本文主要是介绍Sparse R-CNN: End-to-End Object Detection with Learnable Proposals - 稀疏-RCNN:具有可学习提议的端到端对象检测--阅读笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

题目:Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
作者:Peize Sun1∗, Rufeng Zhang2∗, Yi Jiang3∗, Tao Kong3, Chenfeng Xu
发表单位:港大,同济,字节跳动AI lab
关键词:端到端物体检测,proposal boxes , proposal features , Sparse
论文:Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
代码:https://github.com/PeizeSun/SparseR-CNN
1 Motivation
- 下表格是目标检测领域主流的两大类方法与本文方法的比较
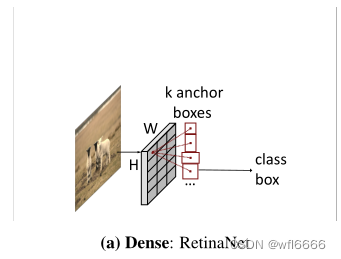 | 第一类就是使用大量的目标候选框,如DPM、YOLO、RetinaNet、FOCS:滑动窗口、基于锚框、基于参考点;这些东西被提前预设在图像网格或者特征图网格上,然后直接预测这些候选框到GT的尺度、位置偏移及物体类别 |
|---|---|
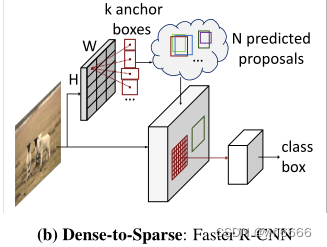 | 第二大类就是dense-to-sparse的,如R-CNN家族:只对一组sparse稀疏的候选进行预测和分类,但本质上这组sparse的候选还是来自于dense的检测 |
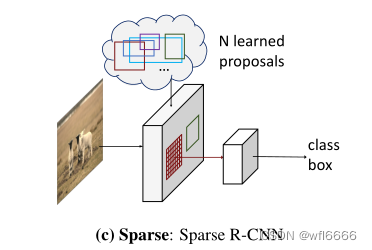 | 本文提出一种纯sparse的检测方案,用于解决以上两类基于dense的固有属性带来的固有局限,比如NMS后处理、many-to-one的正负样本分配、以及先验候选框的手工设计问题:直接从一组稀疏的可学习的提议出发,抛弃anchor-boxes、reference point等dense的概念,且与DETR一样,不需要NMS后处理,实现整个网络的干净整洁,是一个全新的检测范式。与DETR的不同在于,DETR中每个object query都和全局的特征图做attention交互,这本质上也是dense,本文提出稀疏交互。 |
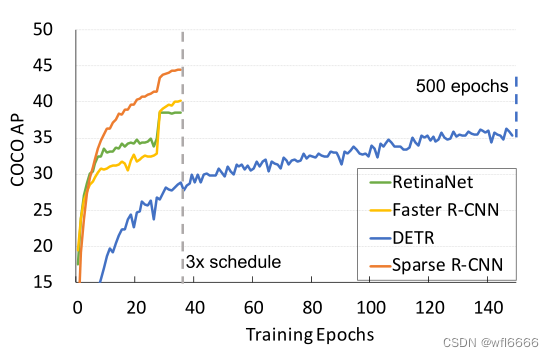
