ctc专题

tensorflow LSTM+CTC实现端到端的不定长数字串识别
转载地址: https://www.jianshu.com/p/45828b18f133 上一篇文章tensorflow 实现端到端的OCR:二代身份证号识别实现了定长18位数字串的识别,并最终达到了98%的准确率。但是实际应用场景中,常常需要面对无法确定字串长度的情况,这时候除了需要对识别字符模型参数进行训练外,还需要对字符划分模型进行训练,本文实现了上文提到的方法2,使用LST

lstm+ctc 实现ocr识别
转载地址: https://zhuanlan.zhihu.com/p/21344595 OCR是一个古老的研究领域,简单说就是把图片上的文字转化为文本的过程。在最近几年随着大数据的发展,广大爬虫工程师在对抗验证码时也得用上OCR。所以,这篇文章主要说的OCR其实就是图片验证码的识别。OCR并不是我的研究方向,我研究这个问题是因为OCR是一个可以同时用CNN,RNN两种算法都可以很好解决的

2-D CTC Loss
2D-CTC for Scene Text Recognition,1-D CTC Loss参考CTC Loss和Focal CTC Loss Motivation 普通的CTC仅支持1-d,但是文字识别不像语音识别,很多时候文字不是水平的,如果强行“压”到1d,对识别影响很大,如下图所示 Review 1-D CTC 首先对alphabeta进行扩充,加入blank符号,然后定义

CTC Loss和Focal CTC Loss
最近一直在做手写体识别的工作,其中有个很重要的loss那就是ctc loss,之前在文档识别与分析课程中学习过,但是时间久远,早已忘得一干二净,现在重新整理记录下 本文大量引用了- CTC Algorithm Explained Part 1:Training the Network(CTC算法详解之训练篇),只是用自己的语言理解了一下,原论文:Connectionist Temporal

CTC,RNN-Transducer, LAS
1、CTC ( Connectionist Temporal Classification) 网络结构 参考地址: CTC白话参考地址 其中CTC-loss 部分使用到了动态规划的思想。 大目标是: m i n ∑ B ( π ) = z ∏ t = 1 T y π t t m i n ∑ B ( π ) = z ∑ t = 1 T l o g ( y π t t ) min \su


基于CTPN(tensorflow)+CRNN(pytorch)+CTC的不定长文本检测和识别
转发来源:https://swift.ctolib.com/ooooverflow-chinese-ocr.html chinese-ocr 基于CTPN(tensorflow)+CRNN(pytorch)+CTC的不定长文本检测和识别 环境部署 sh setup.sh 使用环境: python 3.6 + tensorflow 1.10 +pytorch 0.4.1 注:CPU环境

【机器学习】基于CTC模型的语音转换可编辑文本研究
1.引言 1.1语音识别技术的研究背景 1.1.1.语音识别技术的需求 语音识别技术的研究和发展,对于提升人类与机器的交互方式具有深远的影响。首先,它极大地提高了工作效率和便利性。通过语音指令控制设备,用户可以更快捷地完成任务,无需手动输入或操作。例如,在办公环境中,语音识别可以快速完成文档编辑、邮件发送等任务;在家庭中,智能家居设备响应语音指令,实现灯光、温度等的调节。这种交互方式不仅节省

【CTC】CTC1D原理/代码/资料+2D CTC LOSS
1 1D CTC 1.1 简介 就不写了 1.2 核心思想 和大多数有监督学习一样,CTC 使用最大似然标准进行训练。 给定输入 x,输出 l 的条件概率为: 其中,B-1(l)表示了长度为 T 且示经过 B 结果为 l 字符串的集合。 CTC 假设每一步输出的概率是(相对于输入)条件独立的,因此有: p ( π ∣ x ) = ∏ y π t t , ∀ π ∈ L ′ T p
图像验证码识别,字母数字汉子均可cnn+lstm+ctc
图形验证码如下: 训练两轮时的准确率:上边显示的是未识别的 config_demo.yaml System:GpuMemoryFraction: 0.7TrainSetPath: 'train/'TestSetPath: 'test/'ValSetPath: 'dev/'LabelRegex: '([\u4E00-\u9FA5]{4,8}).jpg'MaxTextLenth:

文字识别 Optical Character Recognition,OCR CTC STN
文字识别 Optical Character Recognition,OCR 自然场景文本检测识别技术综述 将图片上的文字内容,智能识别成为可编辑的文本。 场景文字识别(Scene Text Recognition,STR) OCR(Optical Character Recognition, 光学字符识别)传统上指对输入扫描文档图像进行分析处理,识别出图像中文字信息。场景文字识别(

深度学习,CRNN+CTC和Attention OCR你更青睐哪一种?
深度学习在OCR领域的应用已经取得了瞩目的成果,而选择合适的算法对于提升OCR的识别准确率至关重要。在众多算法中,CRNN和Attention OCR犹如两颗璀璨的明珠,备受瞩目。 CRNN,这位结合了卷积神经网络(CNN)和循环神经网络(RNN)的深度学习“大师”,擅长于处理OCR任务中的序列识别。它如同一位细心的画家,先用CNN捕捉图像的精髓,再用RNN勾勒出特征的轮廓,最后通过连接时序

一文读懂CRNN+CTC(Connectionist Temporal Classification)文字识别
先总结一把CTC,下面文档太长: CTC是一种Loss计算方法,用CTC代替Softmax Loss,TF和pytorch都有对CTC的实现,从而解决OCR或者语音识别中序列对齐的问题。CTC特点: 引入blank字符,解决有些位置没有字符的问题通过递推,快速计算梯度 - CTC在递推最终概率的时候, 使用前向后向算法,类似HMM中的前向后向算法 - CTC在最终求解的时候,使用bea
解决flume导入hdfs时:java.lang.NoClassDefFoundError: com/ctc/wstx/io/InputBootstrapper
首先,从hadoop的安装目录下,找到以下jar包,拷贝到flume的安装目录bin下。然后再执行flume配置 以下各依赖包版本根据hadoop版本而变 commons-configuration-1.6.jarhadoop-auth-2.7.2.jarhadoop-common-2.7.2.jarhadoop-hdfs-2.7.2.jarcommons-io-2.4.jarhtra
Tensorflow的tf.nn.ctc_loss经常遇到的两个问题:
1.CTC Loss Error: invalidArgumentError: Not Enough time for target transition sequence. —— 标签的长度大于sequence length,比如ocr识别中原始图像经过卷积倍,池化后time step 维度减小,小于标签的长度。例如,输入矩阵长度为4,你得标签文本为‘world’长度为5,矩阵最多只能包含4个
【项目实践】中文文字检测与识别项目(CTPN+CRNN+CTC Loss原理讲解)
目录 OCR——简介 1、CTPN原理——文字检测 1.1、简介 1.2、CTPN模型创新点 1.3、CTPN与RPN网络结构的差异 1.4、CTPN网络结构 1.5、如何通过FC层输出产生Text proposals? 1.6、竖直Anchor定位文字位置 1.7、文本线构造算法 1.8、CTPN的训练策略 1.9、CTPN小结 2、CRNN网络 2.1、CRNN 介绍
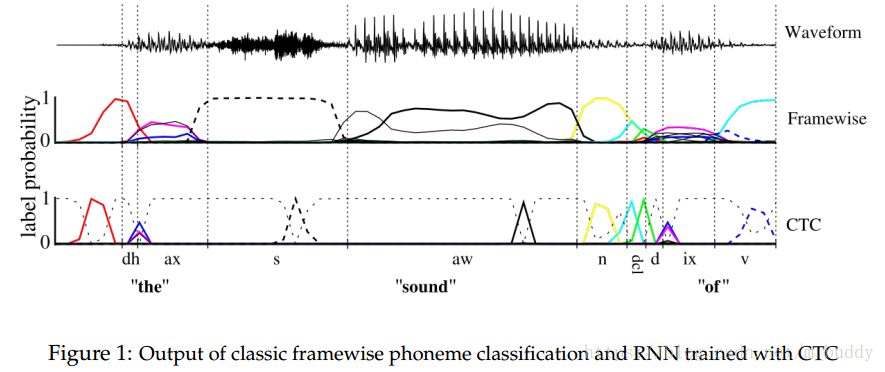
CTC(Connectionist Temporal Classification)论文笔记
1. 思想 序列学习任务需要从未分割的输入数据中预测序列的结果。HMM模型与CRF模型是序列标签任务中主要使用的框架,这些方法对于许多问题已经获得了较好的效果,但是它们也有缺点: (1)需要大量任务相关的知识,例如,HMM中的状态模型,CRF中的输入特征选择; (2)需要有独立性假设作为支撑; (3)对于标准的HMM模型,它是生成式的,但是序列标签时判别式的。 RNN网络除了出入与输出的表达方
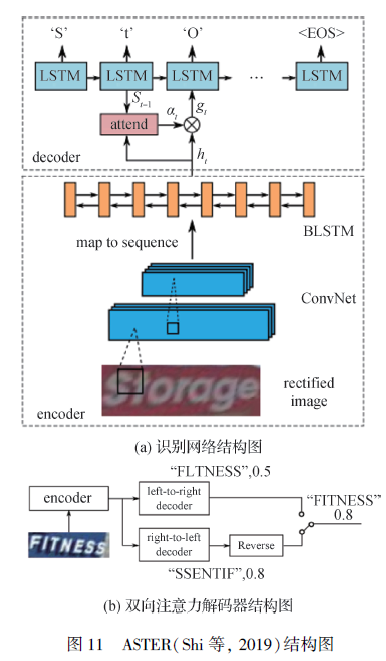
【文本检测与识别白皮书-3.2】第二节:基于注意力机制和CTC的场景文本识别方法的对比
本节内容给出基于CTC和基于注意力机制的两种场景文本识别方法,并给出各自的优势与局限性 3.2.2.1 基于CTC的无需分割的场景文本识别方法 基于时序连接序列(CTC)的自然场景文本识别算法。 时序连接序列(CTC)算法早期由Graves等人(2016)提出,用以训练循环神经网络(Cho 等,2014;Hochreiter 和Schmidhuber,1997),并直接标记未分割的特征

