本文主要是介绍【AI视野·今日Robot 机器人论文速览 第八十三期】Wed, 6 Mar 2024,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI视野·今日CS.Robotics 机器人学论文速览
Wed, 6 Mar 2024
Totally 30 papers
👉上期速览✈更多精彩请移步主页
Interesting:
📚SpaceHopper,外星探索多功能三足机器人 (from Robotic Systems Lab, ETH Zurich)

Daily Robotics Papers
| A Safety-Critical Framework for UGVs in Complex Environments: A Data-Driven Discrepancy-Aware Approach Authors Skylar X. Wei, Lu Gan, Joel W. Burdick 这项工作提出了一种新颖的数据驱动的多层规划和控制框架,用于在存在未知固定障碍物和附加建模不确定性的情况下安全导航一类无人地面车辆 UGV。 |
| MOKA: Open-Vocabulary Robotic Manipulation through Mark-Based Visual Prompting Authors Fangchen Liu, Kuan Fang, Pieter Abbeel, Sergey Levine 开放词汇泛化要求机器人系统执行涉及复杂多样的环境和任务目标的任务。虽然视觉语言模型 VLM 的最新进展为解决看不见的问题提供了前所未有的机会,但如何利用其新兴功能来控制物理世界中的机器人仍然是一个悬而未决的问题。在本文中,我们提出了 MOKA 标记开放词汇关键点功能可供性,这是一种利用 VLM 来解决由自由形式语言描述指定的机器人操作任务的方法。我们方法的核心是基于紧凑点的可供性和运动表示,它将 VLM 对 RGB 图像的预测和机器人在物理世界中的运动联系起来。通过提示对互联网规模数据进行预训练的 VLM,我们的方法可以利用广泛来源的概念理解和常识知识来预测可供性并生成相应的动作。为了在零镜头中支撑 VLM 的推理,我们提出了一种视觉提示技术,可以在图像上注释标记,将关键点和路径点的预测转换为 VLM 可以解决的一系列视觉问答问题。利用以这种方式收集的机器人经验,我们进一步研究通过上下文学习和策略蒸馏来引导性能的方法。 |
| Biomechanical Comparison of Human Walking Locomotion on Solid Ground and Sand Authors Chunchu Zhu, Xunjie Chen, Jingang Yi 目前对人类运动的研究主要集中在坚实的地面行走条件上。在本文中,我们对人类在固体地面和沙子上行走的生物力学进行了比较。收集了一个新颖的数据集,其中包含 20 名身体健全的成年人在固体地面和沙子上运动的 3 维运动和生物力学数据。我们提出数据收集方法并报告传感器数据以及关节生物力学的运动学和动力学曲线。对人类步态和关节刚度曲线进行了综合分析。运动学和动力学分析表明,与在固体地面上行走的模式相比,人类在沙地上行走时表现出不同的地面反作用力和关节扭矩分布。这些步态差异反映了人类采用运动控制策略来适应沙地等地形条件。 |
| Fast Iterative Region Inflation for Computing Large 2-D/3-D Convex Regions of Obstacle-Free Space Authors Qianhao Wang, Zhepei Wang, Chao Xu, Fei Gao 1 限制性膨胀旨在确保生成的凸多面体的可管理性。根据其变量少、约束丰富的特点,设计了一种高效且数值稳定的求解器。 2 提出了一种将MVIE问题转化为SOCP公式的新方法,避免了直接面对正定约束,提高了计算效率。 3 特别是对于 2 D MVIE,首次引入了线性时间精确算法,填补了数十年的空白,进一步实现了超快的计算性能。 4 基于上述方法,提出了一种可靠的凸多面体生成算法FIRI。大量的实验验证了其在质量、效率、可管理性方面优越的综合性能。 |
