本文主要是介绍Ultra Fast Structure-aware Deep Lane Detection的训练实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Ultra Fast Structure-aware Deep Lane Detection的训练实战
1、模型介绍
论文
知乎
代码
CULane数据集简介
2、基于CULane数据集格式的训练
2.1、video to img
import glob
import os
import cv2# --------视频转图像-----------------------------------------
def video2image(video_path, save_path, index):if not os.path.exists(save_path): os.makedirs(save_path)cap = cv2.VideoCapture(video_path)img_num = 0while 1:print(index)ret, frame = cap.read()if img_num >2000:breakif ret == False:breaksave_name = os.path.join(save_path, str(index) + ".jpg")cv2.imwrite(save_name, frame)index += 1img_num +=1cap.release()return indexif __name__ == "__main__":video_path = r"Ultra-Fast-Lane-Detection\dataset\video"video_list = os.listdir(video_path)print(video_list)index = 0for i in range(len(video_list)):video_load = os.path.join(video_path, video_list[i])save_path = os.path.join(r"Ultra-Fast-Lane-Detection\dataset\img", video_list[i].split(".")[0])print(save_path)index = video2image(video_load,save_path,index)
2.2 Labelme标注
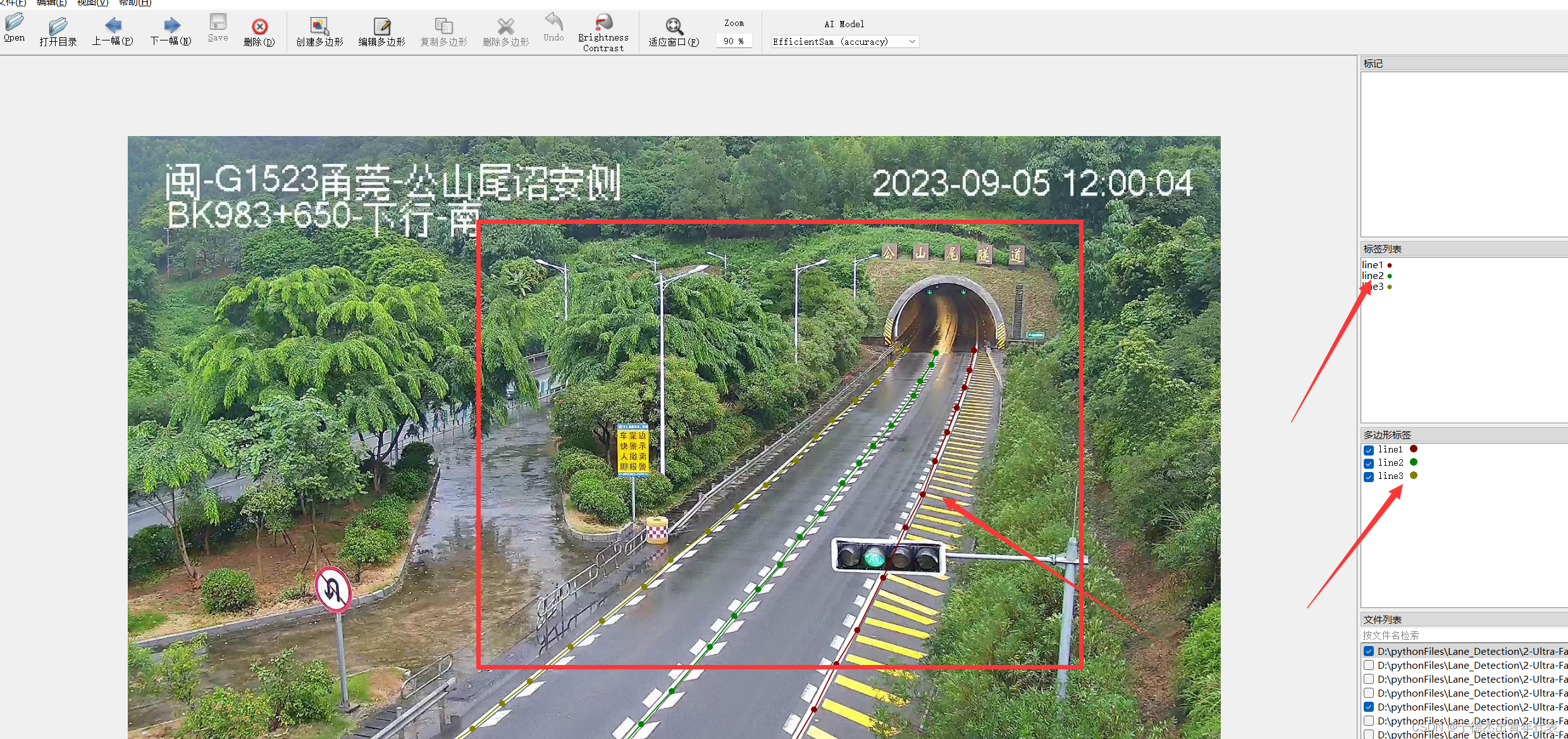
2.3 json转label图片
单张图像的代码位于:anaconda2\envs\labelme\Lib\site-packages\labelme\cli\json_to_dataset.py;
批量使用:
import os
import globos.chdir("B:\Anaconda\envs\Lane_Detection\Lib\site-packages\labelme\cli")
path1 = r"conda activate your env"
os.system(path1)json_file = r'your json file' # 文件路径
json_list = glob.glob("%s/*.json" % (json_file))
for i in json_list:path11 = r"python json_to_dataset.py "path22 = path11 + ios.system(path22)结果如图所示:
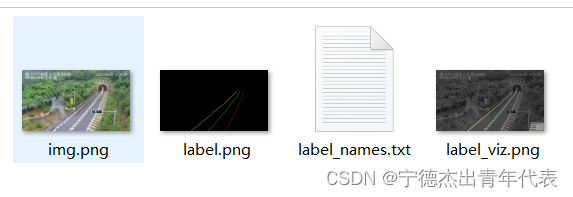
2.4 基于json生成点坐标的文本文件
import os
import json
import numpy as npdir_json = r'your json path' # json存储的文件目录
dir_txt = r'your txt save path' # txt存储目录
if not os.path.exists(dir_txt):os.makedirs(dir_txt)
list_json = os.listdir(dir_json)def json2txt(path_json, path_txt): # 可修改生成格式with open(path_json, 'r') as path_json:jsonx = json.load(path_json)with open(path_txt, 'w+') as ftxt:for shape in jsonx['shapes']:label = str(shape['label']) + ' 'xy = np.array(shape['points'])strxy = ''for m, n in xy:m = int(m)n = int(n)# print('m:',m)# print('n:',n)strxy += str(m) + ' ' + str(n) + ' 'label = strxyftxt.writelines(label + "\n")for cnt, json_name in enumerate(list_json):path_json = os.path.join(dir_json, json_name)print(path_json)path_txt = os.path.join(dir_txt, json_name.replace('.json', '.lines.txt'))print(path_txt)json2txt(path_json, path_txt)
结果如图所示:
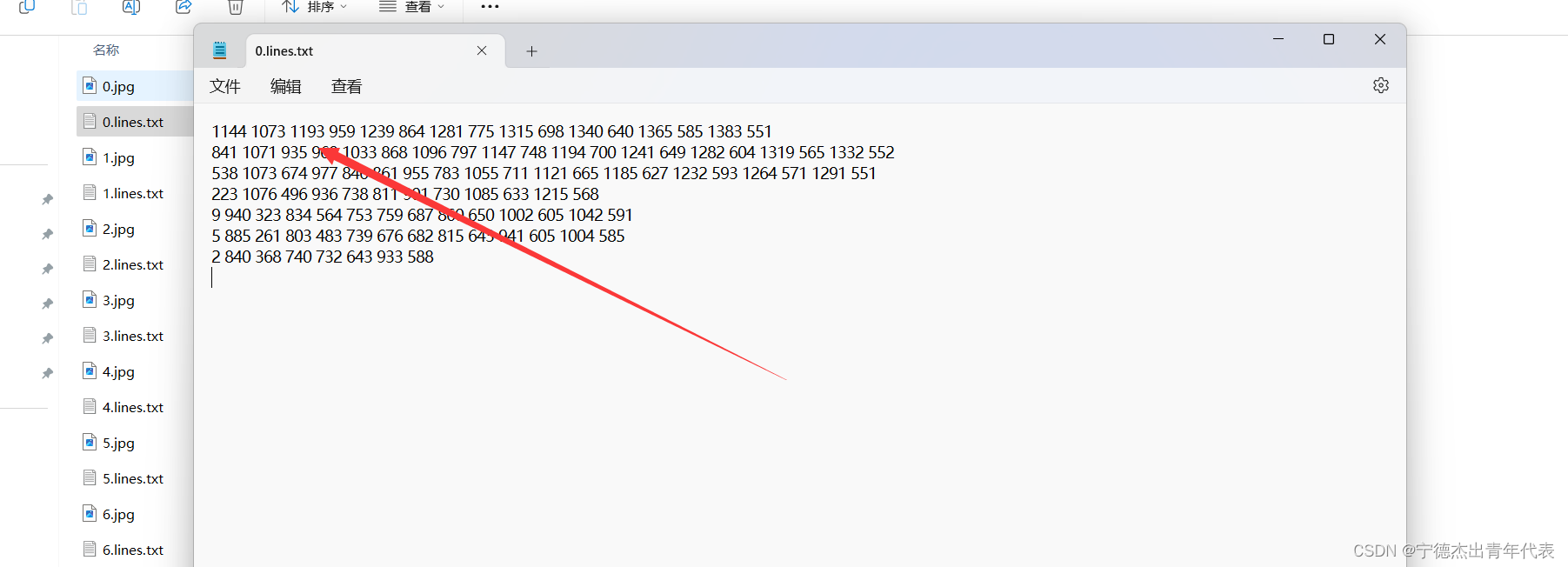
2.5 train.txt\test.txt\val.txt制作
import osfolder_path = "img/val_img/" # 文件夹路径
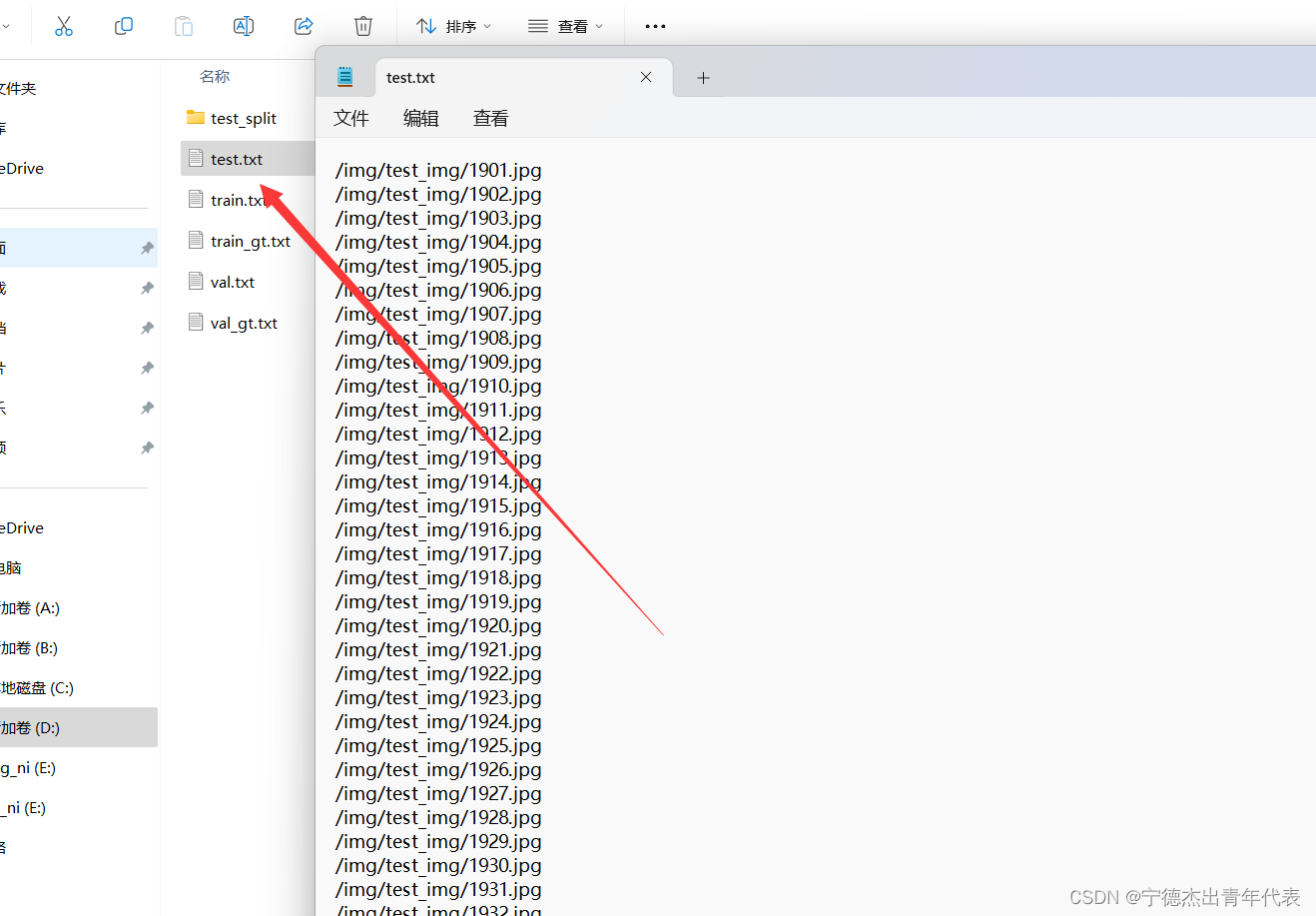
txt_file_path = "list/val.txt" # 输出txt文件路径with open(txt_file_path, "w") as txt_file:for file_name in os.listdir(folder_path):if file_name.endswith(".jpg"):file_path = "/"+folder_path+file_nametxt_file.write(file_path + "\n") # 将文件名写入txt文件,每个文件名占一行
效果如图所示:
2.5 label_Seg文件夹的制作
将2.3步骤生成的文件夹的里的label.png重命名并保存到其它文件夹
import os
import glob
import shutil
save_path = r"D:\pythonFiles\Lane_Detection\2-Ultra-Fast-Lane-Detection\dataset\CULane\laneseg"seg_img_path = r"D:\pythonFiles\Lane_Detection\2-Ultra-Fast-Lane-Detection\dataset\CULane\laneseg\all"img_list = glob.glob("%s/*/*.png" % (seg_img_path))for img_path in img_list:if img_path.split("\\")[-1] == "label.png":num = img_path.split("\\")[-2].split("_")[0]new_name = num + ".png"save_name = os.path.join(save_path, new_name)shutil.copy(img_path, save_name)
