本文主要是介绍引入概念的多文本标签分类:Concept-Based Label Embedding via Dynamic Routing for Hierarchical Text Classification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Zhang, Jiong, Wei-Cheng Chang, Hsiang-Fu Yu, and Inderjit Dhillon. “Fast Multi-Resolution Transformer Fine-Tuning for Extreme Multi-Label Text Classification.” In Advances in Neural Information Processing Systems, 34:7267–80. Curran Associates, Inc., 2021. Fast Multi-Resolution Transformer Fine-tuning for Extreme Multi-label Text Classification.
1 Motivation
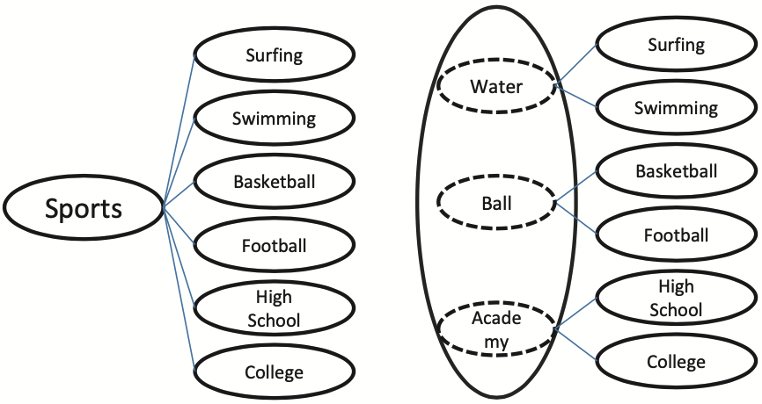
传统的层次多标签文本分类中,忽略了同一层次类之间的信息,比如图中,sport在第一层,是父类,surfing到college是第二层的子类。而在第二层中,surfing和swimming是跟water有关,其余两组类似。文章将water、ball、academy定义为相应子类共享的抽象概念,因而说本文方法是基于概念的标签文本嵌入。
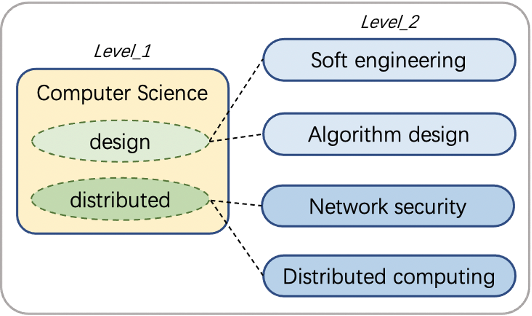
同理,在数据集wos中,也发现了类似的概念。
2 Methods
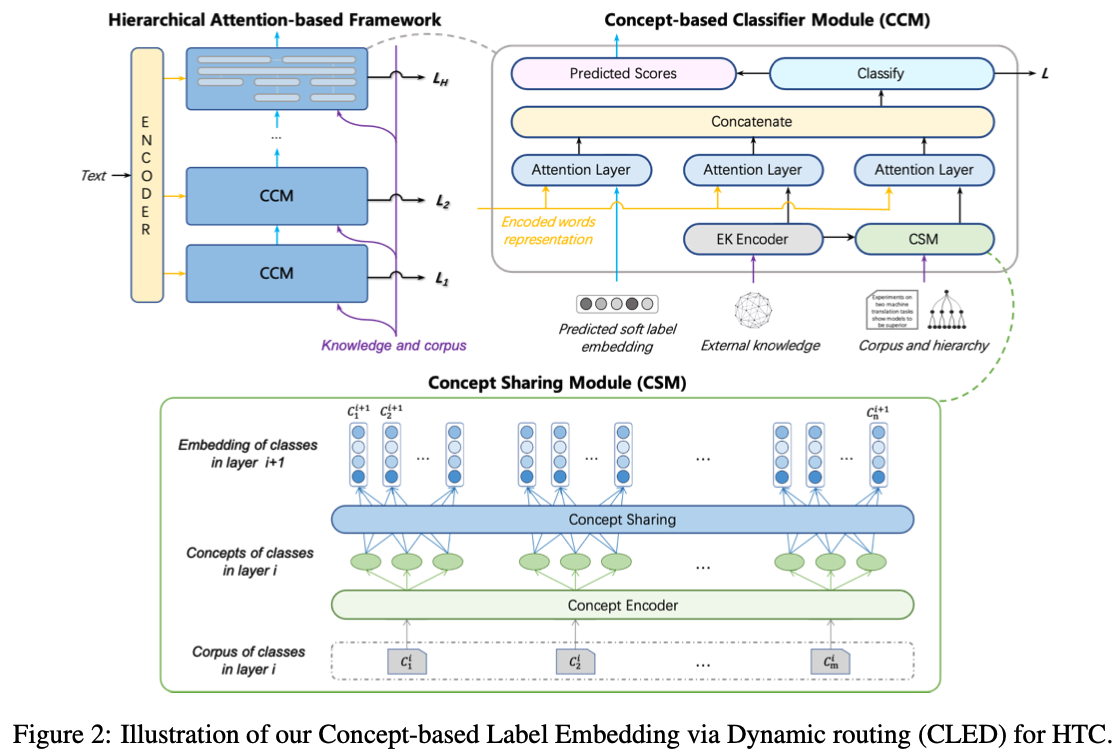