| Online Learning of Human Constraints from Feedback in Shared Autonomy Authors Shibei Zhu, Tran Nguyen Le, Samuel Kaski, Ville Kyrki 由于不同的物理限制导致人类的行为模式不同,与人类的实时协作提出了挑战。现有的工作通常侧重于学习协作的安全约束,或者如何在参与代理之间划分和分配子任务以执行主要任务。相比之下,我们建议学习一个人类约束模型,此外,该模型还考虑不同人类操作员的不同行为。我们考虑一种共享自主方式的协作,其中人类操作员和辅助机器人在同一任务空间中同时行动,影响彼此的行动。辅助代理的任务是通过尽可能多地支持人类来增强人类执行共享任务的技能,既减少工作量,又最大限度地减少人类操作员的不适。 |
| Single-Channel Robot Ego-Speech Filtering during Human-Robot Interaction Authors Yue Li, Koen V Hindriks, Florian Kunneman 在本文中,我们研究了当人类语音与社交机器人 Pepper 的声音和风扇噪音重叠时,人类语音的自动过滤效果如何。我们的最终目标是实现 HRI 场景,在机器人说话时麦克风可以保持打开状态,从而实现更自然的轮流方案,人类可以打断机器人。为了做出适当的反应,机器人需要理解对话者在语音重叠部分所说的内容,这可以通过目标语音提取 TSE 来完成。为了研究 TSE 在流行的社交机器人 Pepper 的背景下如何完成,我们着手创建一个数据集,该数据集由 Pepper 本身录制的语音、靠近麦克风的风扇噪音以及人类语音组成,如下所示:由 Pepper 麦克风在低混响和高混响的房间内录制。将带后置滤波和不带后置滤波的信号处理方法以及卷积循环神经网络 CRNN 方法与基于 TSE 模型的最先进的说话人识别方法进行比较,我们发现不带后置滤波的信号处理方法在 Word 方面产生了最佳性能低混响的重叠语音信号的错误率,而 CRNN 方法对于混响更加鲁棒。 |
| A Miniaturized Device for Ultrafast On-demand Drug Release based on a Gigahertz Ultrasonic Resonator Authors Yangchao Zhou, Moonkwang Jeong, Meng Zhang, Xuexin Duan, Tian Qiu 按需控制药物输送对于治疗多种慢性疾病至关重要。由于药物在需要时释放,其功效得到增强,副作用最小化。然而,迄今为止,药物输送装置往往依赖于被动扩散过程来持续释放,这是缓慢且不可控的。在这里,我们提出了一种小型化微流体装置,用于由振荡固液界面驱动的无线控制超快主动药物输送。振荡在药物储存器中产生声流,从而打开弹性阀以输送药物。高速显微镜揭示了阀门的快速响应速度约为 1 毫秒,这比现有技术快了三个数量级以上。释放的药物量与超声谐振器的工作时间和施加的电功率呈线性关系。释放的触发通过磁场无线控制,系统在连续两周的实验中显示出稳定的输出。 |
| OORD: The Oxford Offroad Radar Dataset Authors Matthew Gadd, Daniele De Martini, Oliver Bartlett, Paul Murcutt, Matt Towlson, Matthew Widojo, Valentina Mu at, Luke Robinson, Efimia Panagiotaki, Georgi Pramatarov, Marc Alexander K hn, Letizia Marchegiani, Paul Newman, Lars Kunze 人们对用于自动车辆定位和场景理解的毫米波扫描雷达的学术兴趣和商业开发越来越感兴趣。尽管已经发布了支持该研究领域的多个数据集,但它们主要集中在城市或半城市环境。然而,崎岖的越野部署是重要的应用领域,这也为这种传感器技术带来了独特的挑战和机遇。因此,牛津越野雷达数据集 OORD 提供了在崎岖的苏格兰高地极端天气下收集的数据。我们向社区提供的雷达数据附有 GPS INS 参考,以进一步促进雷达地点识别的研究。通过 11 次驾驶不同的 4 条路线,总计约 154 公里的崎岖驾驶,我们总共释放了超过 90GiB 的雷达扫描以及 GPS 和 IMU 读数。这是文献中越来越多地探索的领域,因此我们展示并发布了最新开源雷达位置识别系统的示例及其在我们的数据集上的性能。这包括一个学习的神经网络,我们也发布了它的权重。 |
