kylin专题

Apache Kylin VS Apache Doris全方位对比
1 系统架构 1.1 What is Kylin1.2 What is Doris2 数据模型 2.1 Kylin的聚合模型2.2 Doris的聚合模型2.3 Kylin Cuboid VS Doris RollUp2.4 Doris的明细模型3 存储引擎4 数据导入5 查询6 精确去重7 元数据8 高性能9 高可用10 可维护性 10.1 部署10.2 运维10.3 客服11 易用性 11.1
Apache Kylin 在美团数十亿数据 OLAP 场景下的实践
大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! By 大数据技术与架构 场景描述:美团各业务线存在大量的OLAP分析场景,需要基于Hadoop数十亿级别的数据进行分析,直接响应分析师和城市BD等数千人

Kylin使用Spark构建Cube
Apache Kylin™是一个开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由eBay Inc. 开发并贡献至开源社区。它能在亚秒内查询巨大的Hive表。下面是单机安装采坑记,直接上配置和问题解决。找一台干净的机器,把hadoop hive hbase从原有节点分别拷贝一份,主要目的是配置文件,可以不在kylin所在机器
Apache Kylin | 麒麟出没,必有祥瑞
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 大数据技术与架构 点击右侧关注,大数据开发领域最强公众号! 暴走大数据 点击右侧关注,暴走大数据! 前言 随着移动互联网、物联网等技术的发展,近些年人类所积累的数据正在呈爆炸式的增长,大数据时代已经来临。但是海量数据的收集只是大数据技术的第一步,如何让数据产生价值才是大数据领域的终极目标。Hadoop的出现解决了数据存储问

一站式大数据解决方案分析与设计实践 | BI无缝整合Apache Kylin
点击上方蓝色字体,选择“设为星标” 回复”资源“获取更多资源 本文已收录于Github仓库:《大数据成神之路》 地址:https://github.com/wangzhiwubigdata/God-Of-BigData 研发背景 今天随着移动互联网、物联网、大数据、AI等技术的快速发展,数据已成为所有这些技术背后最重要,也是最具价值的“资产”,同时数据也是每一个商业决策的基石,越来越多的

大数据面试通关手册 | Kylin入门/原理/调优/OLAP解决方案和行业典型应用
Kylin入门/原理/调优/OLAP解决方案和行业典型应用一网打尽。 一:背景历史和使命 背景和历史 现今,大数据行业发展得如火如荼,新技术层出不穷,整个生态欣欣向荣。作为大数据领域最重要的技术的 Apache Hadoop 最初致力于简单的分布式存储,然后在此基础之上实现大规模并行计算,到如今在实时分析、多维分析、交互式分析、机器学习甚至人工智能等方面有了长足的发展。 2013 年年初,在

5-Kylin Java Restful API
最近在做大数据方面的开发, 学习研究了一段时间的kylin系统, 对于前端开发需要使用 RESTful API ,但是官网并没有提供详细的Java API. 经过几天的看文档,最终写出了 Java 的API,不敢私藏,特分享与大家. 1 import java.io.BufferedReader;2 import java.io.InputStream;3 import jav

4-apache kylin企业级开源大数据分析平台
转:http://www.thebigdata.cn/JieJueFangAn/30143.html 我先做一个简单介绍我叫史少锋,我曾经在IBM、eBay做过大数据、云架构的开发,现在是Kyligence的技术合伙人。 Kylin是这两年在国内发展非常快的开源大数据项目。今天大会合作厂商中有超过一半的企业已经在使用或者正在试用Kylin,应主办方邀请,今天跟大家做一个关于如

3-KYLIN订单例程
转:http://blog.itpub.net/30089851/viewspace-2122586/ 一.Hive订单数据仓库构建 1. 创建事实表并插入数据 DROP TABLE IF EXISTS default.fact_order ; create table default.fact_order ( time_key string, product_key stri


麒麟kylin v10 sp3 升级glibc2.28 到 2.31
1. 下载glibc 2.31 wget https://mirrors.aliyun.com/gnu/glibc/glibc-2.31.tar.gz 2.解压 tar -xf glibc-2.31.tar.gz cd glibc-2.31 mkdir build && cd build 3.修改 vim ../Makefile 125行添加一行 yum reinstall

