLoss(blank=0,reduction='mean',zero_infinity=False)CTC总结
CTC是一种Loss计算方法,用CTC代替Softmax Loss,训练样本无需对齐。CTC特点:
- 引入blank字符,解决有些位置没有字符的问题
- 通过递推,快速计算梯度
看到这里你也应该大致了解MFCC+CTC在语音识别中的应用了(图17来源)。

图17 MFCC+CTC在语音识别中的应用
CRNN+CTC总结
这篇文章的核心,就是将CNN/LSTM/CTC三种方法结合:
- 首先CNN提取图像卷积特征
- 然后LSTM进一步提取图像卷积特征中的序列特征
- 最后引入CTC解决训练时字符无法对齐的问题
即提供了一种end2end文字图片识别算法,也算是方向的简单入门。
特别说明
一般情况下对一张图像中的文字进行识别需要以下步骤
- 定位文稿中的图片,表格,文字区域,区分文字段落(版面分析)
- 进行文本行识别(识别)
- 使用NLP相关算法对文字识别结果进行矫正(后处理)
本文介绍的CRNN框架只是步骤2的一种识别算法,其他非本文内容。CTC你学会(fei)了么?
这篇关于一文读懂CRNN+CTC(Connectionist Temporal Classification)文字识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