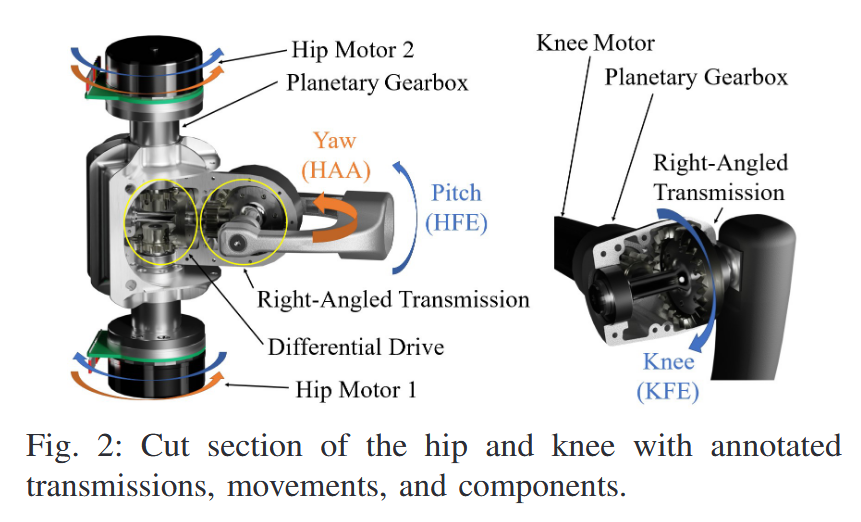
| SpaceHopper: A Small-Scale Legged Robot for Exploring Low-Gravity Celestial Bodies Authors Alexander Spiridonov, Fabio Buehler, Moriz Berclaz, Valerio Schelbert, Jorit Geurts, Elena Krasnova, Emma Steinke, Jonas Toma, Joschua Wuethrich, Recep Polat, Wim Zimmermann, Philip Arm, Nikita Rudin, Hendrik Kolvenbach, Marco Hutter 我们推出了 SpaceHopper,这是一款三足小型机器人,专为未来小行星和卫星的移动探索而设计。该机器人重5.2公斤,机身尺寸为245毫米,采用符合太空要求的组件。此外,SpaceHopper 的设计和控制使其非常适合研究具有扩展飞行阶段的动态运动模式。该系统没有使用陀螺仪或飞轮,而是使用其三个腿在飞行过程中重新调整身体方向,以准备着陆。我们使用深度强化学习策略来控制腿部运动以进行重新定向。在谷神星重力0.029g的模拟中,机器人可以可靠地跳跃到6m外的指令位置。我们的现实世界实验表明,SpaceHopper 可以在旋转万向节内成功地重新定向到 9.7 度范围内的安全着陆方向,并在地球重力的配重设置中跳跃。 |
| LodeStar: Maritime Radar Descriptor for Semi-Direct Radar Odometry Authors Hyesu Jang, Minwoo Jung, Myung Hwan Jeon, Ayoung Kim 海事雷达普遍采用来捕获船舶的全向数据作为图像。然而,海洋雷达仍然存在固有的挑战,包括频率有限、分辨率次优和检测不确定。此外,广阔的海洋中缺乏可辨别的地标仍然是一个挑战,导致连续的场景通常缺乏匹配的特征点。在此背景下,我们引入了弹性海事雷达扫描表示 LodeStar,以及为海事雷达应用量身定制的增强型特征提取技术。此外,我们开始利用半直接方法估算海洋雷达里程计。 |
| Splat-Nav: Safe Real-Time Robot Navigation in Gaussian Splatting Maps Authors Timothy Chen, Ola Shorinwa, Weijia Zeng, Joseph Bruno, Philip Dames, Mac Schwager 我们推出了 Splat Nav,这是一种导航管道,由实时安全规划模块和强大的状态估计模块组成,旨在在高斯 Splatting GSplat 环境表示中运行,这是计算机视觉中流行的新兴 3D 场景表示。我们制定了严格的碰撞约束,可以快速计算这些约束,以在地图上构建有保证的安全多面体走廊。然后,我们优化穿过该走廊的 B 样条轨迹。我们还通过将 GSplat 表示解释为点云来开发实时、鲁棒的状态估计模块。该模块使机器人能够使用点云对齐从 RGB D 图像中以零先验知识来定位其全局姿态,然后使用图像到点云定位在 RGB 图像中的场景中移动时跟踪其自身的姿态。我们还将语义融入到 GSplat 中,以获得更好的图像进行定位。所有这些模块主要在 CPU 上运行,从而释放 GPU 资源用于实时场景重建等任务。 |
| RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches Authors Priya Sundaresan, Quan Vuong, Jiayuan Gu, Peng Xu, Ted Xiao, Sean Kirmani, Tianhe Yu, Michael Stark, Ajinkya Jain, Karol Hausman, Dorsa Sadigh, Jeannette Bohg, Stefan Schaal 自然语言和图像通常用作目标条件模仿学习 IL 中的目标表示。然而,自然语言可能是模棱两可的,图像也可能是过度指定的。在这项工作中,我们提出手绘草图作为视觉模仿学习中目标规范的一种方式。用户可以轻松地像语言一样即时提供草图,但与图像类似,它们也可以帮助下游策略进行空间感知,甚至超越图像来消除与任务无关的任务相关对象的歧义。我们提出了 RT Sketch,一种以目标为条件的操纵策略,它将所需场景的手绘草图作为输入,并输出动作。我们在配对轨迹数据集和相应的综合生成的目标草图上训练 RT Sketch。我们根据六种操作技能评估这种方法,涉及在铰接式台面上重新排列桌面对象。通过实验,我们发现 RT Sketch 能够在简单的设置中达到与图像或语言条件代理相似的水平,同时在语言目标不明确或存在视觉干扰时实现更高的鲁棒性。此外,我们还表明 RT Sketch 能够解释不同级别的草图并对其进行操作,范围从最小的线条图到详细的彩色图。 |
| UFO: Uncertainty-aware LiDAR-image Fusion for Off-road Semantic Terrain Map Estimation Authors Ohn Kim, Junwon Seo, Seongyong Ahn, Chong Hui Kim 自主越野导航需要对环境进行准确的语义理解,通常将其转换为各种下游任务的鸟瞰图 BEV 表示。虽然基于学习的方法已经成功地从传感器数据直接生成本地语义地形地图,但它们在越野环境中的功效受到准确表示不确定地形特征的挑战的阻碍。本文提出了一种基于学习的融合方法,用于在 BEV 中生成密集地形分类图。通过在多个尺度上执行 LiDAR 图像融合,我们的方法提高了从 RGB 图像和单次扫描 LiDAR 扫描生成的语义图的准确性。利用不确定性感知伪标签进一步增强了网络在越野环境中可靠学习的能力,而无需精确的 3D 注释。 |
| TinyGC-Net: An Extremely Tiny Network for Calibrating MEMS Gyroscopes Authors Cui Chao, Zhao Jiankang 由于微机电系统MEMS陀螺仪的误差复杂且非线性,目前依赖于线性模型或参数众多的网络的校准方法不足以满足低成本嵌入式计算平台同时实现精度和实时性的要求。在本文中,我们介绍了一个极其微小的网络 TGC Net,它表征了 MEMS 陀螺仪的测量模型。该网络具有少量参数,并且可以在部署到微控制器单元 MCU 之前在中央处理单元 CPU 上进行训练。 TGC Net 利用深度学习强大的数据处理能力,从碎片陀螺仪数据中导出非线性测量模型。随后,该模型用于回归陀螺仪数据的误差。此外,我们分析了MEMS陀螺仪的紧凑网络与传统线性模型之间的关系,并强调了足够的角运动刺激对于训练网络的重要性。基于公共数据集和现实世界场景的实验结果证明了该方法的实用性和有效性。 |
| A Reduced-Order Resistive Force Model for Robotic Foot-Mud Interactions Authors Xunjie Chen, Jingang Yi, Jerry Shan 腿式机器人非常适合在地形复杂的环境中执行广泛的探索任务。了解机器人足部地形相互作用对于腿式机器人的安全运动和行走效率至关重要。本文提出了机器人脚泥相互作用的降阶阻力模型。我们专注于机器人在泥浆上的垂直运动,并提出了粘弹塑性模拟来模拟足部泥浆相互作用力。所提出的模型明确讨论了泥浆粘弹性、撤回粘性吸力和屈服等动态行为。除了与干湿颗粒材料进行比较外,还进行了泥浆侵入实验来验证力模型。还研究了模型参数对含水量和足速的依赖性,以深入揭示各种条件下的模型特性。 |