本文提出了基于层次注意力的架构(Hierarchical Sttention-Based Framework,左),其中包含基于概念的分类器(CCM,右上),CCM包含概念共享模块(CSM,下)。下面分别介绍。
2.1 Hierarchical Sttention-Based Framework
Text Encoder
对于文本,使用CNN进行n-gram特征的提取,然后用双向GRU提取上下文特征,最后得到:
![]() 作为文档的表征,|d|为token的个数。
作为文档的表征,|d|为token的个数。
Label Embedding Attention
第i层的标签表示为:![]() ,首先计算余弦相似矩阵
,首先计算余弦相似矩阵![]() ,其中
,其中![]() 。使用卷积核对每一个词p,提取其上下k个长度的特征:
。使用卷积核对每一个词p,提取其上下k个长度的特征:![]() ,然后使用最大池得到词p对第i层每一个标签的相关值:
,然后使用最大池得到词p对第i层每一个标签的相关值:![]() ,用softmax将r标准化之后,计算标签和文本之间的注意力分数:
,用softmax将r标准化之后,计算标签和文本之间的注意力分数:![]()
2.2 Concept Sharing Module (CSM)
上面是主体框架,文档的表征已经说明了来源,而CSM和CCM就是获得标签的表征C的。
Concepts Encoder
首先对于每一个类c,将其语料库中的关键词拿出来,并将其中的top-n作为这个类的概念。对于关键词,wos中每个文档都有相应的关键词,可以直接使用。DBpeida中没有,本文使用卡方检验获得单词和类之间的依赖关系,并根据卡方值进行排序。
两种方法编码概念:
1) 直接使用top-n个关键词
2) 将所有关键词进行聚类(GloVe 300-dimensional embeddings作为词嵌入的初始化),然后选取聚类的中心词
这两种方法得到的结果都可以表示为:![]()
Concepts Sharing via Dynamic Routing
