2019独角兽企业重金招聘Python工程师标准>>> 
前言
在刘慈欣的科幻小说《三体3·死神永生》中,歌者使用二向箔对太阳系进行降维打击,使其所处的空间维度由三维降低至二位,进而毁灭目标。而在 Apache Kylin 中也存在着类似“降维打击”的工具—— Cube Planner。Cube Planner 机制通过计算不同 Cuboid 的构建成本和收益,并结合用户查询的统计数据挑选出更精简更高效的维度组合,从而减少构建 Cube 的时间和空间,提高查询效率。
Cube Planner 功能由 eBay 工程师 Wang Ken、Qian Qiaoneng、Zhong Yanghong、Ma Gang 及 Pan Julian 等贡献至开源社区,感谢他们!本文部分图片和内容来自于eBay技术博客[2]
背景介绍
Apache Kylin™ (以下简称Kylin) 是一个开源的分布式分析引擎,最初由eBay于2014年贡献给 Apache 基金会。Kylin 提供 Hadoop 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,能在亚秒级的时间内返回查询结果。
Kylin 的核心在于 Cube 的设计和构建,它把原始表中的数据按照用户选择的维度进行预处理,然后把结果 (Cube)加载到存储引擎(默认 HBase) 里,供用户查询使用。数据分析师可以在 Web UI 中输入 SQL,或者通过可视化分析工具选择任意的维度和指标来定制自己的分析报告。
我们知道,在没有采取任何优化措施的情况下,Kylin 会对每一种维度的组合进行预计算,每种维度组合的预计算结果被称为 Cuboid,这些 Cuboid 组成了 Cube。假设数据有10个维度,那么没有经过任何剪枝优化的 Cube 就会有 210=1024个 Cuboid;如果有20个维度,那么 Cube 就会有超过一百万个 Cuboid。
毫无疑问,如此庞大数量的 Cuboid 会给计算和存储带来极大的压力,所以 Kylin 设置了 kylin.cube.aggrgroup.max-combination 参数来限制 Cuboid 的最大数量,在过去这个参数默认为 4096。也就是说,如用户定义的 Cube 包含了超过 4096 个 Cuboid 就无法保存,需要手动优化后才能继续。这种限制在大量维度的场景下对用户很不方便,且增加了额外的工作量。另一方面,在很多规模较大的机构里,数据提供者和使用者不是同一部门,数据提供者对数据的查询模式并不是特别熟悉,数据分析师为了掌握优化 Cube 的技巧需要更多的学习成本。
Kylin 在 2.3.0 版本引入了 Cube Planner,自动地对 Cube 的结构进行优化。如下图所示,在用户定义的 Aggregation Group 等手动优化基础上,Cube Planner 自主挑选 Cuboid,帮助用户构建一个更高效的 Cube,实现对 Cube 的“二次瘦身” ,最终减少预计算的工作量和存储所需空间。

减枝的原则
Cube Planner 本质上就是从 2N 种维度组合中挑选出部分维度组合添加到进 recommendCuboidList 中以进行后续的构建。问题的关键在于剪枝的标准,对于某种可能的维度组合只有两种结果:被预计算和不被预计算,这取决于加入这个 Cuboid 产生的收益除以成本(效益比)。
Cuboid 的成本:
构建成本:取决于该维度组合的数据行数。
查询成本:取决于查询该 Cuboid 所需要扫描的行数。
由于往往构建是一次性的,而查询是重复性的,因此我们忽略构建成本,只使用查询成本来计算。
Cuboid 的效益:即预计算出这个 Cuboid,相比没有这个 Cuboid 对整个 Cube 的所有查询所能减少的查询成本。
下面分别通过贪心算法和基因算法的例子,更直观地展示 Cube Planner 的选择过程。
贪心算法
贪心算法使用多轮迭代,每次选出当前状态下最优的一种维度组合加入 recommendCuboid List。假设有一个 Cube,它有如下的维度组合:

各个维度组合之间的父子关系如下图所示,括号里的数字表示(该维度组合的行数,查询该维度组合的开销)

1)因为维度组合 a 是 Base Cuboid,默认一定会被预计算,所以将 a 加入 recommendCuboidList。在当前只有 a 被计算出的情况下,查询剩余所有维度组合的数据都只能通过它们的祖先a,成本均为100(扫描a所需的行数)。
2)估算 b 的收益比。如果预计算 b,那么对 b 和其子孙 d,e,g,h 这 5种维度组合的查询都可以通过扫描50行的 b Cuboid 来得到。相比直接扫描 a,查询成本从100减少至50,因此预计算 b 对整个 Cube 的增益为(100-50)*5,而效益比就是增益再除以 b 的行数:(100-50)*5/50=5。

3)按(2)的方法依次计算 c,d,e,f,g,h 的效益比:
C:(100-75)*5/75=1.67D:(100-20)*2/20=8E:(100-30)*3/30=7F:(100-40)*2/30=3G: (100-5)*1/5=19H:(100-10)*1/10=9
可见 g 是效益比最高的维度组合,因此第一轮挑选维度组合 g 加入到 recommendCuboidList中。