- 下图是RetinaNet、Fast-RCNN、DETR、Sparse-RCNN在COCO val 2017上的收敛曲线,可以看出,稀疏RCNN在训练的效率和检测精度上都取得了具有竞争力的性能。(其实deformable-DETR效果会比DETR好一些,这两者还未见比较。)
2 思想及主要组成部分
稀疏R-CNN的关键思想是用一小组可学习的建议框/特征(一般是100~300个)来代替RPN(区域建议网络)的数十万个候选。
下面看一下它的主要组成
| backbone | 基于ResNet架构的FPN(与Fast-RCNN对齐,实际上有可能从更复杂的设计中提升性能,就像Deformable DETR一样,使用SAE堆叠自编码器层和可变形卷积网络) |
|---|---|
| 三个输入 | image、proposal boxes、proposal features |
| 一个动态实例交互头 | 让proposal box经过RoIAlign操作提取特征与proposal feature融合,使用融合特征进行预测 |
| 预测层 | 用于两个特定任务的预测 |
3 Sparse R-CNN
下面主要讲一下Sparse-Rcnn的框架流程,本节将详细描述每个组件:
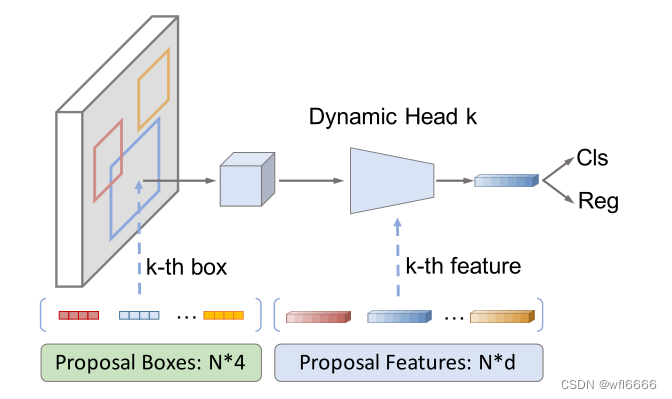
Proposal Boxes(可学习的提议框)
这些学习到的提议框我们可以理解为是训练集中潜在目标位置的统计数据,也就是可以看做图像中最可能包含目标的区域的初始猜测,因为我们认为RPN的提议虽然与当前图像有很强的相关性,但是代价较大,而合理的统计数字已经是合格的候选了,也就是说,我们不管输入是什么!如下图所示,白色的框就是N=100个提议框,是固定的:

Proposal boxes维度是N*4的具体细节:对图像归一化的中心坐标、高度、宽度;这些参数会在训练期间利用反向传播算法更新,因此是可学习的。
Proposal Features(可学习的提议特征)
可学习的提议特征的提出是因为虽然proposal boxes这个四维建议框是描述物体的一种简短明确的方式,但它只提供了物体的粗略定位,大量信息细节丢失,如物体的姿态、形状,因此引入提议特征proposal features这个概念,是高维的潜在向量,可以编码丰富的实例特征。
proposal features 是N*d的细节:N与proposal boxes的个相同,为N,以便one-to-one的交互;d是特征维度(e.g.256)。
- one-to-one的意思:proposal boxes 经过RoIAlign操作得到特征f_i (S*S,C),与proposal features P_i (C),这两个特征在动态交互头这里是一一对应的,就比如下图这个意思,其实就是跟proposal boxes一样的位置去训练得到的,这构成了交互头的两个输入:
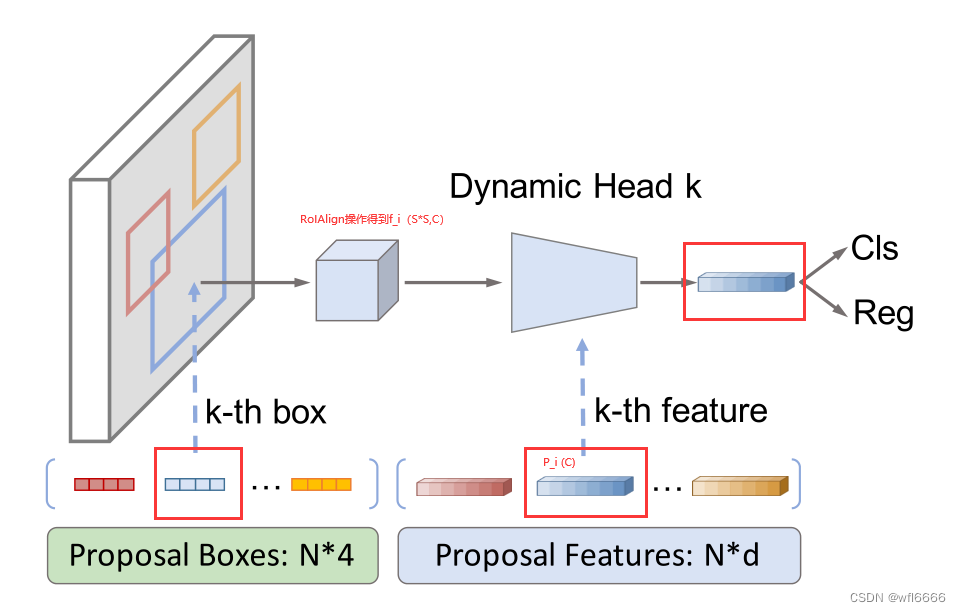
!](https://img-blog.csdnimg.cn/97a265bc2d58443f9c40f3f82b1a5797.jpeg)
动态实例交互的头
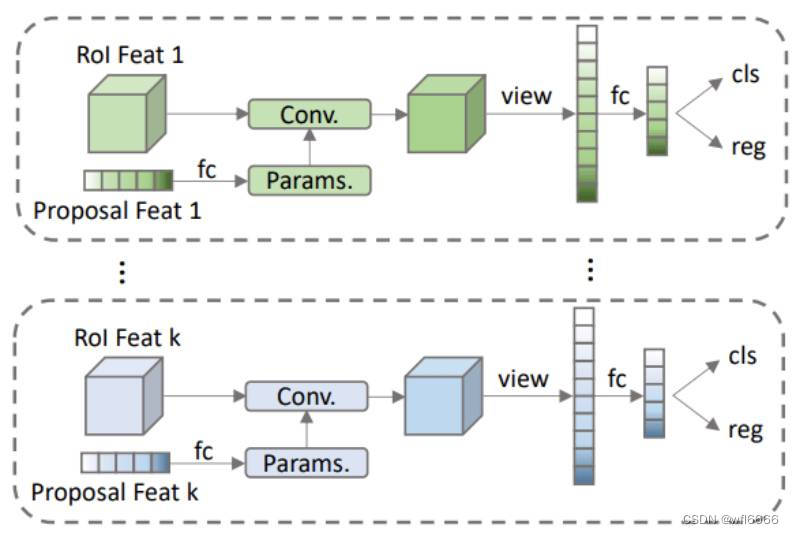
Dynamin Head 这里在图中可以看出是 Dynamic Head k,说明是第k个动态头,接受的输入是第k个提议框的RoI特征和第k个提议特征,这也是与其余检测方法的不同之处,即:第k个提议特征为对应的第k个RoI特征提供一组动态参数;而其余检测方法则是使用一组固定检测头参数。
原文:每个RoI特征被输入到自己的专属头中进行目标定位和分类,其中每个头以特定的提议特征为条件。
在下面这张图中看这句话比较清晰一些,提议特征被用做卷积的权重,在下面这张图中,就是Params。
且Head的数量跟proposal boxes的数量相同,即head/learnable proposal box/learnable proposal feature是一一对应的。
这里引用一篇博文段(具体哪篇记不清了)描述的更全面,不过我还不太了解transform结构和注意力机制,先放在这里:‘对感兴趣区域的特征进行卷积处理,得到最终的特征。这样,那些包含大部分前景信息的边界框对最终的目标位置和分类产生影响。同时,自注意力模块被嵌入到动态头部,用于推理物体之间的关系,并通过这种卷积来影响预测。’
- 下面描述了动态实例交互的伪代码,这里对两个特征之间是如何交互的,写的比文字清楚一些:
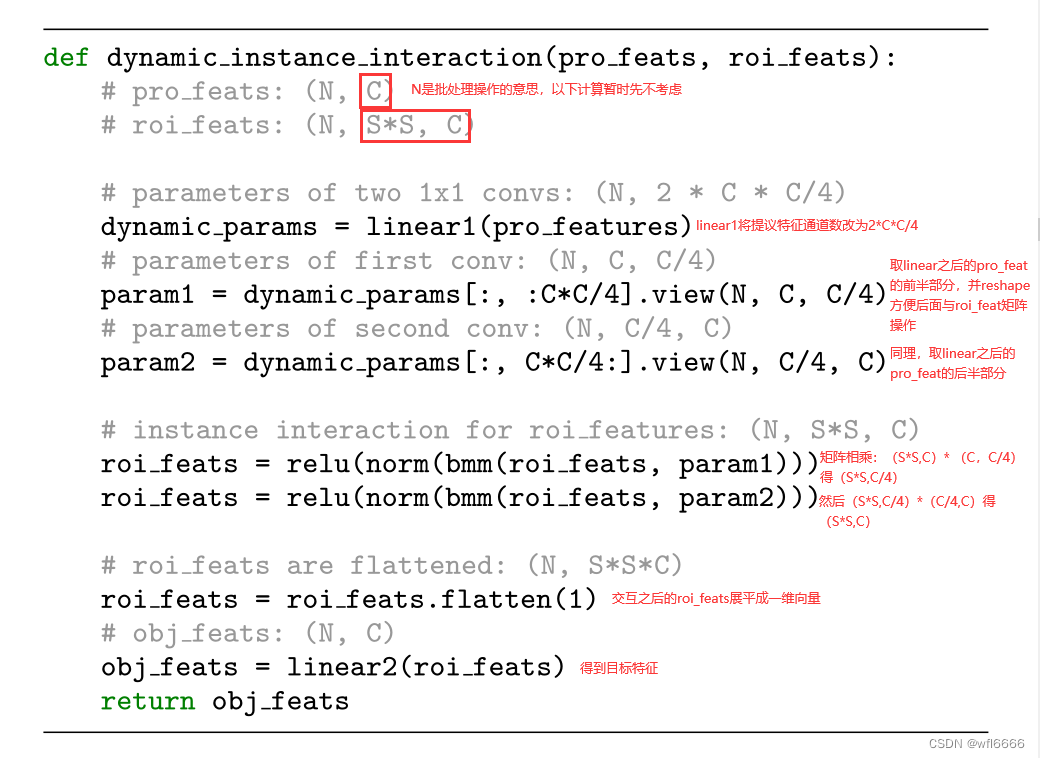
这里很新颖的一点就是支持并行操作来提高效率。最终的回归预测由一个3层的感知机计算,而分类预测由一个线性投影层计算。
预测损失
这里我比较感兴趣点在于它思路其实跟DETR差不多,采用集合预测的思路,于是sparse-rcnn在固定大小的分类和框的坐标预测集合上应用集合预测损失,基于集合的预测损失在预测和真值对象之间产生一个最优的二分匹配。
- 匹配成本定义如下:

但其实本文在拥挤场景下还是会出现一对多的情况,即假阳性。这个解决方案在cvpr2022里面有一篇,可以实现拥挤场景下的假阳性消除问题,提高性能。
这篇关于Sparse R-CNN: End-to-End Object Detection with Learnable Proposals - 稀疏-RCNN:具有可学习提议的端到端对象检测--阅读笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






