本文主要是介绍cloudera CDH5.13.1 Hadoop2.6.0 测试运行wordcount大数据统计作业,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
cloudea 大数据实验平台安装好了,做点什么呢? 还是从hello world开始吧
1. 查看hadoop版本
root@cdh01:~# hadoop version
如果能如上正常显示,说明可以使用hadoop测试程序了
2. 查看有哪些测试程序可用
root@cdh01:~# hadoop jar /opt/cloudera/parcels/CDH/jars/hadoop-examples.jar
运行该程序会介绍有哪些hadoop测试程序可以使用
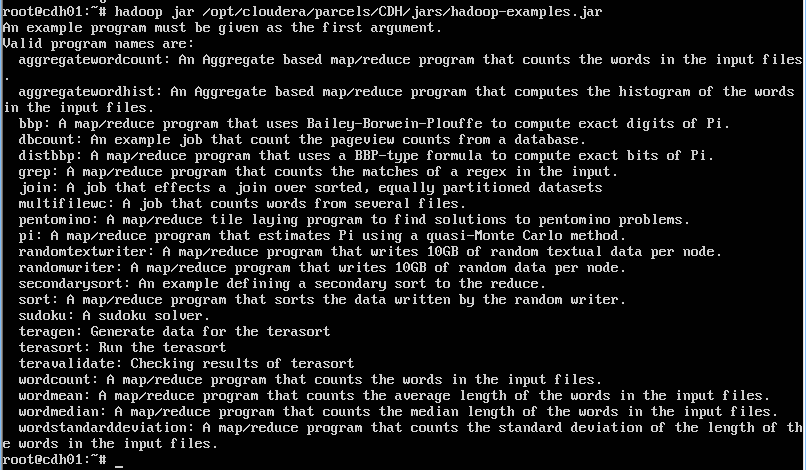
aggregatewordcount 计算输入文件中文字个数的基于聚合的MapReduce程序。
aggregatewordhist 生成输入文件中文字个数的统计图的基于聚合的MapReduce程序。
grep 计算输入文件中匹配正则表达式的文字个数的MapReduce程序。
join 合并排序的平均分割的数据集的作业。
multifilewc 计算几个文件的文字个数的作业。
pentomino 解决五格拼版问题的分块分层的MapReduce程序。
pi 使用蒙地卡罗法计算PI的MapReduce程序。
randomtextwriter 在一个节点上写10G随机文本的MapReduce程序。
randomwriter 在每个节点上写10G随机数据的MapReduce程序。
sleep 在每个Map和Reduce作业中休憩的程序。
sort 排序随机写入器生成的数据的MapReduce程序。
sudoku 一个九宫格游戏的解决方案。
wordcount 在输入文件中统计文字个数的统计器。
3.建立统计案例输入输出目录并上传文件
su hdfs /* 转到gdfs用户身份操作,因为root对hadoop目录目前没有操作权限
hadoop fs -mkdir /input /* 建立输入文件目录
hadoop fs -chmod 777 /input /* 修改目录权限
hadoop fs -mkdir /output /* 建立输出文件目录
hadoop fs -chmod 777 /input /* 修改输出文件目录权限
exit /*退出hdfs用户身份,返回到root用户
hadoop fs -put license.txt /input /把需作单词统计的文件license.txt 上传到hadoop的/input目录
hadoop fs -ls /input /查看是否上传成功
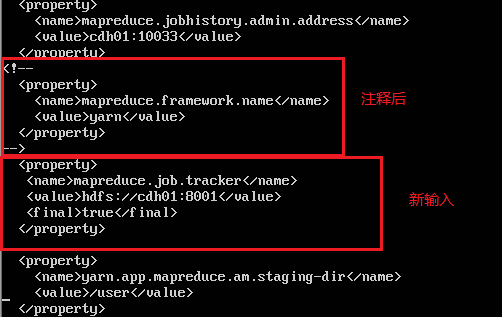
