本文主要是介绍【PyTorch实战演练】深入剖析MTCNN(多任务级联卷积神经网络)并使用30行代码实现人脸识别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0. 前言
- 1. 级联神经网络介绍
- 2. MTCNN介绍
- 2.1 MTCNN提出背景
- 2.2 MTCNN结构
- 3. MTCNN PyTorch实战
- 3.1 facenet_pytorch库中的MTCNN
- 3.2 识别图像数据
- 3.3 人脸识别
- 3.4 关键点定位
0. 前言
按照国际惯例,首先声明:本文只是我自己学习的理解,虽然参考了他人的宝贵见解及成果,但是内容可能存在不准确的地方。如果发现文中错误,希望批评指正,共同进步。
本文详细介绍MTCNN——多任务级联卷积神经网络的结构,并通过PyTorch实例说明MTCNN在人脸识别上的应用。
MTCNN的全称是Multi-Task Cascaded Convolutional Networks,它的缩写确实是MTCNN不是MTCCN.
1. 级联神经网络介绍
级联(cascaded)神经网络是一种人工神经网络的架构设计,它指的是多个神经网络层按照特定的方式连接起来,形成一个逐层处理信息的多层结构。在级联神经网络中,前一层次网络的输出作为后一层次网络的输入,这种结构允许在网络在深度方向上对复杂性和抽象层数进行增加。
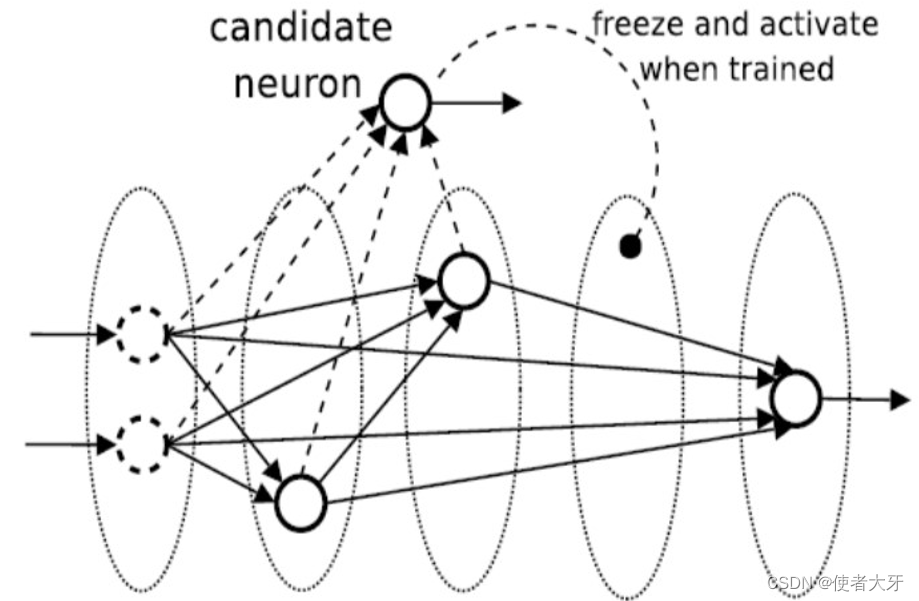
级联网络的重要特点是其动态构建特性,即可以从一个小规模的基本网络开始,并随着训练过程自动添加更多的隐藏单元或子网络,逐渐扩展成一个更深层次的结构,然后通过只针对新增部分数据进行训练来更新权重,即增量式学习(Incremental Learning)。这与传统的——构建完整模型后统一进行训练更新权重的思路非常不同。
使用传统的思路,如果发现我们的模型并不适用于待解决的任务,导致要调整模型结构时,通常会意味着之前的训练模型的工作全部白费了。
总结起来级联神经网络具有以下优点:
-
自适应结构:级联网络设计允许根据训练数据或学习过程动态调整网络结构,比如自动增加新的层或神经元,以适应更复杂的模式识别任务。
-
学习效率提升:可以通过增量学习或局部训练来加快学习速度,只针对新增加的部分进行训练优化。在某些情况下,级联网络可以采用非传统的权重更新机制,不需要在整个网络上执行全局误差反向传播算法。
-
鲁棒性和容错性:分层结构有助于提高系统的鲁棒性,单个层次的错误可能在后续层次中得到修正。
2. MTCNN介绍
2.1 MTCNN提出背景
MTCNN是Kaipeng Zhang等人在论文——Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks中提出的,其宗旨是通过多任务级联CNN解决两个问题:人脸检测(找出图像中人脸的位置和边界框)和人脸对齐(精确定位面部特征点)。
2.2 MTCNN结构
MTCNN的构建思路可以简单分为下面几个步骤:
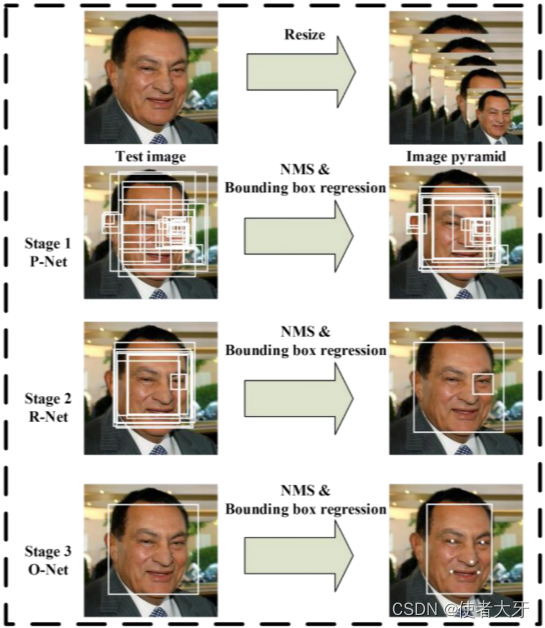
- 准备步骤:对图像进行缩放,建立图像金字塔;
- 第一步Proposal-Net:快速选出若干候选框,为下一步准备;
- 第二步Refine-Net:对第一步的众多候选框进行精选,留下置信度大的候选框;
- 第三步Output-Net:输出最终bounding box、人脸关键特征定位和置信度。
详细来说P-Net、R-Net和O-Net的结构如下:
通过Netron可以看到facenet_pytorch库中的MTCNN的结构及详细参数如下:

-
P-Net (Proposal Network):
- 输入是原始图像。