效果如图所示:

2.6 制作train_gt.txt\val_gt.txt
import osfolder_path = "img/train_img/" # 文件夹路径
txt_file_path = "list/train_gt.txt" # 输出txt文件路径
seg_path = "laneseg/train_img/"
with open(txt_file_path, "w") as txt_file:for file_name in os.listdir(folder_path):if file_name.endswith(".jpg"):file_path = "/"+folder_path+file_nameprint(file_path)txt_file.write(file_path + " ") # 将文件名写入txt文件file_gt_path = "/"+seg_path+file_name.split(".")[0]+".png"print(file_gt_path)txt_file.write(file_gt_path + " ")#txt_file.write("1 1 1 1\n")
效果如图所示

2.7 最终数据集结构
1 CULane
1.1 img

1.2 laneseg
1.3 list
3 开始训练
3.1 configs/culane.py


3.2 开始训练
python train.py configs/culane.py
3.3 测试
把之前生成的test.txt复制到CULane数据集的一级目录下
python test.py configs/culane.py --test_model weights/ep048.pth --test_work_dir ./tmp
4 参考
CSDN博客1
CSDN博客2
CSDN博客3
CULane数据集介绍
CSDN博客4
这篇关于Ultra Fast Structure-aware Deep Lane Detection的训练实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






