本文主要是介绍Hadoop2.6.2完全分布式集群HA模式安装配置详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、机器配置清单(8节点)
- hadoop100
节点:NameNode、DFSZKFailoverController(ZKFC) - hadoop101
节点:NameNode、DFSZKFailoverController(ZKFC) - hadoop102:
节点:ResourceManager - hadoop103:
节点:ResourceManager - hadoop104:
节点:DataNode、NodeManager、JournalNode、QuorumPeerMain、ZooKeeper - hadoop105:
节点:DataNode、NodeManager、JournalNode、QuorumPeerMain、ZooKeeper - hadoop106:
节点:DataNode、NodeManager、JournalNode、QuorumPeerMain、ZooKeeper - hadoop107:
节点:DataNode、NodeManager
二、解压安装配置相关软件
-
JAVA_HOME=/usr/java/jdk1.7.0_71
(配置环境变量略过,请自行搜索) -
HADOOP_HOME=/hadoop/hadoop-2.6.2
三、修改hosts配置文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18

四、在hadoop104、hadoop105、hadoop106安装Zookeeper
-
安装目录:
/hadoop/zookeeper-3.4.6/ -
修改配置:
-
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
五、配置Hadoop(cd /hadoop/hadoop-2.6.2/etc/hadoop/)
1.vim hadoop-env.sh
AVA_HOME=/usr/java/jdk1.7.0_71
2.vim core-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3.vim hdfs-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
4.vim mapred-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.vim yarn-site.xml
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
6.vim slave (hadoop100、hadoop101、hadoop102、hadoop103机器填写)
- 1
- 2
- 3
- 4
- 5
六、启动过程
1.启动zookeeper集群(在主机名hadoop104、hadoop105、hadoop106上启动)
- 1
- 2
- 3
- 4
- 5
- 6
2.启动journalnode(分别在在主机名(ip)04、主机名(ip)05、主机名(ip)06上执行)