4)重复(2) (3)的步骤,每轮迭代都加入一种维度组合。
5)结束条件:
-
recommendCuboidList里的维度组合膨胀率达到既定的Cube膨胀率。(由kylin.cube.cubeplanner.expansion-threshold决定,默认值15)
-
本轮选中的维度组合效率比低于既定最小阈值(默认0.01)。这个说明新增加的维度组合性价比已经不高了,不需要再挑选更多的维度组合。
-
挑选算法运行时间到达既定上限。
基因算法
基因算法的核心思想是交叉变异,优胜劣汰,主要步骤包括选择->交叉->变异。
每个 Cuboid 是一个基因,一种 Cuboid 组合是一个染色体,染色体用01串表示,其中1表示该 Cuboid 在这个 Cube 里出现,0表示不出现。例如:Cuboid Set{O1, O2, O3, O4, O5, O6, O7, O8, O9, O10},染色体{0110011001}表示这个 Cube 包含了{ O2, O3, O6, O7, O10}这五个Cuboid。每个染色体的 Fitness 计算方法与贪心算法类似。
在这个例子中,Cuboid组合{a, g}的 total Benefit 为:(100*8-(100+100+100+100+100+100+5+100))=95
再考虑 Cuboid 的成本,加入惩罚函数后Fitness的表达式如下:Fitness=totalBenfit*min(1,baseCuboidSpaceCost*expansionRate/totalSpaceCost)

1)初始化种群
随机生成一些01串作为初始种群,代表一些可能的Cuboid组合。
2)选择(selection)
采用轮盘赌选择算法(roulettewheel selection)挑选出两个染色体,某个染色体被选中的概率和它的Fitness成正比。

3)交叉(crossover)
两个父染色体以一定规则交换部分基因,生成新的染色体。以最简单的单点交叉为例:
11001 011 + 11011 111
=>11001111 11011011
4)变异(mutation)
在交叉的结果中以一定比例随机选择某一位进行反转将结果加入种群。
11001111 => 11001011
5)终止条件
-
后代数量达到上限(默认550)
-
前后两代Fitness差异度很小
达到上述两个条件之一,即可终止迭代。
注:基因算法的各种参数采用 Wen-YangLin[3]研究得出的值,用户无需关心。
以上两种算法都存在一个问题,就是它们在计算收益 Benefit 的时候是假设所有的查询请求都均匀地分布在每一种维度组合内,而这显然是不现实的。在生产环境下,用户的查询一定会集中于部分重要的 Cuboid。有些维度组合被预计算了,但是没有查询到;或者是有些维度组合经常被查询,但是没有被预计算出来,这些差距影响了 Cube 的资源利用率和查询性能。Kylin Cube Planner 在 Phase Two 来处理这种情况。要使用 Cube Planner Phase Two,用户需要开启 System Cube, 并运行一段时间的查询分析,以供 Kylin 掌握用户查询分析的模式和频率。
如何使用Cube Planner
Cube Planner 会根据优化前的维度组合数量来选择使用贪心算法还是基因算法。默认情况下,223 以上个维度组合使用基因算法优化;数量在 28~223 之间的使用贪心算法优化,少于 28=256 则不做优化。上述阈值由 kylin.cube.cubeplanner.algorithm-threshold-greedy 和 kylin.cube.cubeplanner.algorithm-threshold-genetic 这两个参数决定。
在开启 kylin.cube.cubeplanner.enabled=true 之后,Cube Planner 会在以下两个阶段产生作用:
Phase One(适用于初次构建的Cube)
在物化 Cube 之前,Kylin 会利用 Extract Fact Table Distinct Columns 步骤中得到的采样数据,预估出每个 Cuboid 的大小。如果开启了 Cube planner, 并且是第一次构建,那么 Kylin 会基于用户初步剪枝的 Cube,根据上文所提到的算法生成 recommendCuboidList并记录下来,随后用 Spark/Hadoop 引擎进行构建。在这之后的 segment 的构建,将使用同样的 recommendCuboidList 进行;由于新创建的 Cube没有查询统计数据,Phase One 假设查询每个维度组合的概率相同。
下图是开启 Cube Planner 前后的 Cube sunburst 图对比。同样是四百多万条数据,未开启时用了512个 Cuboid 来构建,占空间9.12GB。而右边开启 Cube Planner 后 Cuboid 数量减少至152个,占空间2.91GB,减少了约70%,另外构建时间也有相应缩短。

Phase two(适用于已运行一段时间的Cube)
与 Phase One 不同的是,Phase Two 需要首先建立 System Cube 来收集 Query 的统计数据,具体步骤参照官方文档。
Phase Two 发生在 Cube 构建完成并使用一段时间之后,这时 Kylin 的 Metrics 积累了一些 Query 统计数据。用户在 Kylin 的 Web UI 中查看 Cube 的 sunburst 图可以了解 Cuboid 的冷热状况,并通过 Optimize 按键来触发优化。Cube Planner 从 System Cube 中读取这些统计信息,作为上文描述的算法中 Cuboid 效益的权重,重新规划和构建 Cuboid。