Kylin源码解析——Cube构建过程中如何实现降维
-维度简述 Kylin中Cube的描述类CubeDesc有两个字段,rowkey和aggregationGroups。 @JsonProperty("rowkey")private RowKeyDesc rowkey;@JsonProperty("aggregation_groups")private List<AggregationGroup> aggregationGroups; 其
Kylin搭建需要添加的环境变量
在/etc/profile中新增环境变量配置: export HADOOP_USER_NAME=hdfs export SPARK_HOME=/opt/cloudera/parcels/CDH/lib/spark export HBASE_HOME=/opt/cloudera/parcels/CDH/lib/hbase export HIVE_HOME=/opt/cloudera/parcels/
Kylin报错 FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException...
Kylin接入Hive数据时,报错如下: FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaSt
Kylin报错 Permission denied: user=root, access=WRITE, inode=/user:hdfs:superxxx
Kylin启动后,执行 ./bin/sample.sh 脚本 报错如下: Permission denied: user=root, access=WRITE, inode="/user":hdfs:superxxxxx 说明运行当前shell不能写入hdfs目录/user/xxxx。 解决方法是使用root用户 vim /etc/profile 写入 export HADOOP_
kylin-v10sp2-Babelfish for PostgreSQL
环境准备 x86_linux_kylin v10 sp2 1、依赖 yum makecacheyum install -y uuid-devel 2、源代码 下载支持babelfish的pg,也是babelfish社区维护更新 cd /opt#pg源码,支持babelfish版git clone https://github.com/babelfish-for-postgresql

kylin v10 离线安装chrome
1. 先用自己联网的计算机,下载离线安装包,浏览器输入链接下载安装包: https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm 1.2. 信创环境不用执行下面,因为没网 1.3. 若为阿里云服务器,或服务器有网则是直接下载到安装机: wget https://d
麒麟Kylin | 操作系统的安装与管理
以下所使用的环境为:VMware Workstation 17 Pro、Kylin-Server-10-SP2-x86-Release-Build09-20210524 一、创建虚拟机 在VMware主机单击【创建新的虚拟机】 **在新建虚拟机向导中选择【自定义】,然后点击【下一步】 ** 保持默认选项,然后点击下一步 选择【稍后安装操作系统】 客户机操作系统选择【L
Kylin V10 Server 下TongRDS独立哨兵服务配置手册
一、网络架构设计 部署类型 目录 IP Port 中心节点 /opt/rds/pcenter 10.8.3.34 6300 服务节点 /opt/rds/pmemedb 10.8.3.35 TongRDS 协议端口:6200 Redis 仿真端口:6379 哨兵监听端口:26379 10.8.3.36 二、部署服务节点 1.查看操作系统信息 [root@loca
新安装Ubuntu Kylin 16.04系统,一个软件安装整理清单
新安装Ubuntu Kylin 16.04系统,一个软件安装整理清单 又重装系统了,我的内心是悲催的。顺便试试ubuntu最新版本 列个清单,省得以后还要再到处搜。 新系统下的软件安装 用MarkPad不熟练,排版不好。 安装vim sudo apt install vim安装Java环境 安装oracle的java而非openjdk。 将解压好的jdk1.7.0_04文件夹用最高

Apache Kylin 入门介绍与学习资源
近日 Kylin v2.6.4 版本发布,包含很多问题修复与各种改进。翻阅三年前写的Kylin测试文档,当时版本还是1.5.3。近两年 Kylin 版本迅速迭代,社区不断发展,已经成为 Hadoop 生态中不可或缺的 OLAP 引擎。 01 Kylin 介绍 Apache Kylin(麒麟)是由eBay开源的分布式分析引擎,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)

MLSQL:一分钟让 Kylin 装备 ETL 能力
在上周举办的 Apache Kylin + MLSQL Meetup 中,我们邀请了来自 MLSQL 社区的技术大佬 祝威廉 来进行分享。大家都知道 Kylin 一向以强大的分析能力和丰富的周边生态而备受欢迎,但是 Kylin 自身还欠缺一些 ETL 能力。在本次分享中,祝威廉演示了如何在 Kylin 中快速完成数据处理,用户不用离开 Kylin 即可完成大规模数据分析整个 Pipeline,同

