hadoop2.6专题

hadoop2.6.0安装详细步骤
文章目录 1.简述2. 安装步骤1. linux环境准备1.基础环境规划2. host配置和主机名(四台)3. 安装jdk 2. linux免密登录配置1. 关闭四台服务器的防火墙和SELINUX2. 免密码登录1. 保证本机能够免密登录本机2. 设置机器之间的免密登录 3. hadoop 安装1. master上 解压缩安装包及创建基本目录2. 配置master的hadoop环境变量3.
CDH5.7.1 Hadoop2.6 HDFS Encryption KMS 实战之功能测试
CDH KMS 测试 0、用户说明 [x] keyAdminUser用户是key admin user[x] hdfs 用 户是 hdfs super user[x] user_a 、 user_b 是HDFS普通用户 1、创建keytab 按照下面的办法创建keytab addprinc -randkey ouruixst -norandkey -k ourui.keytab our

hadoop2.6.0-cdh5.15.1编译源码支持压缩
如果不想自己编译,可以直接从我这里直接下载 链接:https://pan.baidu.com/s/1jUTH-29rdKwAJ0_5vRQ1iA 密码:7juw 文章目录 一 为什么要编译二 环境条件三 安装依赖四 安装软件4.1 jdk1.74.2 maven4.3 protobuf 五 编译hadoop六 伪分布式部署 一 为什么要编译 直接从官网上下载的hadoop-2

sqoop1.4.6离线部署于hadoop2.6之上与hive导入导出数据
1) .下载最新的sqoop1.4.6安装包 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar 2) . 解压到/usr/local,跟hadoop同一级别 # tar -xzvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /usr/local# mv sqoop-1.4.6.bin__hadoop-2.0.4

hadoop2.6快速离线部署
1. 关闭防火墙 -# firewall-cmd --state-# systemctl stop firewalld.service-# systemctl disable firewalld.service-# vi /etc/selinux/configSELINUX=disabled ,然后重启 2) 虚拟机IP配置 BOOTPROTO=staticIPADDR=192.1
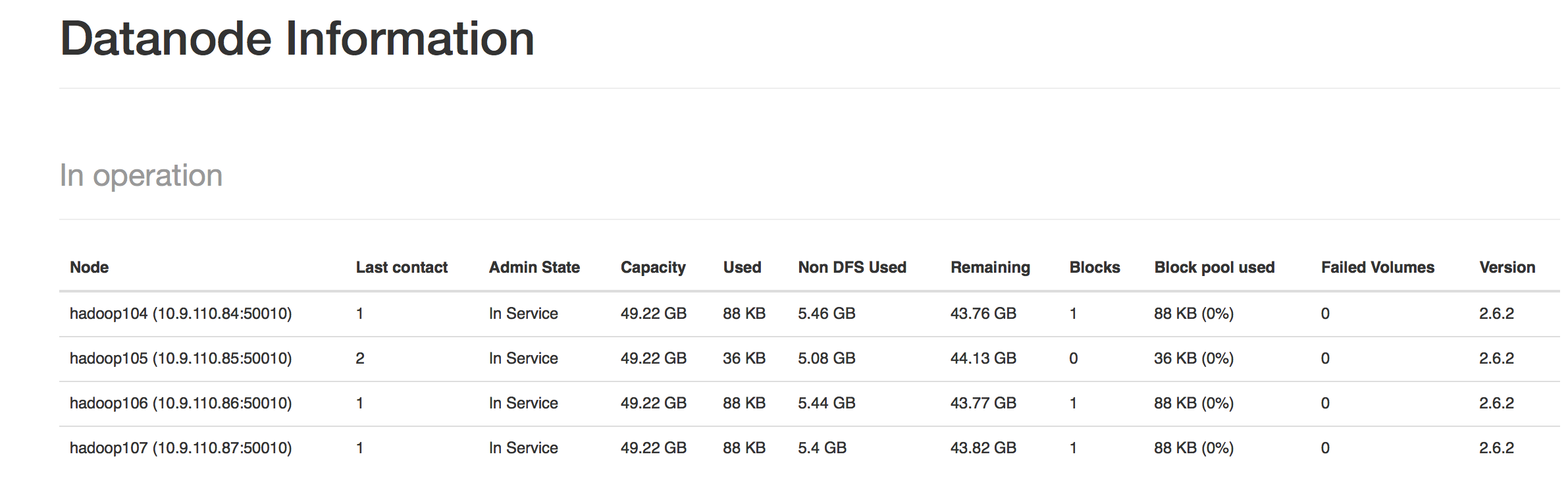
Hadoop2.6.2完全分布式集群HA模式安装配置详解
一、机器配置清单(8节点) hadoop100 节点:NameNode、DFSZKFailoverController(ZKFC) hadoop101 节点:NameNode、DFSZKFailoverController(ZKFC) hadoop102: 节点:ResourceManager hadoop103: 节点:ResourceManager hadoop104: 节点:
ubuntu14.04安装hadoop2.6.03
ubuntu14.04安装hadoop2.6.0, 1.先创建hadoop用户: 查看创建的用户在/home/下面有了文件夹: 2.安装ssh: 3.切换到hadoop用户下,然后启动ssh服务,验证用密码登陆localhost 4.退出,配置ssh无密码登陆localhost 把根目录下的~/.ssh/id_rsa.pub 复制