- 1
- 2
- 3
- 4
- 5
3.格式化namenode(hadoop100)
- 1
- 2
4.格式化ZKFC(在hadoop100上执行)
- 1
5.NameNode从hadoop100同步到hadoop101
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6.启动NameNode和DataNode
- 1
- 2
- 3
- 4
- 5
7.启动yarn(在hadoop102执行)
- 1
- 2
- 3
- 4
- 5
- 6
8.启动ZookeeperFailoverController(hadoop100和101执行)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
七、完工~
- 打开浏览器查看hadoop100(namenode显示active)
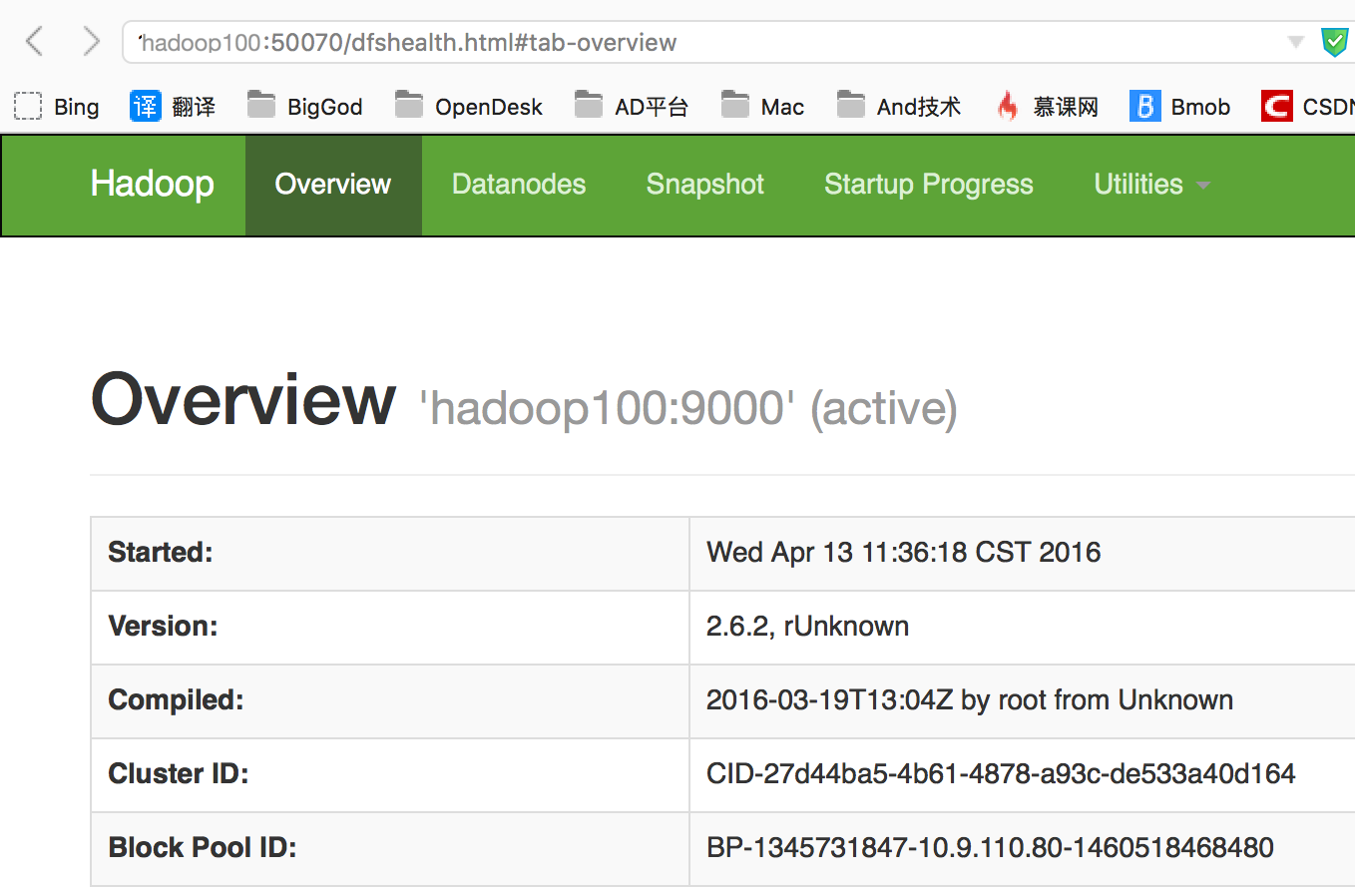
- 查看hadoop101(namenode显示standby)
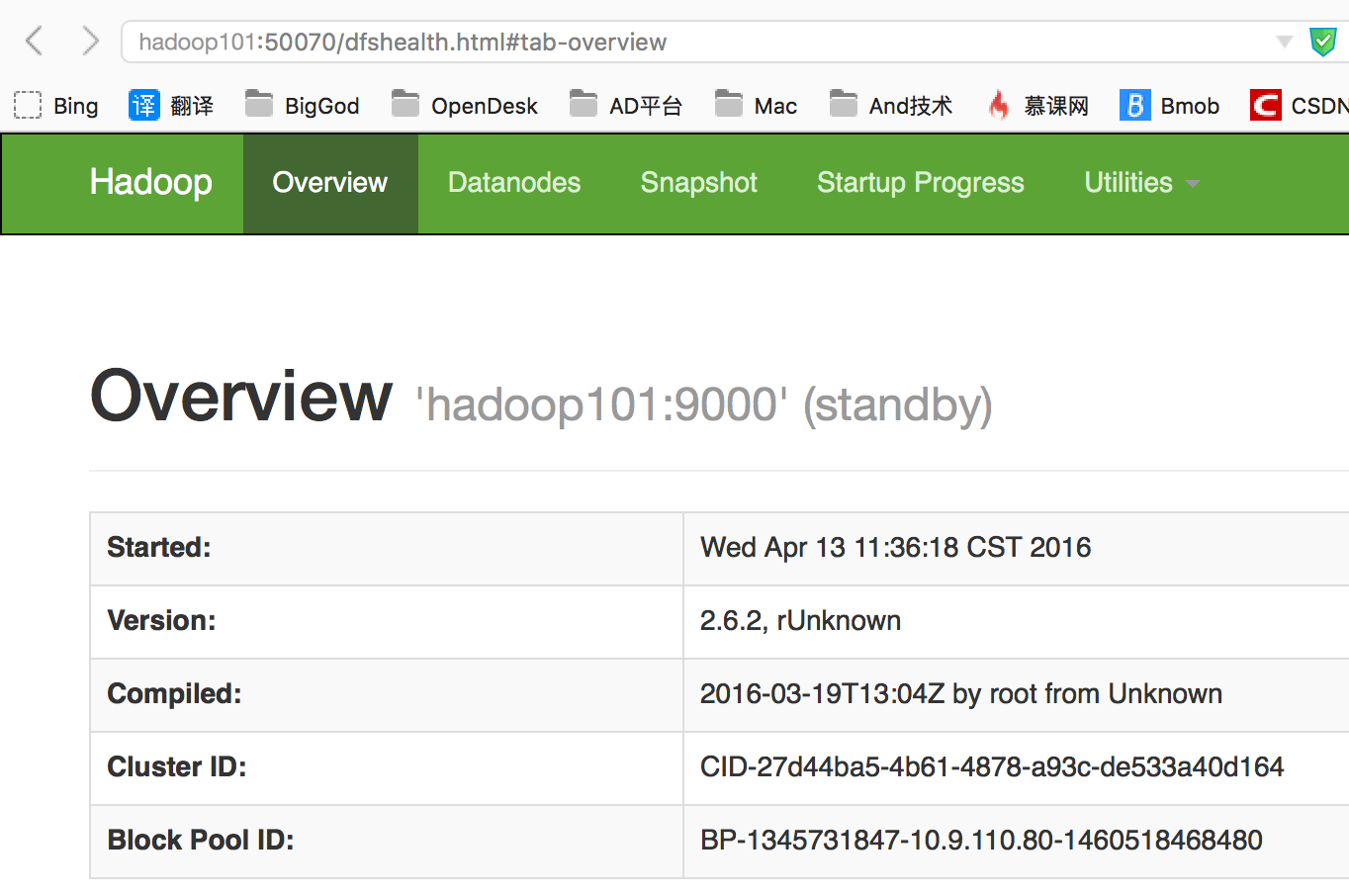
- 查看各个datanode节点
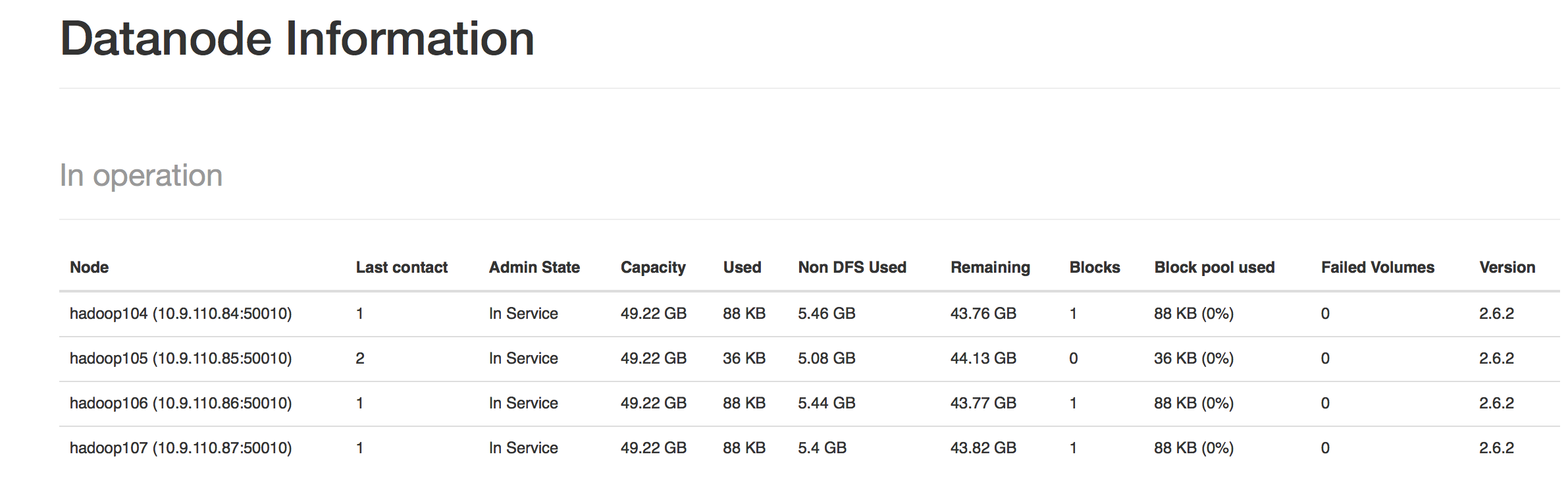
- 工作正常,上传个文件试试吧~
这篇关于Hadoop2.6.2完全分布式集群HA模式安装配置详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