CTC Loss 数学原理讲解:Connectionist Temporal Classification
文章目录 1、CTC Loss 出现的背景例1:用于图像文本识别的CRNN网络例2:语音识别 2、CTC Loss 的总体思想3、Forward-Backward 算法3.1 合法路径的约束条件3.2 Forward-Backward 算法的数学推导 4、CTC 的训练(目标函数求导)5、解码算法6、CTC Loss 的优缺点 CTC Loss 是一种不需要数据对齐的,广泛用于图
使用CTC进行序列建模
可以先参考 https://blog.csdn.net/luodongri/article/details/77005948 ,再进行下面的阅读。 下面是连结时序分类(Connectionist Temporal Classification,CTC)的一个可视化指导图,CTC是一种用于在语音识别,手写识别和其他序列问题中训练深度神经网络的算法。 CTC的工作原理 1. 引言
【AI实战】手把手教你文字识别(识别篇:LSTM+CTC, CRNN, chineseocr方法)
文字识别是AI的一个重要应用场景,文字识别过程一般由图像输入、预处理、文本检测、文本识别、结果输出等环节组成。 其中,文本检测、文本识别是最核心的环节。文本检测方面,在前面的文章中已介绍过了多种基于深度学习的方法,可针对各种场景实现对文字的检测,详见以下文章: 【AI实战】手把手教你文字识别(检测篇:MSER、CTPN、SegLink、EAST等方法) 【AI实战】手把手教你文字识

