本文主要是介绍【三维编辑】Seal-3D:基于NeRF的交互式像素级编辑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

文章目录
- 摘要
- 一、引言
- 二、方法
- 2.1.基于nerf的编辑问题概述
- 2.2.编辑指导生成
- 2.3.即时预览的两阶段学生训练
- 三、实验
- 四、代码(未完...)
- 总结
项目主页: https://windingwind.github.io/seal-3d/
代码:https://github.com/windingwind/seal-3d/
论文: https://arxiv.org/pdf/2307.15131
摘要
随着隐式神经表征(即NeRF)的流行,迫切需要编辑方法与隐式3D模型交互,如后处理重建场景和3D内容创建。之前的工作在编辑的灵活性、质量和速度方面都受到了限制,为了能够直接响应编辑指令并立即更新。提出的Seal-3D 它允许用户以像素级和自由的方式使用各种NeRF类主干来编辑NeRF模型,并立即预览编辑效果。为了实现这些效果,我们 提出的代理函数将编辑指令映射到NeRF模型的原始空间,以及采用 局部预训练和全局微调的师生训练策略,解决了这些挑战。建立了一个NeRF编辑系统来展示各种编辑类型,可以以大约1秒的交互速度实现引人注目的编辑效果。
一、引言
得益于高重建精度和相对低的内存消耗,NeRF及其变体在许多3D应用中显示出了巨大的潜力,如3D重建、新视图合成和虚拟/增强现实。当前迫切需要人类友好的编辑工具来与这些3D模型交互。由于捕获数据的噪声和重建算法的局限性,从现实世界中重建的对象很可能包含伪影。
之前的作品曾尝试编辑由NeRF表示的3D场景,包括对象分割[19,41Edit NeRF]、对象去除[18 Nerf-in]、外观编辑[Palettenerf 13,Nerf-editing25]、对象混合[Template nerf7]等,主要集中在粗粒度的对象级编辑上,其收敛速度不能满足交互式编辑的要求。最近的一些方法[Neumesh 45,Nerf-editing 5]通过引入网格作为编辑代理,将NeRF的编辑转换为网格编辑。这需要用户操作一个额外的网格划分工具,这限制了交互性和用户友好性。
点云、纹理网格和occupancy volume等 显式3D表示,存储对象和场景的显式几何结构;隐式表示使用神经网络来查询3D场景的特征,包括几何和颜色。现有的三维编辑方法,以基于网格的表示为例,可以通过替换与目标对象的表面面积和对象纹理对应的顶点来改变对象的几何图形。如果视觉效果和潜在表征之间没有明确可解释的对应关系,编辑隐式3D模型是间接的和具有挑战性的。此外,很难在场景的局部区域找到隐式的网络参数,这意味着网络参数的适应可能会导致不希望发生的全局变化。这给细粒度编辑带来了更多的挑战。
