本文主要是介绍【论文阅读】Multiplex Graph Neural Network for Extractive Text Summarization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【论文阅读】Multiplex Graph Neural Network for Extractive Text Summarization
用于提取文本总结的多路复用图神经网络
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing
摘要
提取文本摘要旨在从给定文档中提取最具代表性的句子作为其摘要。为了从长文本文档中提取良好的摘要,句子嵌入起着重要作用。最近的研究利用图神经网络捕获句子间关系(例如话语图),以学习上下文句子嵌入。然而,这些方法既不考虑多种类型的inter-sentential (句际)关系(例如语义相似性和自然联系),也不建模句内关系(例如单词之间的语义和句法关系)。为了解决这些问题,我们提出了一个新型的多路复用图卷积网络(Multi-GCN),在句子和单词之间共同建模不同类型的关系。基于Multi-GCN,我们提出了一个用于提取文本总结的多路复用图摘要(Multi-GraS)模型。最后,我们评估了CNN/DailyMail基准数据集的拟议模型,以证明我们方法的有效性
1 Introduction
每天都有来自不同来源的大量文档上传到互联网或数据库,如新闻文章(Hermann et al., 2015)、科学论文(Qazvinian和Radev, 2008)和电子健康记录(Jing et al., 2019)。如何有效地消化海量信息一直是自然语言处理中的一个基本问题(Nenkova and McKeown, 2011)。这一问题引发了人们对文本摘要的研究兴趣,它的目的是通过从文档中提取最具代表性的句子来生成一个简短的摘要。
最近的大多数方法将抽取文本摘要的任务定义为序列标注任务,其中标签表示是否应该将句子包含在摘要中。为了提取句子特征,现有的方法一般使用循环神经网络(RNN),卷积神经网络(CNN) 或Transformers。人们努力开发模型来捕捉不同的句子级关系。早期的研究,如LexRank 和TextRank ,建立了句子之间的相似图,并利用PageRank 对它们进行评分。后,神经网络图如图卷积网络(GCN) 一直在采取各种inter-sentential图表,如近似话语图,话语图和句子和单词之间的两偶图。
虽然现有方法行之有效,但仍有两个问题有待探讨。首先,现有研究构建的图只涉及一类边,句子之间往往通过多种关系进行关联(文献中称为多重图)。带有一些常见关键词的两个句子被认为是自然连接的(我们将这种类型的图称为自然连接图)。例如,在图1中,第一个和最后一个句子通过共享关键字City显示了一个自然的连接(绿色)。这两句话虽然相隔很远,但因为整个文档都是关于关键词City的,所以可以合在一起作为总结的一部分。而RNN、CNN等传统编码器很难捕捉到这种关系。两个意义相似的句子也被认为是连接的(我们把这种类型的图称为语义图)。在图1中,第二句和第三句语义相似,因为它们表达的意思相似(黄色)。语义相似图将语义相似的句子映射到同一个聚类中,从而帮助模型从不同的聚类中选择句子,提高摘要的覆盖率。不同的关系提供了来自不同方面的关系信息,联合建模不同类型的边缘将提高模型的性能。**其次,上述方法在利用词与词之间有价值的关系信息方面存在不足。**二者的句法关系和词之间的语义关系已被证明对下游任务有用,如文本分类、信息检索和文本摘要。