| UniDoorManip: Learning Universal Door Manipulation Policy Over Large-scale and Diverse Door Manipulation Environments Authors Yu Li, Xiaojie Zhang, Ruihai Wu, Zilong Zhang, Yiran Geng, Hao Dong, Zhaofeng He 学习包含不同类别、几何形状和机制的门的通用操纵策略,对于未来的实体智能体在复杂而广泛的现实世界场景中有效工作至关重要。由于数据集有限和模拟环境不现实,之前的工作未能在各种门上取得良好的性能。在这项工作中,我们构建了一个新颖的门操作环境,反映了不同的现实门操作机制,并进一步为该环境配备了一个大规模的门数据集,涵盖 6 个门类别,包括数百个门体和把手,组成了数千个不同的门实例。此外,为了更好地模拟现实世界场景,我们引入了移动机器人作为代理,并使用部分和遮挡的点云作为观察,这在以前的工作中没有考虑,但对现实世界的实现具有重要意义。为了学习针对不同门的通用策略,我们提出了一个新颖的框架,将整个操纵过程分解为三个阶段,并通过相反的推理顺序训练来整合它们。 |
| Purpose for Open-Ended Learning Robots: A Computational Taxonomy, Definition, and Operationalisation Authors Gianluca Baldassarre, Richard J. Duro, Emilio Cartoni, Mehdi Khamassi, Alejandro Romero, Vieri Giuliano Santucci 自主开放式学习OEL机器人能够通过与环境的直接交互来累积获得新技能和知识,例如依靠内在动机和自我生成目标的指导。 OEL 机器人与应用具有高度相关性,因为它们可以使用自主获取的知识来完成与人类用户相关的任务。然而,OEL 机器人遇到了一个重要的限制,这可能会导致获取与完成用户任务不太相关的知识。这项工作分析了这一问题的可能解决方案,该解决方案以新的目的概念为基础。目的表明设计者和/或用户希望从机器人中得到什么。机器人应该使用目的的内部表示(这里称为欲望),将其开放式探索集中于获取与完成目标相关的知识。这项工作有助于以两种方式有目的地开发计算框架。首先,它基于三级动机层次结构形式化了一个目的框架,涉及目的 b 欲望,这些目标是独立于领域的 c 特定领域依赖的国家目标。其次,该工作强调了该框架所强调的关键挑战,例如目的欲望一致性问题、目的目标落地问题以及欲望之间的仲裁。 |
| Pseudo-Labeling and Contextual Curriculum Learning for Online Grasp Learning in Robotic Bin Picking Authors Huy Le, Philipp Schillinger, Miroslav Gabriel, Alexander Qualmann, Ngo Anh Vien 流行的抓取预测方法主要依赖于离线学习,忽视了实时适应新的拾取场景时发生的动态抓取学习。这些场景可能涉及以前未见过的物体、摄像机视角的变化以及箱配置等因素。在本文中,我们介绍了一种新颖的方法 SSL ConvSAC,它将半监督学习和强化学习结合起来进行在线掌握学习。通过将具有奖励反馈的像素视为标记数据,将其他像素视为未标记数据,它可以有效地利用未标记数据来增强学习。此外,我们通过提出基于上下文课程的方法来解决标记数据和未标记数据之间的不平衡问题。我们在现实世界评估数据上消除了所提出的方法,并展示了使用带有吸力夹具的物理 7 DoF Franka Emika 机器人手臂改善垃圾箱拣选任务在线抓取学习的前景。 |
