本文主要是介绍Python爬虫实战(1) | 爬取豆瓣网排名前250的电影(上),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天我们来爬取一下豆瓣网上排名前250的电影。
需求:爬取豆瓣网上排名前250的电影,然后将结果保存至一个记事本里。
开发环境:
python3.9
pycharm2021专业版
我们先观察网页,看看它的url规律:
第一页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
不难看出,页数每次加1,url里面start的值就加20,一共有10页,start的值最大为225。
这是因为1页里面有25部电影。一共有10页,也就是250部电影。
接着我们再看看要获取电影的名称的html内容规律:
按住键盘的F12键,进入到网页的审查元素板块
点击右上角的图标之后回到网页进行点击网页内的一个元素,进行元素审查
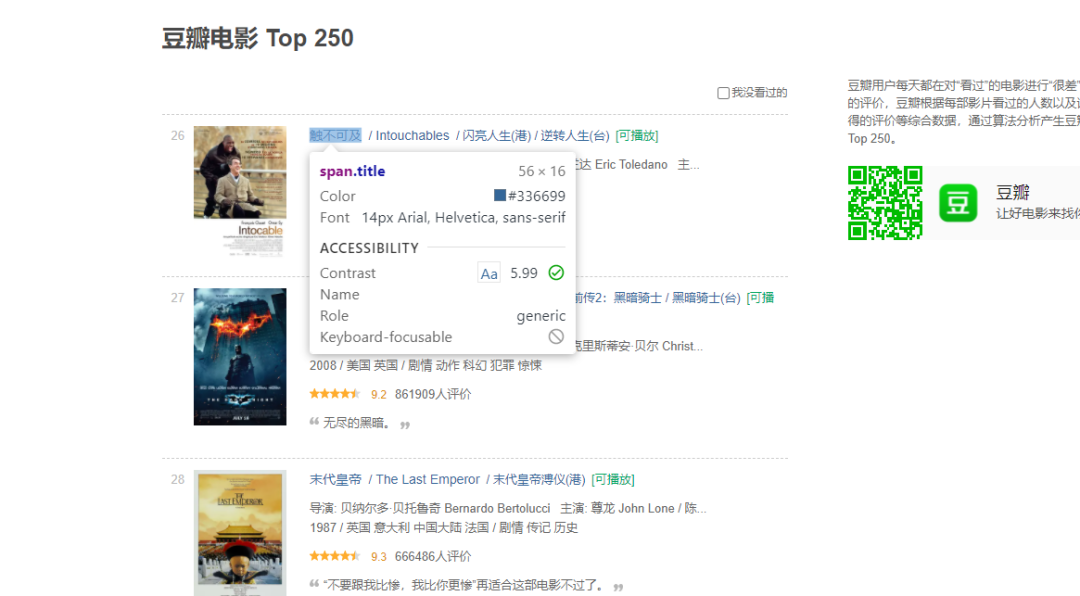
这里我们点击电影名称,就能获得它的html内容了
接着我们看下它的规律,方便后续的正则匹配:
<span class="title">肖申克的救赎</span>
<span class="title">霸王别姬</span>
之后导入我们的urllib模块和re模块
- urllib.request 模块:提供了最基本的构造 HTTP 请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理 authenticaton (授权验证), redirections (重定向), cookies (浏览器Cookies)以及其它内容
- urllib.error模块:用来捕获异常
- re模块:正则表达式,来匹配要获取的资源
import urllib.request
import urllib.error
import re
我的代码总共分为四个部分:
主函数
if __name__ == "__main__":pass
get_pages()函数:
用来发送网络请求,获取所需网页内容
def get_pages(url):pass
parse_content()函数:
对返回到的网页内容进行解析,再通过正则表达式匹配规则来获得所需要的网络资源:电影名称
def parse_content(content):pass
print_list()函数:
将获得到的电影列表写进一个记事本里
def print_list(url):pass
主函数
根据上文给出的url规律来设置while循环,让页数从0开始每次循环都加25,最大值为225。
之后调用print_list()函数
if __name__ == "__main__":pages = 0while pages <= 225:url = 'https://movie.douban.com/top250?start=%s' % pagesprint("正在爬取数据..........")pages += 25print_list(url)print("爬取完毕!")