本文提出了一种交互式像素级编辑的三维场景隐式神经表示方法和系统,Seal-3D(借用了软件Adobe PhotoShop )。如图1所示,编辑系统的密封工具包括四种编辑:1)边界箱工具。它可以转换和缩放边界框内的东西,就像复制-粘贴操作一样。2)刷子工具。它在选定的区域上油漆指定的颜色,并可以增加或减少表面高度,就像油漆刷或擦伤器一样。3)固定工具。它允许用户自由地移动一个控制点,并根据用户的输入影响其邻居空间。4)使用颜色的工具。它会编辑对象表面的颜色
首先,为了建立显式编辑指令与隐式网络参数更新之间的对应关系,我们提出了将目标三维空间(由用户从交互式GUI编辑指令决定)映射到原始三维场景空间的代理功能,以及师生精馏策略,利用代理功能从原始场景获得的相应内容监督来更新参数。其次,为了实现局部编辑,即减轻局部编辑效应对非局部隐式表示下全局三维场景的影响,我们提出了一个两阶段的训练过程:预训练阶段只更新编辑区域,同时冻结后续MLP解码器以防止全局退化,微调阶段更新嵌入网格和MLP解码器的全局光度损失。通过这种设计,预训练阶段更新了局部编辑特性(预训练可以非常快速地收敛,并且只在大约1秒内呈现局部编辑效果),而微调阶段将局部编辑区域与未编辑空间的全局结构和未编辑空间的颜色混合起来,以实现视图的一致性。
二、方法
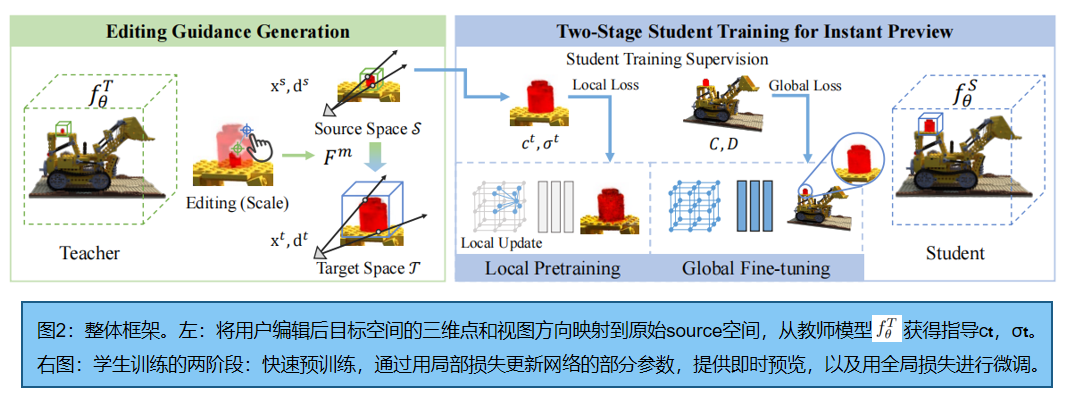
交互式像素级编辑的Seal-3D,框架如图2所示,它包括一个像素级的代理映射函数、一个师生训练框架和一个在该框架下的学生NeRF网络的两阶段训练策略。我们的编辑工作流从 代理函数 开始,它根据用户指定的编辑规则映射查询点和射线方向。然后是一个NeRF-to-NeRF教师-学生蒸馏框架,其中一个具有编辑几何和颜色映射规则的教师模型监督学生模型的训练(3.2节)。交互式细粒度编辑的关键是对学生模型的两阶段训练(3.3节)。额外的预训练阶段,对教师模型中编辑空间内的点、射线方向和推断的GT进行采样、计算和缓存;只有具有局部性的参数被更新,导致全局变化的参数被冻结。预训练之后,全局训练阶段 finetune 学生模型。
2.1.基于nerf的编辑问题概述
2.1.1 NeRF 基础知识,请见我的博客:【三维重建】NeRF原理+代码讲解
2.1.2 基于nerf编辑的挑战
三维场景由网络参数隐式表示,缺乏可解释性,难以操纵。在场景编辑方面,很难在显式编辑指令和网络参数的隐式更新之间找到一个映射。以前的工作试图通过几种受限的方法来解决这个问题:
NeRF-Editing和NeuMesh引入了一个网格支架作为几何代理来辅助编辑,这将NeRF编辑任务简化为网格修改。虽然符合现有的基于网格的编辑,但编辑过程需要提取一个额外的网格,这很麻烦。此外,编辑后的几何图形高度依赖于网格代理结构,使得在表示这些空间时很难编辑不容易或不能用网格表示的空间是隐式表示的一个关键特征。Liu等人[ Editing conditional radiance fields] 设计了额外的颜色和形状损失来监督编辑。然而,它们的设计loss 仅发生在二维光度空间中,这限制了三维NeRF模型的编辑能力。
2.2.编辑指导生成
我们的设计将 NeRF编辑看作一个知识蒸馏的过程。给定一个预先训练的NeRF网络拟合一个特定的场景作为教师网络,我们用预先训练的权值初始化一个额外的NeRF网络作为学生网络。教师网络 fθT 根据用户输入的编辑指令生成编辑指导,而学生网络 fθS 通过从教师网络输出的编辑指导中提取编辑知识进行优化。
首先,从交互式NeRF编辑器中读取用户编辑指令作为像素级信息。源空间S⊂R3 为原始NeRF模型的三维空间,目标空间T⊂R3 为编辑后的NeRF模型的三维空间。目标空间T通过Fm 扭曲到原始空间S:T→S。Fm 根据以下编辑规则对目标空间内的点及其相关方向进行变换:函数中,每个三维点和观察方向的“伪”期望编辑效果cT,σT ,可以通过查询教师NeRF模型 fθT 。过程可表示为:
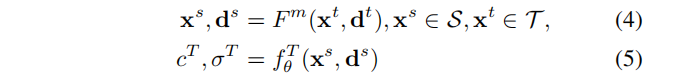
其中,xs、ds 表示源空间点的位置和方向,xt、dt 表示目标空间点的位置和方向。简单起见,此过程可定义为教师模型的预测:Ft := fθT ◦ Fm:(xt,dt)→(cT,σT)。
推理结果cT,σT 模拟编辑后的场景,作为网络优化阶段由学生网络提取信息的教师标签。Fm 的映射规则可以根据任意的编辑目标进行设计(本文为4种类型的编辑)。
- 边界形状工具(Bounding shape tool)
3D编辑软件常见功能,包括 复制粘贴、旋转和调整大小。用户提供一个边界形状来指示要编辑的原始空间S,并旋转、翻转和缩放边界框,以指示目标效果。然后,目标空间 T 和映射函数 Fm 由接口进行解析:

其中R是旋转,S是尺度,cs,ct 分别是S,T的中心.。该工具甚至支持跨场景对象转移,这可以通过引入转移对象的NeRF作为一个额外的教师网络,负责目标区域内的部分教师推理过程。图7是效果图
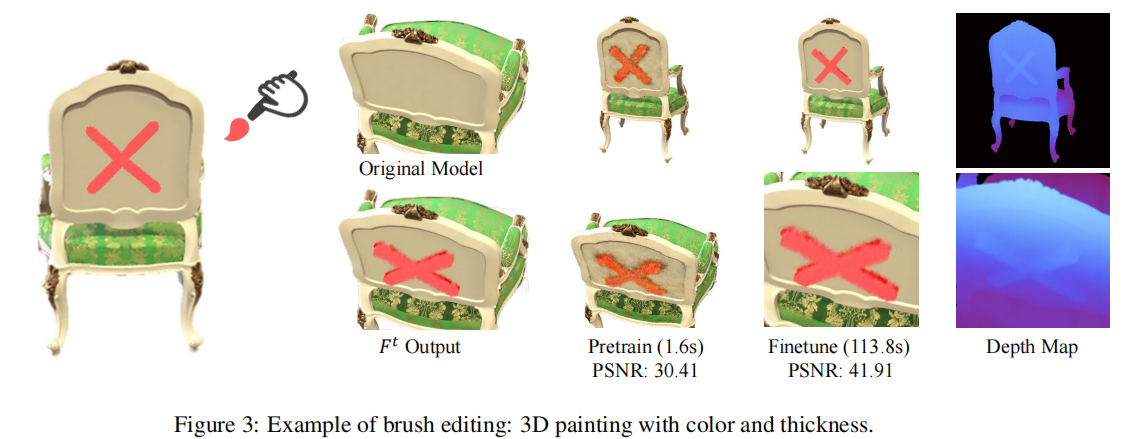