对于HTC问题,子类和父类、不同类之间共享一些概念。不同概念从不同的角度描述一个类,而概念的共享体现了类间的语义联系。使用下述方法迭代更新标签表征:


beta表示概念i和类j的耦合因子(couping coefficient),b的来源见上图
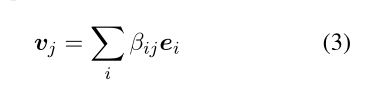
v为类的表征,类似于注意力机制
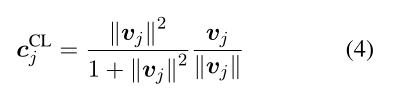
然后将v压缩得到c(squashing)
对上述过程迭代r次得到最后的表示。
2.3 Classification
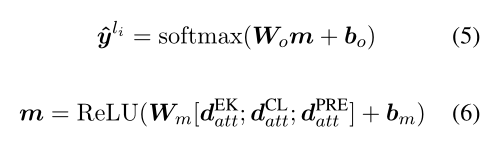

损失函数为每层的损失之和:
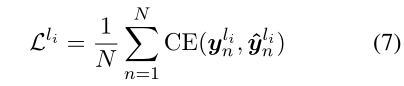
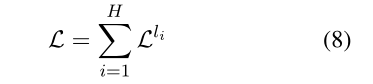
3 Experiments
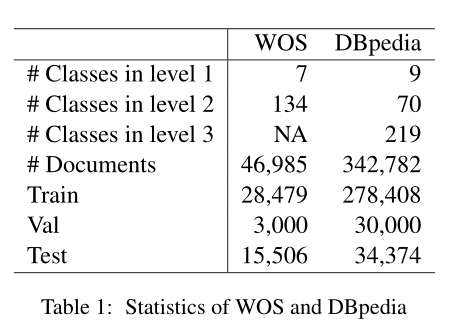
3.1 datasets
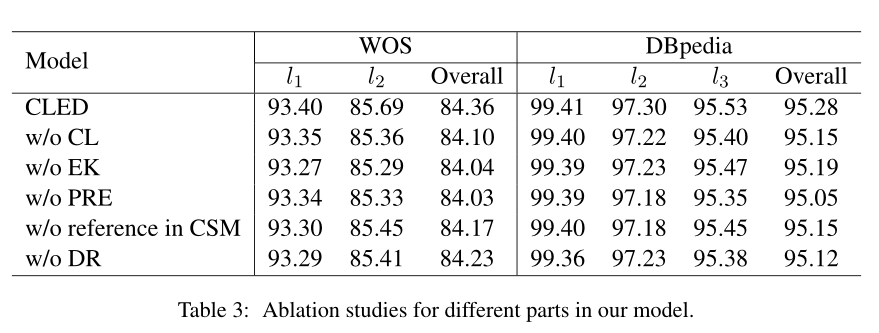
3.2 Ablation
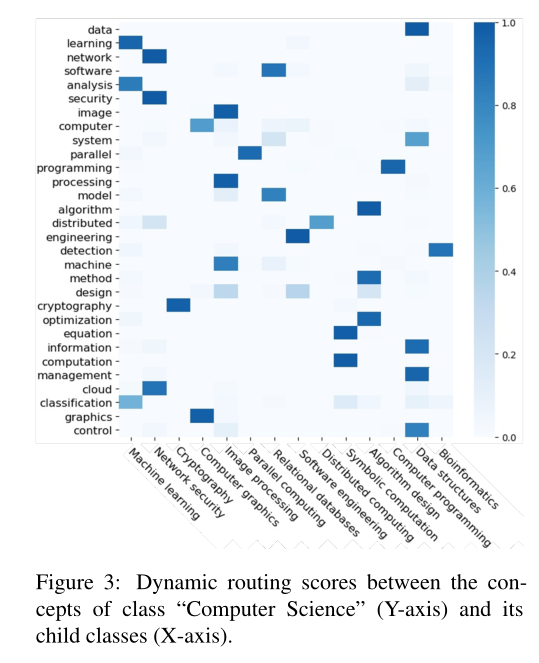
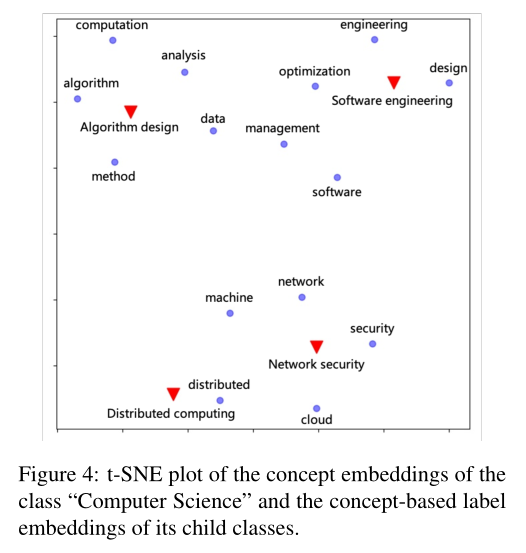
3.3 Visualizations
感想
本文乍一看比较复杂,但实际上还是与LightXML类似,都是将标签进行聚类。与之不同的是,本文使用的不是传统的聚类,而是采用语义。
这篇关于引入概念的多文本标签分类:Concept-Based Label Embedding via Dynamic Routing for Hierarchical Text Classification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