4.修改 /etc/hadoop/conf/mapred-site.xml 文件
按默认的配置运行统计作业时会卡在mapreduce.Job: Running job
在etc/hadoop/conf/mapred-site.xml中,如果配置
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
则使用yarn来进行计算,那么必须启动nodemanager,
如果不使用yarn,进行mapreduce.job.tracker配置也可以用,这样就不需要启动nodemanager:
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://cdh01:8001</value>
<final>true</final>
<property>
root@cdh01:~# vi /etc/hadoop/conf/mapred-site.xml
注释掉原来的配置,使用新输入的配置
修改后如下图
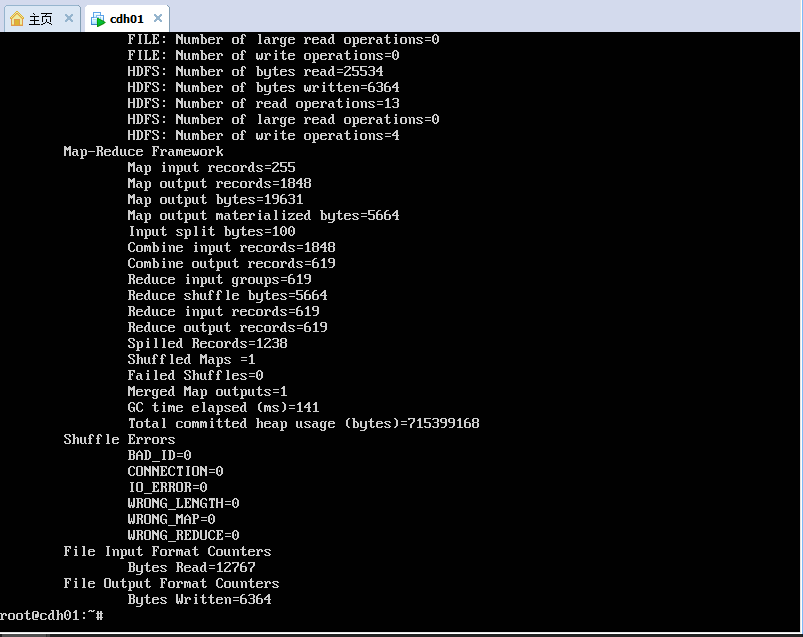
5. 执行统计任务
root@cdh01:~# hadoop jar /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-examples-2.6.0-cdh5.13.1.jar wordcount /input /output/output1
( 也可以使用yarn调度程序:
yarn jar /opt/cloudera/parcels/CDH/jars/hadoop-mapreduce-examples-2.6.0-cdh5.13.1.jar wordcount /input /output/output1 )
如果正常执行,会在屏幕看到执行过程的输出:
6. 查看统计结果
root@cdh01:~# hadoop fs -ls /output/output1/* /* 查看生成的文件名
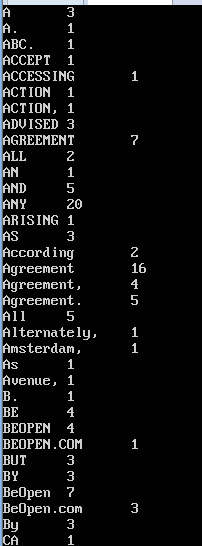
root@cdh01:~# hadoop fs -cat /output/output1/part-r-00000 /* 显示生成的文件内容
root@cdh01:~# hadoop fs -get /output/output1/part-r-00000 /* 复制hdfs文件到本地文件
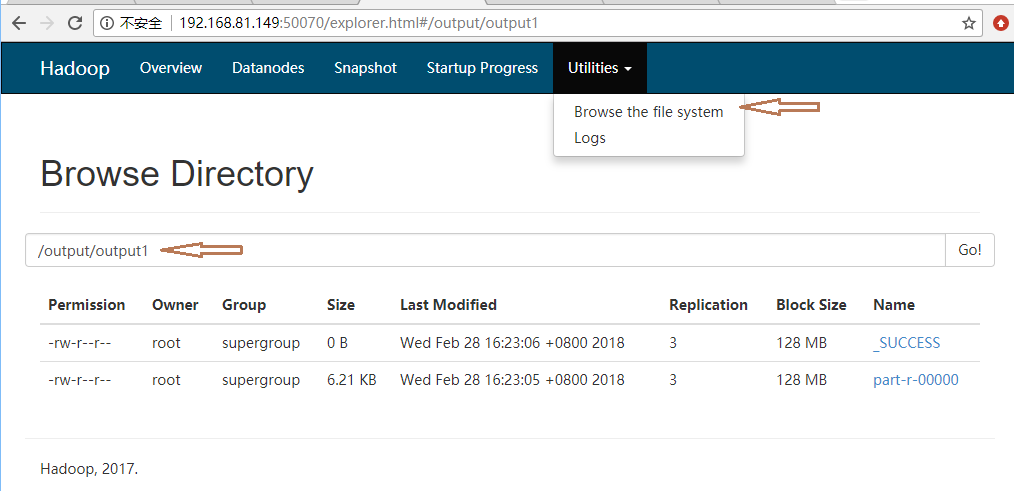
7.也可以通过 浏览器 50070端口查看hadoop hdfs目录及文件
这篇关于cloudera CDH5.13.1 Hadoop2.6.0 测试运行wordcount大数据统计作业的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