贡献:
- 为了利用句子和单词之间的多种类型关系,我们提出了一种新的多图卷积网络(Multi-GCN)。
- 在Multi-GCN的基础上,我们提出了一种基于多重图的摘要(Multi-GraS)框架用于文本摘要的抽取。
- 我们在CNN/每日邮报基准数据集上评估了我们的方法和竞争方法,结果证明了我们的模型的有效性和优越性。
2 Methodology
我们首先提出Multi-GCN方法来联合建模不同的关系,然后提出Multi-GraS方法用于文本摘要的提取。
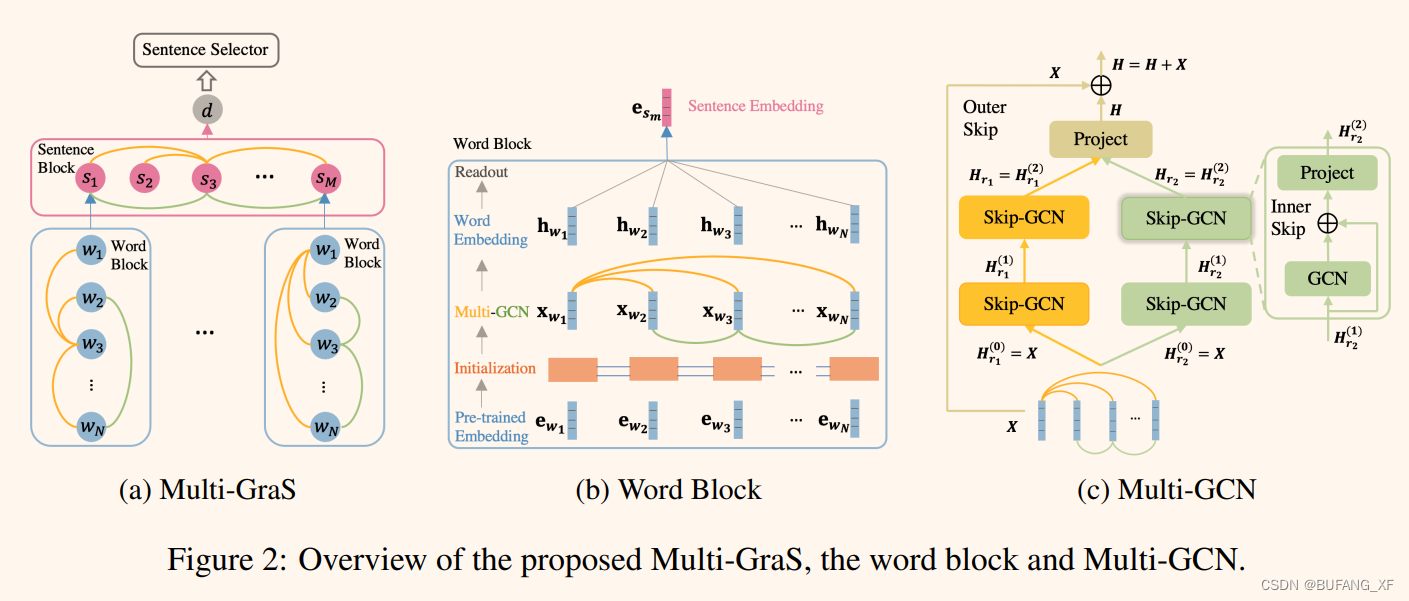
2.1 Multiplex Graph Convolutional Network
图2c描述了Multi-GCN在一个初始节点嵌入X和一组关系R的多路图上的情况。首先,Multi-GCN分别学习不同关系r∈R的节点嵌入Hr,然后将它们组合起来产生最终的嵌入h。其次,Multi-GCN使用两种类型的跨连接,内部和外部跨连接,以减轻过平滑(Li等人,2018)和原始GCN的消失梯度问题(Kipf和Welling, 2016)。
更具体地说,我们提出了一个带有内部跳过连接的skip - gcn来提取每个关系的嵌入Hr。定义Skip-GCN第l层的更新函数为:

A是关系r的邻接矩阵,Hr是经过所有的Skip-GCN层后的输出。
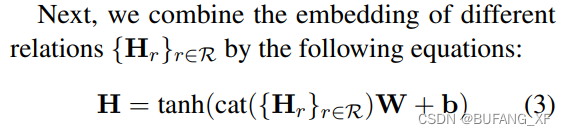
2.2 The Multi-GraS model
提出的Multi-GraS概述见图2a。Multi-GraS由三个主要成分组成:词块、句子块和句子选择器。单词块和句子块共享一个类似的Initialization Multi-GCN Readout结构来提取句子和文档嵌入。句子选择器根据提取的嵌入信息,选取最具代表性的句子作为摘要。
2.2.1 The Word Block
给定一个含有N个单词{wn} N N =1的句子sm,单词块以预先训练好的单词嵌入{ewn} N N =1作为输入,生成句子嵌入esm。具体来说,初始化模块通过Bi-LSTM产生上下文化的单词嵌入{xwn} N N =1。Multi-GCN模块联合捕获{xwn} N N =1的多个关系,生成{hwn} N N =1。Readout模块根据{hwn} N N =1上的最大pooling生成嵌入esm的句子。
在本文中,我们共同考虑了词语之间的句法和语义关系。对于句法关系,我们使用依赖解析器来构造语法图。
对于语义关系,我们利用嵌入词之间的点积的绝对值来构造图。注意,我们使用绝对值,因为GCN (Kipf和Welling, 2016)要求邻接矩阵中的值是非负的。
2.2.2 The Sentence Block
从本质上讲,句子块的结构类似于单词块,因此我们只对句子的图形结构进行详细的阐述。
本文考虑了句子之间的自然联系和语义联系。两个句子的语义相似度由两个句子嵌入的点积绝对值来表示,并以此构造语义相似度图。对于自然连接,如果两个句子共享一个共同的关键字,那么我们认为它们是自然连接。这种关系通过共享的关键字连接遥远的句子(不一定是语义相似的),从而有助于覆盖文档的更多部分,如图1所示。

2.2.3 Sentence Selector
句子选择器首先对{sm}M M =1的句子打分,然后选择排名前k的句子作为摘要。句子的评分模型设计遵循人类阅读理解策略,其中包含阅读和读后过程。阅读过程中提取了sm的大致意思:
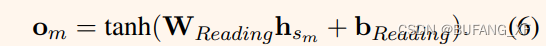
阅读后过程进一步捕获辅助语境信息——文档嵌入ed和初始句子嵌入esm:
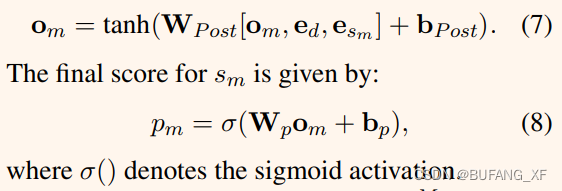
对句子ranking时,遵循tri-gram blocking技术以减少冗余。
Performance Evaluation
待添加
Discussion & Further Research
待添加
这篇关于【论文阅读】Multiplex Graph Neural Network for Extractive Text Summarization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