- 首先通过一个卷积层(Conv2d)将3通道的输入图像转换为10通道特征图,使用3x3的卷积核(kernel_size=(3, 3))。
- 紧接着使用PReLU激活函数(prelu1)进行非线性变换。
- 使用最大池化层(MaxPool2d)下采样特征图(pool1),步长为2。
- 再经过两个卷积层(Conv2d)提取更深层次的特征,并分别用PReLU激活函数(prelu2和prelu3)进行非线性处理。
- 最后通过两个1x1卷积层(Conv2d)生成两个输出:一个是softmax4_1用于预测每个像素是否为人脸的概率分布,另一个是conv4_2用于回归bounding box的位置信息。
-
R-Net (Refine Network):
- 输入是P-Net的候选区域。
- 类似于P-Net,R-Net也包含多个卷积层与激活函数,以及池化层进行特征提取和下采样。
- 在最后,通过两个全连接层(Dense或Linear)生成两个输出:softmax5_1用于判断候选框内是否为人脸并给出置信度,dense5_2用于进一步细化人脸框的位置。
-
O-Net (Output Network):
- 输入同样是前一级网络(R-Net)筛选后的候选区域。
- O-Net具有更多的卷积层以获取更精细的特征表达,同样在最后阶段通过三个全连接层生成三个输出:softmax6_1用于人脸分类,dense6_2用于人脸框回归精修,dense6_3用于估计关键点(如眼睛、嘴巴等)的位置。
整个MTCNN模型通过逐步筛选和优化候选区域,在不同尺度上定位和识别图像中的人脸,从而实现高效准确的人脸检测。
3. MTCNN PyTorch实战
3.1 facenet_pytorch库中的MTCNN
facenet_pytorch库中的MTCNN类是一个用于人脸检测的多任务级联卷积神经网络模型实现。直接使用MTCNN类的最大好处就是该模型已经训练好,可以拿来即用,其初始化时接受多个参数,以下是对这些参数的详细解释:
-
image_size(默认值:160):输出图像的大小(像素),图像会调整为正方形。
-
margin(默认值:0):在最终图像上添加到边界框的边距(以像素为单位)。需要注意的是,与davidsandberg/facenet库中的应用方式稍有不同,该库在调整原始图像大小之前就对原始图像应用了边距,导致边距与原始图像大小相关(这是davidsandberg/facenet的一个bug)。
-
min_face_size(默认值:20):要搜索的人脸的最小尺寸。
-
thresholds(默认值:[0.6, 0.7, 0.7]):MTCNN人脸检测阈值列表,分别对应P-Net、R-Net和O-Net三个阶段的阈值。
-
factor(默认值:0.709):用于创建人脸大小缩放金字塔的比例因子。
-
post_process(默认值:True):是否在返回前对图像张量进行后处理。
-
select_largest(默认值:True):如果检测到多个人脸,是否选择面积最大的一个返回。若设为False,则选择概率最高的人脸返回。
-
selection_method(默认值:None):指定使用哪种启发式方法进行选择,如果设置此参数将覆盖
select_largest:"probability":选择概率最高的。"largest":选择面积最大的框。"largest_over_threshold":选择超过一定概率的最大框。"center_weighted_size":基于框大小减去离图像中心加权距离平方后的结果进行选择。
-
keep_all(默认值:False):如果设为True,则返回所有检测到的人脸,并按照
select_largest参数设定的顺序排列。如果指定了保存路径,第一张人脸将被保存至该路径,其余人脸将依次保存为<save_path>1, <save_path>2等。 -