| Demonstrating a Robust Walking Algorithm for Underactuated Bipedal Robots in Non-flat, Non-stationary Environments Authors Oluwami Dosunmu Ogunbi, Aayushi Shrivastava, Jessy W Grizzle 这项工作探索了一种创新算法,旨在增强欠驱动双足机器人在具有挑战性的地形上的移动性,特别是在穿过脚步或楼梯等脚部支撑机会有限的空间时。通过将脚踝扭矩与基于线性倒立摆模型 ALIP 的精细角动量相结合,我们的方法允许机器人质心高度的变化。我们采用双策略控制器,将跨基本自由度的精确运动调节的虚拟约束与以 ALIP 为中心的模型预测控制 MPC 框架相结合,旨在增强步态稳定性。我们的反馈设计的有效性通过其在具有 20 个自由度的 Cassie 双足机器人上的应用得到了证明。我们实现的关键是开发定制的标称轨迹和优化的 MPC,将执行时间减少到 500 微秒以下,因此与 Cassie 的控制器更新频率兼容。 |
| Exposure-Conscious Path Planning for Equal-Exposure Corridors Authors Eugene T. Hamzezadeh, John G. Rogers, Neil T. Dantam, Andrew J. Petruska 虽然最大化环境中特定区域或代理的视线覆盖范围是一个经过充分探索的路径规划目标,但在最小化检测风险的背景下,最小化导航期间对整个环境的暴露的相反问题尤其有趣。这项工作表明,最大限度地减少视线暴露在环境中是非马尔可夫的,传统的路径规划无法有效地解决这一问题。探讨了图搜索算法 A 的最优性差距以及几种近似启发式的最优性与计算时间的权衡。 |
| Bayesian Constraint Inference from User Demonstrations Based on Margin-Respecting Preference Models Authors Dimitris Papadimitriou, Daniel S. Brown 对于机器人来说,了解约束的存在对于获得安全策略至关重要。然而,明确指定环境中的所有约束可能是一项具有挑战性的任务。最先进的约束推理算法从演示中学习约束,但计算成本往往很高并且容易出现不稳定问题。在本文中,我们提出了一种新颖的贝叶斯方法,该方法根据对演示的偏好来推断约束。我们提出的方法的主要优点是:1. 无需在每次迭代时计算新策略即可推断约束;2. 使用简单且更现实的演示组排序,无需对所有演示进行成对比较;3. 适应存在以下情况的情况:是不同程度的约束违反。 |
| Behavior Generation with Latent Actions Authors Seungjae Lee, Yibin Wang, Haritheja Etukuru, H. Jin Kim, Nur Muhammad Mahi Shafiullah, Lerrel Pinto 从标记数据集中对复杂行为进行生成建模一直是决策中长期存在的问题。与语言或图像生成不同,决策需要对连续值向量进行建模,这些向量的分布是多峰的,可能来自未经策划的来源,其中生成错误可能会在顺序预测中复合。最近一类名为 Behavior Transformers BeT 的模型通过使用 k 均值聚类来离散化动作来捕获不同的模式来解决这个问题。然而,k 意味着难以扩展高维动作空间或长序列,并且缺乏梯度信息,因此 BeT 在建模长距离动作时受到影响。在这项工作中,我们提出了矢量量化行为转换器 VQ BeT,这是一种用于行为生成的多功能模型,可处理多模式动作预测、条件生成和部分观察。 VQ BeT 通过使用分层矢量量化模块对连续动作进行标记来增强 BeT。在包括模拟操纵、自动驾驶和机器人技术在内的七个环境中,VQ BeT 改进了 BeT 和扩散策略等最先进的模型。重要的是,我们证明了 VQ BeT 捕获行为模式的能力得到了提高,同时推理速度比扩散策略提高了 5 倍。 |