如何在Windows 7系统下安装Ubuntu-Kylin 16.04 LTS 构成双系统
一:安装前的准备工作: 1.下载相应的Ubuntu的镜像。点击下载 2.准备一个U盘,使用软碟通,编辑Ubuntu光盘镜像文件,做一个U盘启动盘。 3.安装EasyBCD,这个软件是用于系统配置创建多重启动系统。 4.下载DiskGenius,结合本地磁盘管理,压缩出一个适当大小的空闲空间(一般20G足以),压缩出的空闲空间格式化成一个逻辑分区,文件系统FAT32。 二:用EasyBCD
Kylin的基本介绍
一、定义与背景 Kylin是一款开源的分布式分析引擎,主要用于处理OLAP(联机分析处理)多维查询。它最初由eBay开发并贡献至开源社区,为Hadoop/Spark之上的数据提供SQL查询接口及多维分析(OLAP)能力,以支持超大规模数据。 二、特点 支持SQL接口:Kylin以标准的SQL作为对外服务的接口,方便用户进行数据查询和分析。支持超大规模数据集:Kylin对于大数据的支撑能力
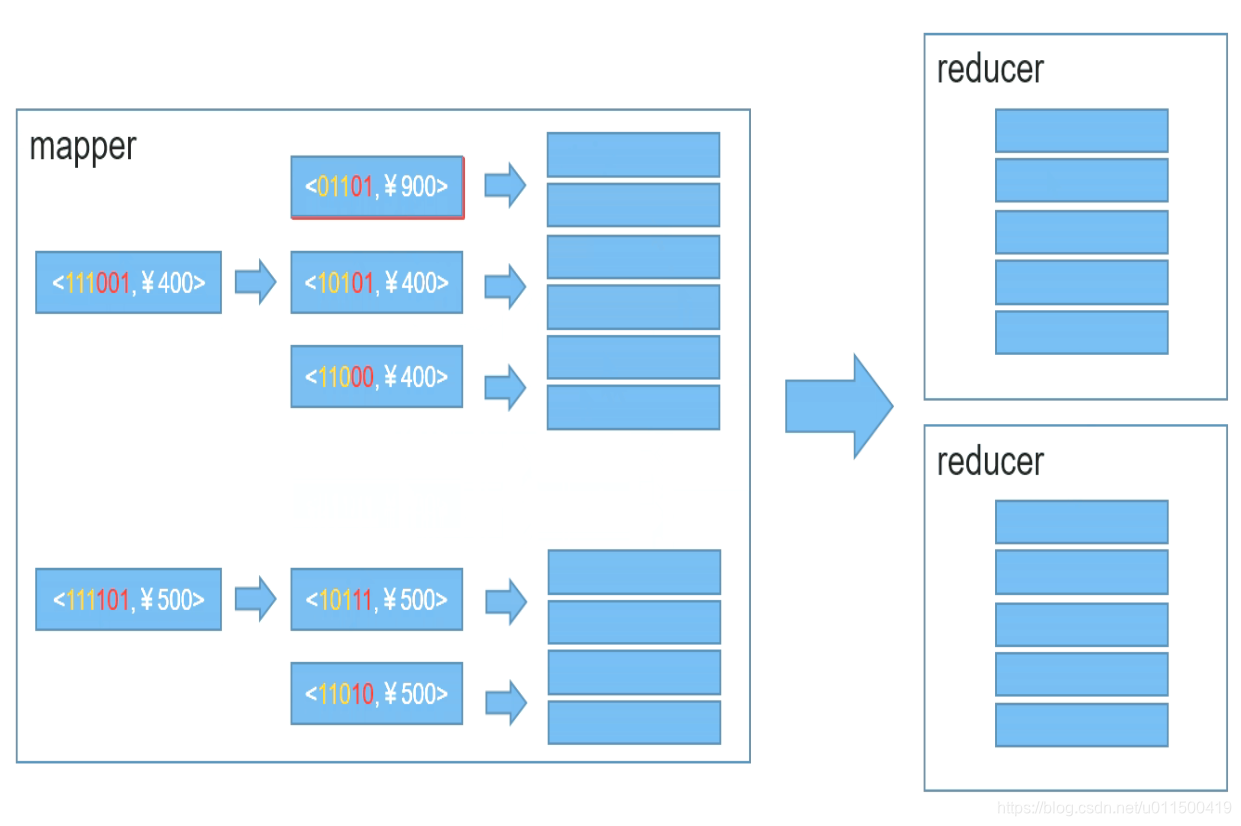

【详细的Kylin使用心得,什么是Kylin?】
🌈个人主页: 程序员不想敲代码啊 🏆CSDN优质创作者,CSDN实力新星,CSDN博客专家 👍点赞⭐评论⭐收藏 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步! 💫Kylin.🔥 💫Kylin是一款Linux发行版,由中国国内的开发者团队开发,在中国颇受欢迎,尤其是在政府和企业中。Kylin的设计旨在满足中国用户的特定需求,并且在