device(默认值:None):运行神经网络前向传递时所使用的设备。图像张量和模型会在前向传递前复制到这个设备上。
3.2 识别图像数据
这块没有特殊要求,随便去网上下载,以下是我自己的识别对象数据:

3.3 人脸识别
- 代码
from facenet_pytorch import MTCNN
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
import osdevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('the device is:{}'.format(device))model = MTCNN(image_size=160, margin=0, min_face_size=10,thresholds=[0.7,0.7,0.7],factor=0.7, post_process=True, device=device)
path = os.path.abspath('face_img') #在face_img文件夹下面还要再加一个class_folder文件夹
dataset = datasets.ImageFolder(path)
imgs_list = list(sorted(os.listdir(os.path.join(path,'class_folder'))))def collate_fn(x):return x[0]loader = DataLoader(dataset, collate_fn = collate_fn, num_workers=0)
index = 0
#detected_faces = []for pic,_ in loader:aligned, confidence = model(pic , return_prob=True)if confidence is not None:print('Confidence of {} containing human face is {:.8f}'.format(imgs_list[index], confidence))detected_faces.append(aligned)else:print('No human face detected in {}'.format(imgs_list[index]))index += 1# 以下是人脸对齐的还原实现
#face_numpy = (detected_faces[0] + 1) * 127.5 # 由于是 [-1, 1] 范围,将其映射到 [0, 255]
#face_numpy = face_numpy.numpy().astype(np.uint8)
#face_image = Image.fromarray(face_numpy.transpose(1, 2, 0)) # 将 Numpy 数组转为 PIL 图像格式,并注意调整通道顺序为 (H, W, C)#plt.imshow(face_image)
#plt.show()
- 输出
Confidence of art.png containing human face is 0.99512947
No human face detected in ironman.png
Confidence of man.png containing human face is 0.99643928
No human face detected in ogre.png
Confidence of thanos.png containing human face is 0.96726525
Confidence of woman.png containing human face is 0.99991846
可见MTCNN不认为钢铁侠和食人魔魔法师算“人脸”。MTCNN的输出有2部分:
