本文主要是介绍利用深度学习解决生活中实际问题——卷积网络实现花卉分类识别(附带数据集,完整代码在最后),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
实验背景:随着深度学习技术的发展,计算机视觉在图像分类方面取得了巨大进展。通过使用深度学习模型,我们课上学习到的卷积神经网络,可以对图像进行高效准确的分类。可以为普通人提供了更便捷的途径来识别和学习植物。深度学习进行植物图像分类的意义在于提高了植物识别的准确性和效率,为人们提供了更多的便利和可能性。
实验意义:本次实验进行植物图像分类的意义在于帮助人们更好地理解和识别植物,尤其是对于那些对植物了解有限的人群。通过对洋甘菊、郁深金香、玫瑰、向日葵、蒲公英等植物图像进行分类,可以为植物学家、园艺爱好者和农业领域提供便利。这项技术还有助于环境保护,例如在监测和保护濒临灭绝的植物物种方面发挥作用。
数据集分析:本次实验中数据集文件名称为:flowers,数据集中数据图片会分为五类:洋甘菊(daisy)、郁金香(tulip)、玫瑰(rose)、向日葵(sunflower)、蒲公英(dandelion)。每个种类大约有800张照片。 照片分辨率不高,约为 320x240 像素。且在数据集文件夹中包含训练数据集和测试数据集。训练集(train)一共有4,317张花卉图片,测试集(test)一共有1,236张花卉图片。
导入相关模块以及必要的变量定义:
import os
import torch
from PIL import Image
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms #pytorch中的图像预处理包:pip3 install torchvision
from torchvision import datasets,models
from torch import nn#导入神经网络包nn(可用来定义和运行神经网络)
from torch import optim#导入优化器包
train_datadir='./flowers/train/' #指定数据集的文件路径
test_datadir='./flowers/test/'
batch_size =120 #小批量数据集的大小定义为40
learning_rate = 0.005 #梯度下降算法中用到的学习率(learning rate)。
#momentum = 0.5 #梯度下降算法中用到的冲量(momentum)
EPOCH = 10 #训练的轮数。对数据集进行预处理:
my_transform = transforms.Compose([transforms.Resize((224,224)), #对图像大小进行调整transforms.ToTensor(), #将图像转换为pytorch张量transforms.Normalize(mean=[0.485, 0.456, 0.406], #对图像进行标准化处理,将每个像素的数值按照指定的均值和标准差调整,适应模型训练std=[0.229, 0.224, 0.225])]) train_data = datasets.ImageFolder(root=train_datadir,transform=my_transform) #读取训练数据
test_data = datasets.ImageFolder(root=test_datadir,transform=my_transform) #读取测试数据集
#查看datasets.ImageFolder的输出
print(train_data.classes) #类名List
print(train_data.class_to_idx) #类名和标签构成的字典:(class_name,class_index)
print(train_data.imgs[0]) #数据集元组构成的List:(文件名,标签)
print(len(train_data),len(test_data)) #打印训练集和测试集规模加载数据:
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True) #随机抽取,形成小批量训练数据集,shuffle表示是否打乱
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False) #顺序抽取,形成小批量测试数据集
for step, (data, targets) in enumerate(train_loader): #enumerate将一个可迭代对象组合为一个索引序列,同时列出数据和数据的索引。这句话中step是训练数据集的索引print(data.size()) #数torch.Size([30, 3, 224, 224]) ,通道为3表示彩色图片print(targets.size()) #小批量数据集为400break定义卷积网络:
"""
卷积运算 使用花卉数据集分类数据集
"""
class Net(nn.Module):def __init__(self): #没有传参super(Net, self).__init__()self.conv1 = nn.Sequential( #打包第一个卷积,池化nn.Conv2d(3, 30, kernel_size=5), #kernel_size表示卷积核大小nn.ReLU(), #定义激活函数为relunn.MaxPool2d(kernel_size=2) )self.conv2 = nn.Sequential(nn.Conv2d(30, 20, kernel_size=5),nn.ReLU(),nn.MaxPool2d(kernel_size=2))self.fc = nn.Sequential( #打包全连接nn.Linear(20*53*53, 20),nn.ReLU(),nn.Linear(20, 5))def forward(self, x):# Xsize = x.size(0)x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大)x = self.conv2(x) # 再来一次x = x.view(-1,20*53*53) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320x = self.fc(x) #全连接return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)
模型实例化:
# 找到可以用于训练的 GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
#模型实例化
model = Net().to(device)
print(model)优化器损失函数实例化(在模型训练的时候,如果出现过拟合或者欠拟合,导致实验效果不理想,可以更换优化器,实现对模型进行调参)
n_feature = 3*224*224 #输入层神经元数(特征数)
n_hidden = [128,64] #隐藏层神经元数
n_output = 5 #输出层神经元数(类别数)
model = Net()
# SGD: 随机梯度下降
optimizer = optim.Adagrad(model.parameters(), lr=learning_rate)