get_pages()函数
防止网站有反爬虫机制,我们需要模拟浏览器来进行访问。
在网页的审查元素中找到user-Agent,写进去
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41'}发起请求并返回网页html内容
.....try:response = urllib.request.Request(url, headers=headers)content = urllib.request.urlopen(response).read()except urllib.error.URLError as e:print("爬取%s失败......................")%urlprint('错误原因:'+e.reason)else:return content
parse_content()函数
正则匹配
pattern = re.compile(r'<span class="title">(.*?)</span>')
movies_list = re.findall(pattern, content)
print_list()函数
将电影名单写进一个记事本里,同时还要注意内容换行
with open('豆瓣电影前250.txt', 'w', encoding='utf-8') as file:for i in movies_list:file.write(i+'\r\n')
源码
import urllib.request
import urllib.error
import re
def get_pages(url):"""返回所要爬取网页的html内容"""headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41'}try:response = urllib.request.Request(url, headers=headers)content = urllib.request.urlopen(response).read()except urllib.error.URLError as e:print("爬取%s失败......................")%urlprint('错误原因:'+e.reason)else:return content
def parse_content(content):"""对返回到的内容进行解析,获取所要资源:电影名称,并且放进列表里面"""content = content.decode('utf-8')pattern = re.compile(r'<span class="title">(.*?)</span>')movies_list = re.findall(pattern, content)return movies_list
def print_list(url):"""打印电影名单,并写入文件里面"""content = get_pages(url)movies_list = parse_content(content)with open('豆瓣电影前250.txt', 'w', encoding='utf-8') as file:for i in movies_list:file.write(i+'\r\n')
if __name__ == "__main__":"""爬取豆瓣网排名前250的电影"""pages = 0while pages <= 225:url = 'https://movie.douban.com/top250?start=%s' % pagesprint("正在爬取数据..........")pages += 25print_list(url)print("爬取完毕!")
我们来看一下结果

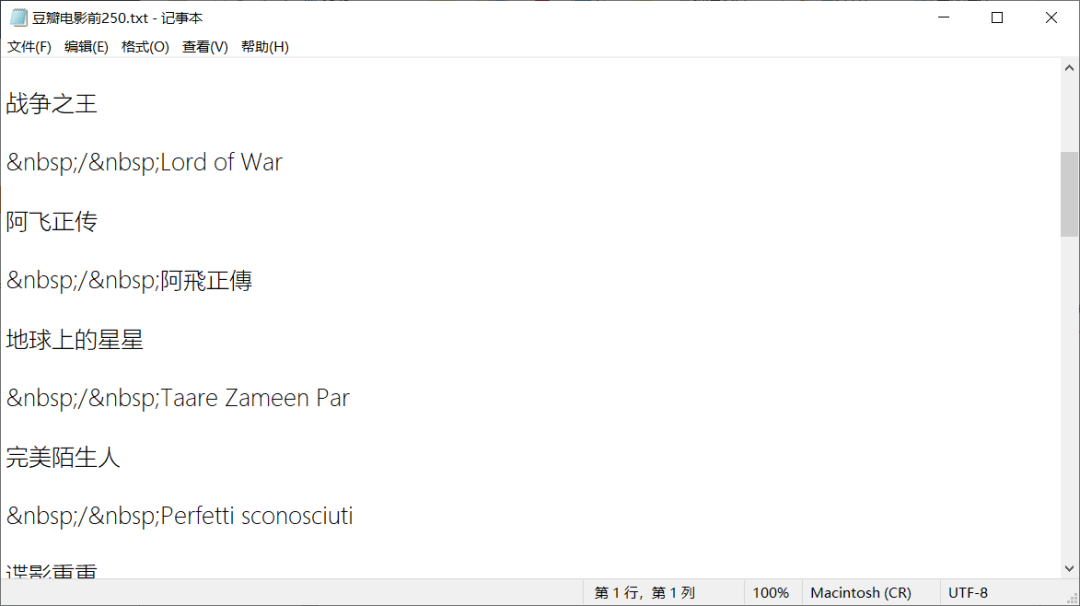
我们可以看到,结果并不是很如我们所愿,这是为什么呢?
我们重新查看网页元素,发现了这么一个现象

我们的正则匹配规则是这样的
pattern = re.compile(r'<span class="title">(.*?)</span>')
可以看到,这个匹配规则会将上面这两个网页元素一起匹配出来,就会导致我的爬取出来的电影列表里有这样一串不知名字符串。
那么有没有更好的办法呢?
肯定是有的,在下一集我们将使用一个俗称“靓汤”的模块,有了这个模块,我们的问题可以彻底解决,并且让我们爬虫更加得心应手。
这篇关于Python爬虫实战(1) | 爬取豆瓣网排名前250的电影(上)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