- 刷子工具(Brushing tool)
类似于造型刷,提升或下降绘制的表面。用户使用笔刷画出草图,通过将射线投影在刷过的像素上生成 S。笔刷标准值 n 和压力值 p(·)∈[0,1] 由用户定义,它决定了映射:
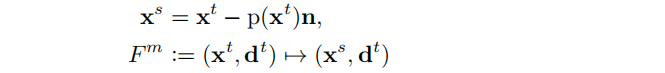
- 锚工具(Anchor tool)
用户定义一个控制点xc和一个平移向量t。xc 周围的区域将被平移函数拉伸(·;xc、t)拉伸。那么这个映射是它的倒数:
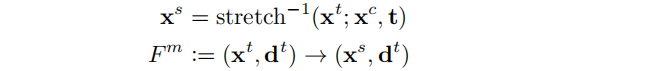
拉伸的显式表达式(·;xc、t)请参考补充材料。
- 颜色工具(Color tool)
通过颜色空间映射(单一颜色或纹理)编辑颜色(空间映射相同)。我们直接在HSL空间中映射网络输出的颜色,这有助于提高颜色的一致性。该方法能够在修改后的表面上保留阴影细节(例如阴影)。我们通过将原始表面颜色上的亮度(在HSL空间中)偏移量转移到目标表面颜色来实现这一点。这个阴影保存策略的实现细节在补充中提出。
2.3.即时预览的两阶段学生训练
蒸馏训练策略,直接应用等式累积的像素值 C ^ \hat{C} C^、 D ^ \hat{D} D^之间的photometric 损失,教师模型为学生模型提供 编辑指导。该训练过程收敛速度较慢(≈30s或更长)因而采用两阶段的训练策略:第一阶段的目标是立即收敛(在1秒内),这样一个粗编辑结果就可以立即作为预览呈现给用户;第二阶段进一步细化粗预览以获得最终的细化。
1. 即时预览的局部预训练。通常,编辑空间相对较小,对全局光度损失的训练导致收敛慢。为实现编辑即时预览,我们在全局训练开始前采用了局部预训练:
1)均匀采样目标空间内一组点 X⊂T 和单位球上的方向D,将其输入教师推理过程Ft ,得到教师标签cT、σT,并提前缓存;
2)通过局部预训练损失对学生网络进行训练:
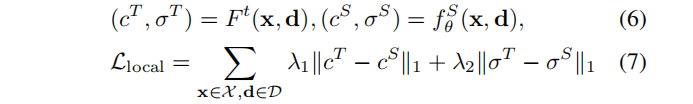
其中,cS,σS是学生网络预测的采样点(x∈X)的颜色和密度,cT,σT 是缓存的教师标签。预训练只需1秒,学生网络会显示出与编辑说明一致的合理的颜色和形状。
然而,由于非局部隐式神经网络,只对编辑区域的局部点进行训练,可能会导致其他与编辑无关的全局区域的退化。我们观察到,在混合隐式表示(如Intant NGP)中,局部信息主要存储在位置嵌入网格中,而后续的MLP对全局信息进行解码。因此,在这个阶段,MLP解码器的所有参数都被冻结,以防止全局退化。见实验插图12

2. 全局微调。