为了使得在重新构建的过程中仍然可以继续查询原有 Cube,Kylin 采用 OptimizeJob 和 CheckpointJob 两个专有任务,这样既保证了优化过程的并发度,又保证了优化后数据切换的原子性。OptimizeJob 不会重新计算所有推荐的维度组合,而是只计算那些推荐维度组合集里新增的组合,重用那些在原来的 Cube 里已经预计算出来的Cuboid,这样可以很大程度上节省优化的资源开销。此外,用户还可以通过下方的 Export 按键来导出 Top Cuboid 以供下次构建 Cube 时使用。


Cube Planner在eBay的应用
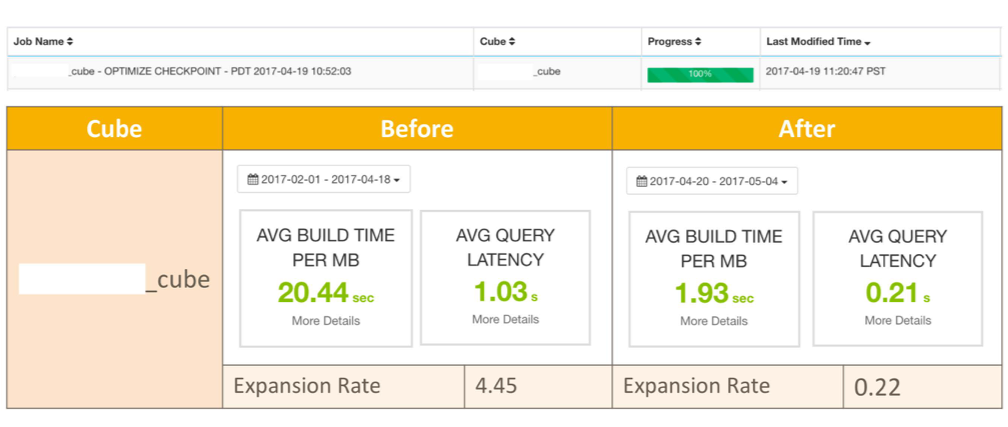
Cube Planner 在2017年2月份正式上线到 eBay 的生产环境后,得到用户们的高度评价和一致认可。下面是 eBay 生产线上使用 Cube Planner 进行优化的一个案例,客户在4月19号进行了 cube 优化,优化之后的 cube,不仅构建性能有大幅提升,查询性能也改善不少。
未来工作
-
目前的 Phase Two 需要定期构建 System Cube,这套操作对于用户来说还是有些复杂。如果能够简化流程,在启动 Kylin 时自动设置,用户使用起来就更加方便了。
-
未来利用机器学习算法使得 Cube Planner 的推荐更加智能化。
总结
Cube planner 功能在 kylin2.3.0 中被引入,并在新发布的 kylin2.5.0 中默认开启。在kylin 2.5.0中,kylin.cube.aggrgroup.max-combination 的默认值由4096提高到32768,这意味着用户可以定义出拥有更多维度的 Cube,而把剪枝的工作留给 Cube Planner。Cube Planner 有两个阶段的优化,第一阶段使用门槛低,用户可以很快看到效果;第二阶段需要统计收集查询历史,会更加准确地进行优化。
Cube 的设计是 Kylin 的核心,一个高效的 Cube 对整个 Kylin 的性能有极大帮助。Cube Planner 帮助我们找到更重要的 Cuboid,提高资源利用率和查询效率。同时,它也能降低设计 Cube 的门槛,让更多的人更轻松地使用 Kylin。
与此同时,作为 Apache Kylin 企业级产品,Kyligence Enterprise 提供了更加业务导向的模型与 Cube 优化能力。用户无需成为多维建模专家,系统可以根据业务查询历史或常用查询,自动创建或优化模型与 Cube。
再次感谢 eBay 大数据团队对 Apache Kylin 社区的贡献!
参考文献:
[1] kylin.apache.org. Use Cube Planner
[2]Qiaoneng Qian. 干货┃Cube Planner 系列之高效智能构建 Kylin OLAP Cube
[3] Wenyang Lin, I-Chung Kuo. A Genetic Selection Algorithm for OLAPData Cubes.
[4] Yanghong Zhong. Cost-based Cube Planner.
相关JIRA:
https://issues.apache.org/jira/browse/KYLIN-2727
https://issues.apache.org/jira/browse/KYLIN-2946
https://issues.apache.org/jira/browse/KYLIN-3521
作者简介
周浥尘,南加州大学研一学生(高性能计算方向),本科就读于南京大学计算机系。曾在Intel数据中心部门实习,专注于大数据和分布式技术,目前在 Kyligence 从事 Apache Kylin 的开源工作。