- 对齐后的人脸张量:其范围是[-1, 1],可以将其线性还原到[0, 255]并输出对其后的人脸,例如下图:
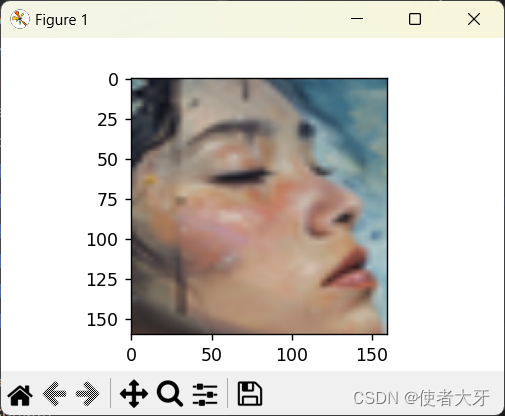
- 包含人脸的置信度:即上面的0.99512947等置信度数值。
3.4 关键点定位
也可以使用mtcnn.detect()得到人脸得关键点(眼睛、鼻子、嘴角)定位,代码如下:
from facenet_pytorch import MTCNN
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
import os
import numpy
import matplotlib
import matplotlib.pyplot as pltdevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('the device is:{}'.format(device))model = MTCNN(image_size=160, margin=0, min_face_size=10,thresholds=[0.7,0.7,0.7],factor=0.7, post_process=True, device=device)path = os.path.abspath('face_img') #在face_img文件夹下面还要再加一个class_folder文件夹
dataset = datasets.ImageFolder(path)
imgs_list = list(sorted(os.listdir(os.path.join(path,'class_folder'))))def collate_fn(x):return x[0]loader = DataLoader(dataset, collate_fn = collate_fn, num_workers=0)
index = 0
detected_faces = []for pic,_ in loader:aligned, confidence = model(pic , return_prob=True)if confidence is not None:print('Confidence of {} containing human face is {:.8f}'.format(imgs_list[index], confidence))detected_faces.append(aligned)boxes, probs, points = model.detect(pic, landmarks=True)points = points.squeeze(0)for x,y in points:plt.scatter(x,y,s=10,c='r')plt.imshow(pic)plt.savefig('{}_aligned.jpg'.format(imgs_list[index]))plt.close()else:print('No human face detected in {}'.format(imgs_list[index]))index += 1最终保存的图像为:


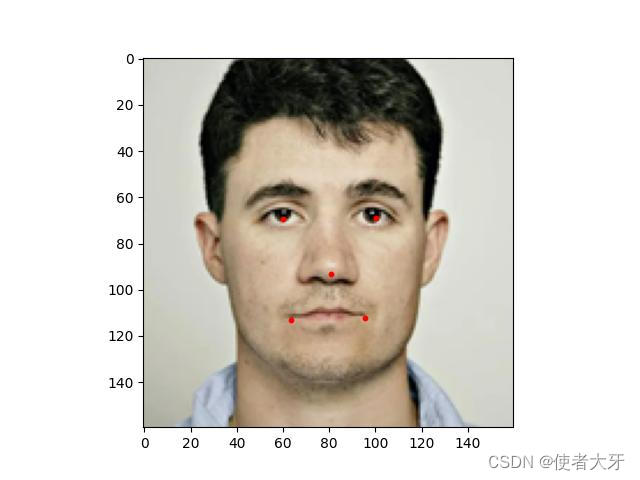
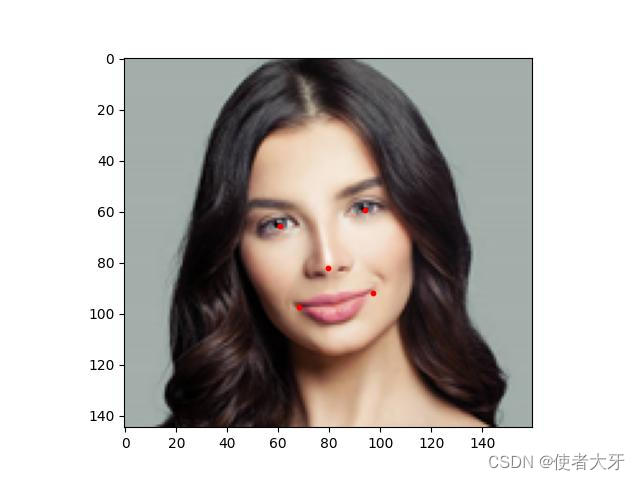
可以看出MTCNN的关键点定位也是很准确的。上面代码的boxs即为人脸边界框,这里不再画出效果。
这篇关于【PyTorch实战演练】深入剖析MTCNN(多任务级联卷积神经网络)并使用30行代码实现人脸识别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