| Improved LiDAR Odometry and Mapping using Deep Semantic Segmentation and Novel Outliers Detection Authors Mohamed Afifi, Mohamed ElHelw 感知是实现智能自主导航的关键要素。了解周围环境的语义和准确的车辆姿态估计是自动驾驶汽车的基本能力,包括自动驾驶汽车和执行复杂任务的移动机器人。自动驾驶汽车等快速移动平台对定位和地图算法提出了严峻的挑战。在这项工作中,我们提出了一种基于 LOAM 架构的快速移动平台实时 LiDAR 里程计和测绘的新颖框架。我们的框架利用深度学习模型生成的语义信息来改进 LiDAR 扫描之间的点对线和点对平面匹配,并构建环境的语义图,从而使用 LiDAR 数据进行更准确的运动估计。我们观察到,在匹配过程中包含语义信息会为该过程引入一种新型异常匹配,其中匹配发生在同一语义类的不同对象之间。为此,我们提出了一种新颖的算法,可以在匹配过程中显式识别并丢弃潜在的异常值。在我们的实验中,我们研究了改进匹配过程对 LiDAR 里程计针对高速运动的鲁棒性的影响。 |
| Distributed Policy Gradient for Linear Quadratic Networked Control with Limited Communication Range Authors Yuzi Yan, Yuan Shen 本文提出了一种可扩展的分布式策略梯度方法,并证明了其在多智能体线性二次网络系统中收敛于接近最优解。代理在本地通信限制下参与指定的网络,这意味着每个代理只能与有限数量的相邻代理交换信息。在网络的底层图上,每个代理根据线性二次控制设置中的附近邻居状态来实现其控制输入。我们证明,仅使用局部信息就可以近似精确的梯度。与集中式最优控制器相比,随着通信和控制范围的增加,性能差距呈指数级减小到零。我们还演示了增加通信范围如何增强梯度下降过程中的系统稳定性,从而阐明关键的权衡。 |
| Autonomous vehicle decision and control through reinforcement learning with traffic flow randomization Authors Yuan Lin, Antai Xie, Xiao Liu 目前大多数基于强化学习的自动驾驶车辆决策和控制任务的研究都是在模拟环境中进行的。这些研究的训练和测试是在基于规则的微观流量下进行的,很少考虑将它们迁移到真实或接近真实的环境中来测试其性能。当在更真实的交通场景中测试训练后的模型时,可能会导致性能下降。在本研究中,我们提出了一种通过随机化 SUMO 中基于规则的微观交通流的汽车跟随模型和车道变换模型的某些参数来随机化周围车辆的驾驶风格和行为的方法。我们在高速公路和合流场景中基于域随机规则的微观交通流下使用深度强化学习算法训练策略,然后分别在基于规则的微观交通流和高保真微观交通流中进行测试。 |
| ActiveAD: Planning-Oriented Active Learning for End-to-End Autonomous Driving Authors Han Lu, Xiaosong Jia, Yichen Xie, Wenlong Liao, Xiaokang Yang, Junchi Yan 自动驾驶 AD 的端到端可微学习最近已成为一个突出的范例。一个主要瓶颈在于其对高质量标记数据的贪婪需求,例如3D 边界框和语义分割的手动注释成本非常高。由于 AD 样本中的行为经常受到长尾分布的影响,这一问题变得更加突出。换句话说,收集的大部分数据可能是微不足道的,例如只是在笔直的道路上向前行驶,只有少数情况对安全至关重要。在本文中,我们探讨了一个实际重要但尚未探索的问题,即如何实现端到端 AD 的样本和标签效率。具体来说,我们设计了一种面向规划的主动学习方法,该方法根据所提出的规划路线的多样性和有用性标准逐步注释部分收集的原始数据。根据经验,我们表明我们的面向计划的方法可以大大优于一般的主动学习方法。值得注意的是,我们的方法仅使用 30 个 nuScenes 数据就实现了与最先进的端到端 AD 方法相当的性能。 |