Hadoop2.6.5单机安装
Hadoop2.6.5单机安装 JDK的安装 配置JDK环境变量 [root@spark1 soft]# vim /etc/profile#JDK环境变量配置#export JAVA_HOME=/application/jdk1.7.0_79export JAVA_HOME=/application/jdk1.8.0_172export JRE_H
Hadoop2.6.5 HA完全分布式搭建
一、准备工作 虚拟机器:vmware workstation 14 Linux系统:Centos 6.4 JDK版本:jdk-8u161-linux-x64.tar.gz Hadoop版本:hadoop-2.6.5.tar.gz 二、基本配置 1、系统安装(略),在/usr/local目录下建立 soft文件夹(存放下载的软件),Java(jdk),hadoop(hadoop文件)

Hadoop2.6.0运行mapreduce之Uber模式验证
前言 在有些情况下,运行于Hadoop集群上的一些mapreduce作业本身的数据量并不是很大,如果此时的任务分片很多,那么为每个map任务或者reduce任务频繁创建Container,势必会增加Hadoop集群的资源消耗,并且因为创建分配Container本身的开销,还会增加这些任务的运行时延。如果能将这些小任务都放入少量的Container中执行,将会解决这些问题。好在Hadoop本身
Centos7 下 spark1.6.1_hadoop2.6 分布式集群环境搭建
摘要 在上一篇博客《Centos7 下 Hadoop 2.6.4 分布式集群环境搭建》 已经详细写了Hadoop 2.6.4 配置过程,下面详细介绍 spark 1.6.1的安装过程。 Scala 安装 下载 ,解压 下载 scala-2.11.8.tgz, 解压到 /root/workspace/software/scala-2.10.4t 目录下 修改环境变量文件 /etc/pro
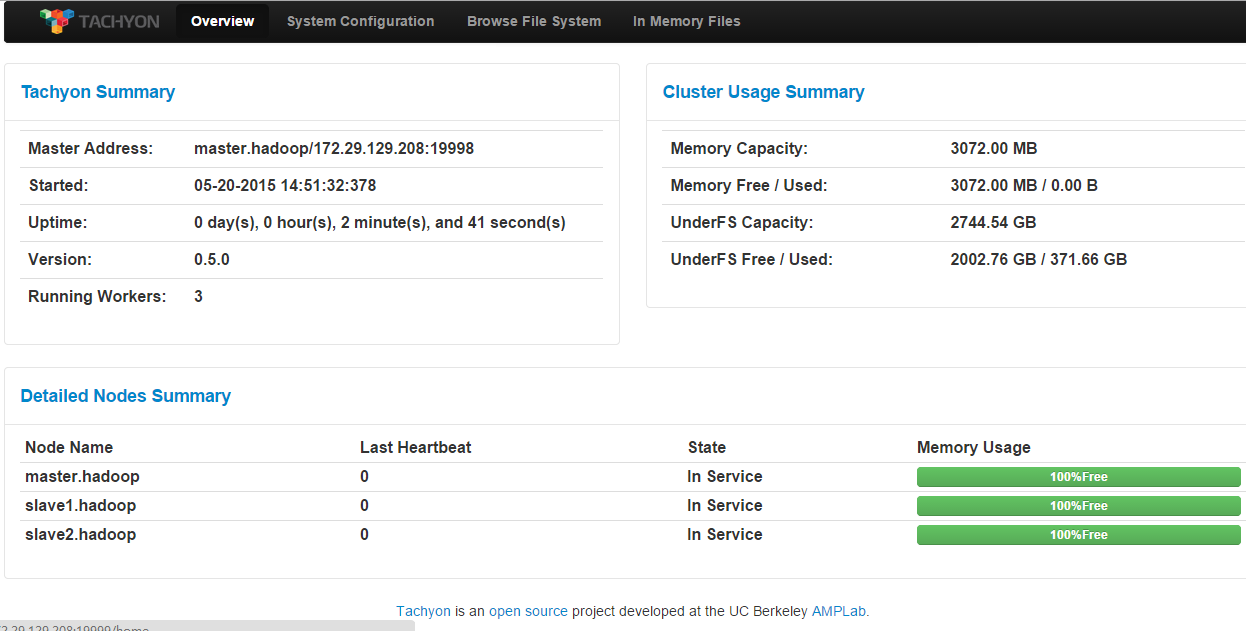
Tachyon0.6.4+Spark1.3+hadoop2.6.0 配置教程详解
前言 本文在安装前已经配置好了spark1.3和hadoop2.6,因项目需求需要搭建tachyon,但是搭建过程中遇到了很多很多很多的问题,写下本文用来记录这一路上所踩过的坑 吐槽一句:tachyon的官方文档不是很完善啊,完全按照他的做肯定成功不了。。。 单节点安装 先说单点,单点搞定,集群就简单了 安装tachyon,官网(https://github.com/amplab
[Hadoop]Hadoop2.6.0的eclipse插件编译
要编译,首先得安装ant。http://ant.apache.org/ 安装ant比较简单,解压缩到/usr/local/ant下,再将/usr/local/ant/bin加入path环境变量即可。 下面是编译Hadoop2.6.0的eclipse插件到过程: 1.Hadoop2x eclipse插件源码在github上,地址为:https://github.com/winghc/had
cloudera CDH5.13.1 Hadoop2.6.0 测试运行wordcount大数据统计作业
cloudea 大数据实验平台安装好了,做点什么呢? 还是从hello world开始吧 1. 查看hadoop版本root@cdh01:~# hadoop version 如果能如上正常显示,说明可以使用hadoop测试程序了 2. 查看有哪些测试程序可用 root@cdh01:~# hadoop jar /opt/cloudera/parcels/CDH/jars/