经过预训练后,我们继续微调 fθS,将粗预览细化为完全收敛的结果。这个阶段类似于标准的NeRF训练,除了监督标签是由教师推理过程而不是图像像素生成的。
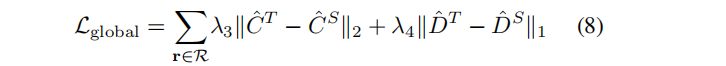
其中R表示小批中采样的射线集合。
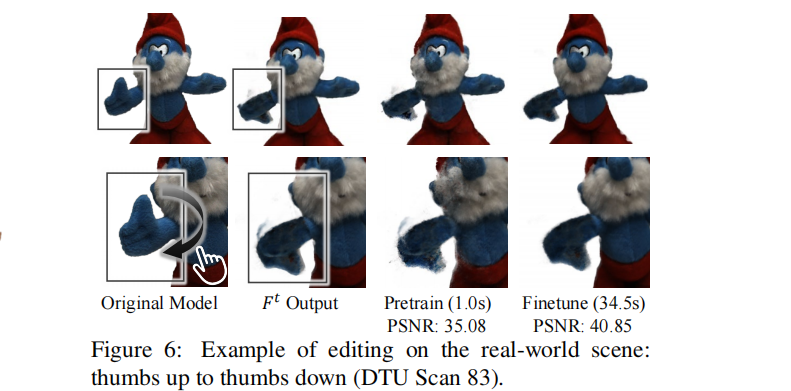
值得一提的是,学生网络能够产生比它所学习的教师网络质量更好的结果。这是因为教师推理过程中的映射操作可能会在伪GT中产生一些视图不一致的artifacts。然而,在蒸馏过程中,由于加强视图一致性稳健性的多视图训练,学生网络可以自动消除这些伪影,如图6所示。
三、实验
- 实验设置
实验采用 Instant-NGP作为编辑框架的NeRF骨干。设置λ1 = λ2 = 1,学习速率固定为0.05。在微调阶段,我们设置了λ3 = λ4 = 1,初始学习率为0.01。
训练数据选合成 NeRF Blender Dataset,以及真实世界捕获的 Tanks 和
Temples [12] and DTU [10] 数据集。
- 效果
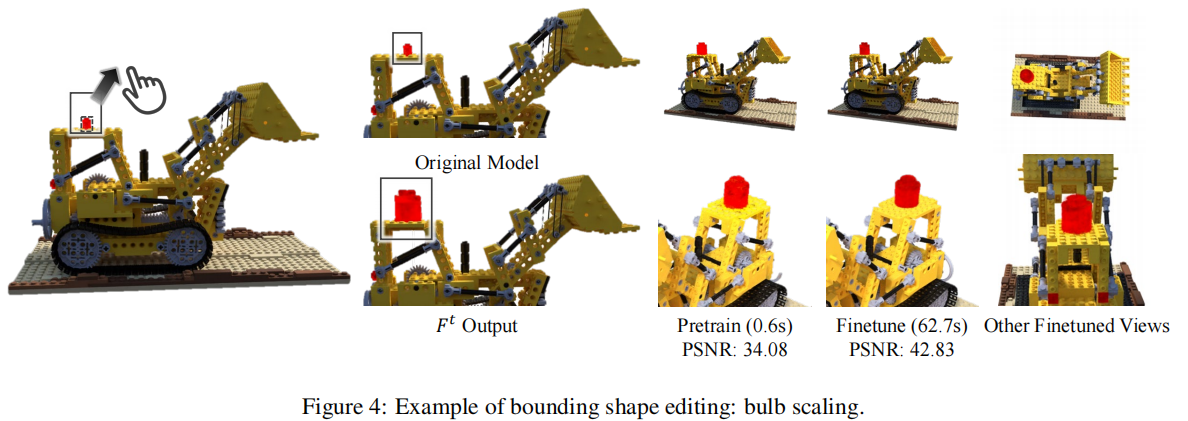
边界形状(图4和6)效果:
brushing 效果:
锚点(图5)和颜色(图1)效果:

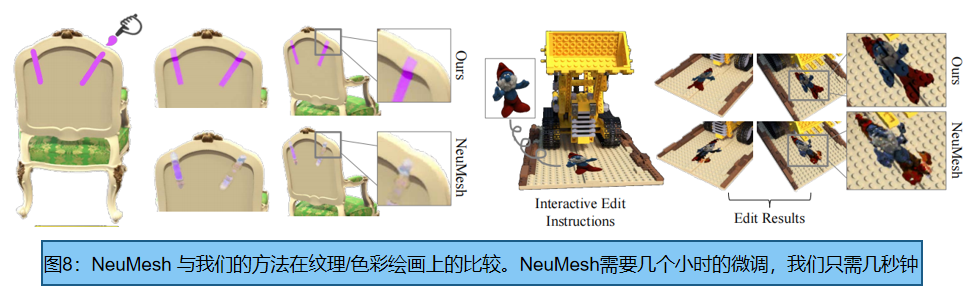
与NueMesh的对比:
四、代码(未完…)
渲染代码:nerf/rendering.py line256 函数run_cuda,得到射线的颜色和深度:
xyzs, dirs, deltas = raymarching.march_rays(n_alive, n_step, rays_alive, rays_t, rays_o, rays_d, self.bound, self.density_bitfield, self.cascade, self.grid_size, nears, fars, 128, perturb if step == 0 else False, dt_gamma, max_steps)
raymarching.march_rays调用了raymarching/raymarching.py 中line297的类: _march_rays(Function)的forward
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
这篇关于【三维编辑】Seal-3D:基于NeRF的交互式像素级编辑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