| A Zero-Shot Reinforcement Learning Strategy for Autonomous Guidewire Navigation Authors Valentina Scarponi MIMESIS, ICube , Michel Duprez ICube, MIMESIS , Florent Nageotte ICube , St phane Cotin ICube, MIMESIS 目的 心血管疾病的治疗需要复杂且具有挑战性的导丝和导管导航。这通常会导致长时间的干预,在此期间患者和临床医生都会暴露在 X 射线辐射下。深度强化学习方法在学习这项任务方面显示出了希望,并且可能是机器人干预期间自动化导管导航的关键。然而,现有的训练方法在推广看不见的血管解剖结构方面表现出有限的能力,每次几何形状发生变化时都需要重新训练。方法在本文中,我们提出了一种用于三维自主血管内导航的零样本学习策略。使用非常小的分支模式训练集,我们的强化学习算法能够学习一种控制,然后可以将其应用于看不见的血管解剖结构,而无需重新训练。结果 我们在 4 个不同的血管系统上演示了我们的方法,在这些解剖结构上达到随机目标的平均成功率为 95。我们的策略计算效率也很高,只需 2 小时即可完成控制器的训练。 |
| FastOcc: Accelerating 3D Occupancy Prediction by Fusing the 2D Bird's-Eye View and Perspective View Authors Jiawei Hou, Xiaoyan Li, Wenhao Guan, Gang Zhang, Di Feng, Yuheng Du, Xiangyang Xue, Jian Pu 在自动驾驶中,与传统感知任务(例如 3D 对象检测和鸟瞰 BEV 语义分割)相比,3D 占用预测可输出体素状态和语义标签,以便更全面地理解 3D 场景。最近的研究人员广泛探索了这项任务的各个方面,包括视图转换技术、地面实况标签生成和精心设计的网络设计,旨在实现卓越的性能。然而,对于自动驾驶车辆运行至关重要的推理速度却被忽略了。为此,提出了一种称为 FastOcc 的新方法。通过仔细分析输入图像分辨率、图像主干、视图变换和占用预测头四个部分的网络效应和延迟,发现占用预测头在加速模型同时保持其准确性方面具有相当大的潜力。为了改进这个组件,耗时的 3D 卷积网络被一种新颖的残差式架构取代,其中特征主要由轻量级 2D BEV 卷积网络消化,并通过集成从原始图像特征插值的 3D 体素特征进行补偿。 |
| World Models for Autonomous Driving: An Initial Survey Authors Yanchen Guan, Haicheng Liao, Zhenning Li, Guohui Zhang, Chengzhong Xu 在快速发展的自动驾驶领域,准确预测未来事件并评估其影响的能力对于安全性和效率至关重要,对决策过程有重要帮助。世界模型已经成为一种变革性方法,使自动驾驶系统能够合成和解释大量传感器数据,从而预测潜在的未来场景并弥补信息差距。本文对自动驾驶世界模型的现状和未来进展进行了初步回顾,涵盖其理论基础、实际应用以及旨在克服现有局限性的持续研究工作。 |
| Collision Avoidance and Geofencing for Fixed-wing Aircraft with Control Barrier Functions Authors Tamas G. Molnar, Suresh K. Kannan, James Cunningham, Kyle Dunlap, Kerianne L. Hobbs, Aaron D. Ames 在航空航天控制中,安全关键故障通常会造成致命后果。因此,飞机上的控制系统必须确保严格满足安全约束,最好有安全行为的正式保证。本文建立了固定翼飞机在防撞和地理围栏任务中的安全关键控制。开发了一种控制框架,其中运行时间保证 RTA 系统在必要时调节飞机的标称飞行控制器,以防止其与其他飞机相撞或跨越空间中的边界地理围栏。 RTA 被制定为使用控制屏障功能 CBF 的安全过滤器,并具有安全行为的正式保证。针对非线性运动固定翼飞机模型构建并比较了 CBF。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com
这篇关于【AI视野·今日Robot 机器人论文速览 第八十三期】Wed, 6 Mar 2024的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