CNN+GRU+CTC实现不定长字符串识别(一)
CNN+GRU+CTC进行人民币编码识别 背景使用方法源码训练和预测 inf:loss错误 背景 来自于TinyMind的一个比赛,名为人民币面值及编码识别 地址:https://www.tinymind.cn/competitions/47 本篇文章的前提是已经将编码定位并切割下来,图片中只有相应的编码,样子如下: 当然不是这样也可以,随便什么训练集,如果没有的话可以参考我

CTC算法基本原理解释
语音识别中的CTC算法的基本原理解释 目前主流的语音识别都大致分为特征提取,声学模型,语音模型几个部分。目前结合神经网络的端到端的声学模型训练方法主要CTC和基于Attention两种。 本文主要介绍CTC算法的基本概念,可能应用的领域,以及在结合神经网络进行CTC算法的计算细节。 CTC算法概念 CTC算法全称叫:Connectionist temporal classification
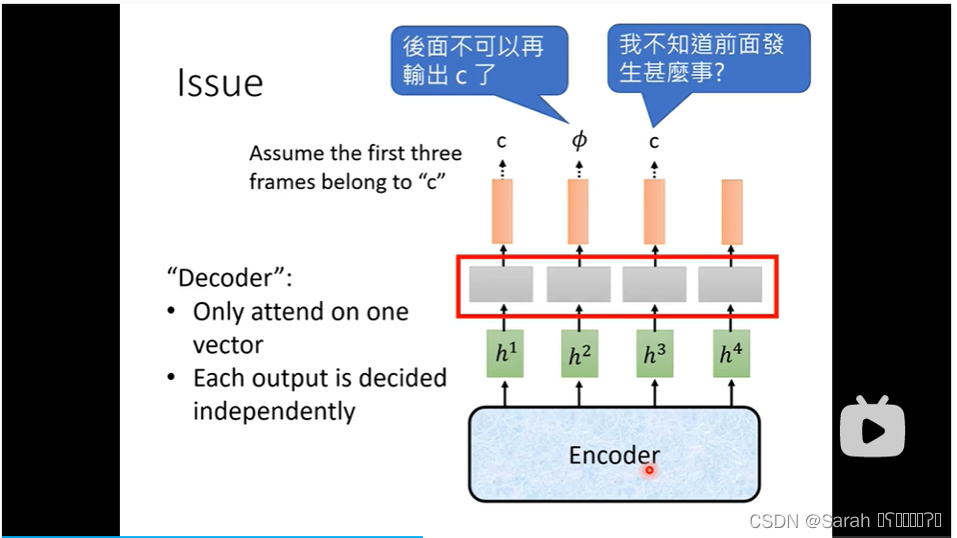
Speech Recognition模型:Connectionist Temporal Classification(CTC)
在上一篇讲的speech recognition模型 LAS 中,我们提到,LAS由encoder 和 decoder 组成,其在做speech recognition任务时,有一个很大的缺点,即:无法做到“边听边翻译”,换言之,在使用LAS做翻译时,需要将“原文"全部输入模型,才可得到译文(这里的译文 指 将 语音 转为 文字)。 本节所讲的模型CTC很好的克服了LAS的这一弱点,它可以实时的

递归神经网络 GRU+CTC+CNN 教会验证码识别
用递归神经网络采用端到端识别图片文字,递归神经网络大家最早用 RNN ,缺陷造成梯度消失问题;然后采用了 LSTM,解决 RNN 问题,并且大大提高准确率;现在效果最好的是 GRU,比 LSTM 准确率更高,训练时间大大缩短。本 Chat 的例子用验证码来做识别,可用于文字识别、车牌识别、手写字识别、各种证件识别。 本次 Chat ,我将分享如下内容: RNN 原理,递归的基础,重点讲向前传播