# 针对分类问题的损失函数!
loss_func = nn.CrossEntropyLoss()正式训练模型(打印相应的信息,以及给出模型集外测试的准确率曲线图)
#正式训练# 精度计算函数
def accuracy(outputs, labels):pred = torch.max(outputs, 1)[1]rights = pred.eq(labels).sum() #统计模型中识别正确图片的个数return rights
"""
一轮训练函数
输入:当前训练轮数
"""
def train(epoch):for step, (data, targets) in enumerate(train_loader):# 网络前传 -> 计算损失 -> 清空梯度 -> 反向传播 -> 优化网络参数outputs = model(data)loss = loss_func(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()# 计算损失、训练集精度running_loss = loss.item() #训练数据的损失率acc = 100 * accuracy(outputs, targets) / data.shape[0] #训练数据的准确率if step % 35 == 34: # 不想要每一次都出loss,浪费时间,选择每30次输出一个损失和准确率print('[%d, %5d]:loss and acc on train: loss= %.3f , acc= %.2f %%' % (epoch + 1, step + 1, running_loss, acc))"""
一轮测试函数
输出:测试集的测试精度
"""
def test():correct = 0total = 0with torch.no_grad(): # 测试集不用算梯度for images, labels in test_loader:outputs = model(images)prediction = torch.max(outputs, 1)[1] total += labels.size(0) # 张量之间的比较运算correct += (prediction == labels).sum().item()acc = correct / total #测试集的正确率,集外精度print('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数return accif __name__ == '__main__':acc_list_test = []temp = 0for epoch in range(EPOCH):train(epoch) #调用训练轮acc_test = test() #调用测试轮acc_list_test.append(acc_test) #记录测试精度,方便打印if acc_test > temp: torch.save(model.state_dict(), 'flowers_model.pt') #保存最佳模型temp = acc_testplt.plot(acc_list_test)plt.xlabel('Epoch')plt.ylabel('Accuracy On TestSet')plt.show()模型加载与实际运用:
if __name__ =='__main__':# 找到可以用于训练的 GPUdevice = "cuda" if torch.cuda.is_available() else "cpu"print("Using {} device".format(device))#读取要预测的图片# img = "./rose.jpg" # img="./dandelion.jpg"# img="./tulip.jpg"# img="./daisy.jpg"img="./sunflower.jpg"#格式转换 img = Image.open(img)plt.imshow(img)plt.show()img = my_transform(img).to(device)#加载模型model = Net().to(device) #创建一个名为model的神经网络模型,并将其转移到指定的设备上(如:GPU)model.load_state_dict(torch.load('./flowers_model.pt')) #加载模型的参数状态字典,模型的状态字典通常包含了模型的权重和偏置等参数model.eval() #把模型转为test模式img = img.unsqueeze(0)# 添加一个维度output = model(img)pred = torch.max(output, 1)[1]print(pred)if pred.item() == 0: print("daisy")elif pred.item() == 1:print("dandelion")elif pred.item() == 2:print("rose")elif pred.item() == 3:print("sunflower")elif pred.item() == 4:print("tulip")else: print("error")我训练模型的结果如下:
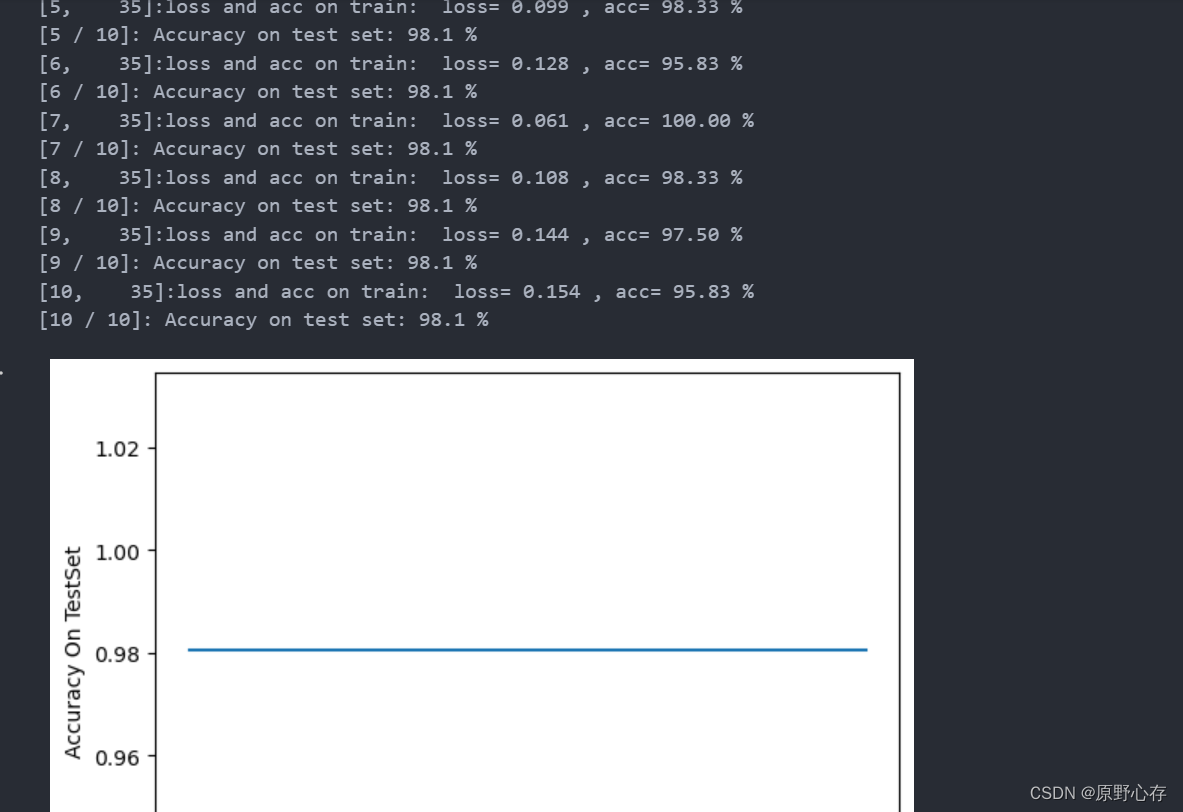
完整代码:
import os
import torch
from PIL import Image
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
from torchvision import transforms #pytorch中的图像预处理包:pip3 install torchvision
from torchvision import datasets,models
from torch import nn#导入神经网络包nn(可用来定义和运行神经网络)
from torch import optim#导入优化器包
train_datadir='./flowers/train/' #指定数据集的文件路径
test_datadir='./flowers/test/'
batch_size =120 #小批量数据集的大小定义为40
learning_rate = 0.005 #梯度下降算法中用到的学习率(learning rate)。
#momentum = 0.5 #梯度下降算法中用到的冲量(momentum)
EPOCH = 10 #训练的轮数。
print("\n========原野小路============\n")my_transform = transforms.Compose([transforms.Resize((224,224)), #对图像大小进行调整transforms.ToTensor(), #将图像转换为pytorch张量transforms.Normalize(mean=[0.485, 0.456, 0.406], #对图像进行标准化处理,将每个像素的数值按照指定的均值和标准差调整,适应模型训练std=[0.229, 0.224, 0.225])]) train_data = datasets.ImageFolder(root=train_datadir,transform=my_transform) #读取训练数据
test_data = datasets.ImageFolder(root=test_datadir,transform=my_transform) #读取测试数据集
#查看datasets.ImageFolder的输出
print(train_data.classes) #类名List
print(train_data.class_to_idx) #类名和标签构成的字典:(class_name,class_index)
print(train_data.imgs[0]) #数据集元组构成的List:(文件名,标签)
print(len(train_data),len(test_data)) #打印训练集和测试集规模train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True) #随机抽取,形成小批量训练数据集,shuffle表示是否打乱
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False) #顺序抽取,形成小批量测试数据集
for step, (data, targets) in enumerate(train_loader): #enumerate将一个可迭代对象组合为一个索引序列,同时列出数据和数据的索引。这句话中step是训练数据集的索引print(data.size()) #数torch.Size([30, 3, 224, 224]) ,通道为3表示彩色图片print(targets.size()) #小批量数据集为400break
"""
卷积运算 使用花卉数据集分类数据集
"""
class Net(nn.Module):def __init__(self): #没有传参super(Net, self).__init__()self.conv1 = nn.Sequential( #打包第一个卷积,池化nn.Conv2d(3, 30, kernel_size=5), #kernel_size表示卷积核大小nn.ReLU(), #定义激活函数为relunn.MaxPool2d(kernel_size=2) )self.conv2 = nn.Sequential(nn.Conv2d(30, 20, kernel_size=5),nn.ReLU(),nn.MaxPool2d(kernel_size=2))self.fc = nn.Sequential( #打包全连接nn.Linear(20*53*53, 20),nn.ReLU(),nn.Linear(20, 5))def forward(self, x):# Xsize = x.size(0)x = self.conv1(x) # 一层卷积层,一层池化层,一层激活层(图是先卷积后激活再池化,差别不大)x = self.conv2(x) # 再来一次x = x.view(-1,20*53*53) # flatten 变成全连接网络需要的输入 (batch, 20,4,4) ==> (batch,320), -1 此处自动算出的是320x = self.fc(x) #全连接return x # 最后输出的是维度为10的,也就是(对应数学符号的0~9)
# 找到可以用于训练的 GPU
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
#模型实例化
model = Net().to(device)
print(model)n_feature = 3*224*224 #输入层神经元数(特征数)
n_hidden = [128,64] #隐藏层神经元数
n_output = 5 #输出层神经元数(类别数)
model = Net()
# SGD: 随机梯度下降
optimizer = optim.Adagrad(model.parameters(), lr=learning_rate)
# 针对分类问题的损失函数!
loss_func = nn.CrossEntropyLoss() #正式训练# 精度计算函数
def accuracy(outputs, labels):pred = torch.max(outputs, 1)[1]rights = pred.eq(labels).sum() #统计模型中识别正确图片的个数return rights
"""
一轮训练函数
输入:当前训练轮数
"""
def train(epoch):for step, (data, targets) in enumerate(train_loader):# 网络前传 -> 计算损失 -> 清空梯度 -> 反向传播 -> 优化网络参数outputs = model(data)loss = loss_func(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()# 计算损失、训练集精度running_loss = loss.item() #训练数据的损失率acc = 100 * accuracy(outputs, targets) / data.shape[0] #训练数据的准确率if step % 35 == 34: # 不想要每一次都出loss,浪费时间,选择每30次输出一个损失和准确率print('[%d, %5d]:loss and acc on train: loss= %.3f , acc= %.2f %%' % (epoch + 1, step + 1, running_loss, acc))"""
一轮测试函数
输出:测试集的测试精度
"""
def test():correct = 0total = 0with torch.no_grad(): # 测试集不用算梯度for images, labels in test_loader:outputs = model(images)prediction = torch.max(outputs, 1)[1] total += labels.size(0) # 张量之间的比较运算correct += (prediction == labels).sum().item()acc = correct / total #测试集的正确率,集外精度print('[%d / %d]: Accuracy on test set: %.1f %% ' % (epoch+1, EPOCH, 100 * acc)) # 求测试的准确率,正确数/总数return accif __name__ == '__main__':acc_list_test = []temp = 0for epoch in range(EPOCH):train(epoch) #调用训练轮acc_test = test() #调用测试轮acc_list_test.append(acc_test) #记录测试精度,方便打印if acc_test > temp: torch.save(model.state_dict(), 'flowers_model.pt') #保存最佳模型temp = acc_testplt.plot(acc_list_test)plt.xlabel('Epoch')plt.ylabel('Accuracy On TestSet')plt.show()这篇关于利用深度学习解决生活中实际问题——卷积网络实现花卉分类识别(附带数据集,完整代码在最后)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




