本文主要是介绍【小白学机器学习6】真实值,观测值,拟合值,以及数据的误差的评价:集中趋势,离散度,形状等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1 世界上有哪几种值?只有3种值
1.1 真值/真实值/理想值/主观值(形而上学世界里)
1.2 实际值/现实值/观测值/样本值(看到的/记录下来的)
1.3 拟合值/预测值(算出来的)
2 对数据的各种描述
2.1 维度1:总体和相对指标
2.2 数据分析的角度描述数据
2.2.1 为什么有这个角度?
2.2.2 具体是3个: 数据的集中趋势,数据的离散趋势,数据的形状
2.2.3 分散程度/ 离散程度
2.2.4 离散程度,集中趋势:相对的一对指标
3 数据的集中程度
3.1 数据的集中程度的定义
3.2 数据的集中程度的多种指标
3.3 中位数
3.4 众数
3.5 分位数
3.6 百分位数
4 数据的离散程度
4.1 数据的离散程度
4.2 数据的离散程度的多种指标
4.3 极差(Range)
4.4 平均差
4.4.1 平均差
4.4.2 平均差必须用abs()
5 用来衡量形态的:变异指标
5.1 变异系数
5.2 偏态与峰度测度
5.3 偏态系数
5.4 峰态系数
6 数据标准化
1 世界上有哪几种值?只有3种值
世界上的值,从这个逻辑上,严格的被划分为了这3类:大脑里想象相信的,可以看到+记下来的,自己算的,
- 大脑里想象相信的:真实值
- 可以看到+记下来的:实际值/观测值
- 自己算的:拟合值/预测值
1.1 真值/真实值/理想值/主观值(形而上学世界里)
- 比如丢硬币的任意一边的概率=0.5,这个就是真实值
- 真实,语言意义所指的层面是,理想世界,数学理想世界的那个真实。
- 也是个理想值,主观的
- 整个主观是指不存在现实里,只存在形而上学层次的值。
1.2 实际值/现实值/观测值/样本值(看到的/记录下来的)
- 因为是观察到真实世界里发生了的,从而记录下来的
- 这个才是客观的
- 注意:客观的不是真实的(这个要有一定哲学形而上学的思维)
- 这个客观是指,现实中记录的数。
- 特殊情况:有些观测值具有直观的唯一确定性。此时观测值=真实值
- 比如概率之和,怎么测都一定符合100%?
- 虽然这些情况下,观测值==真实值,但是概念上仍然独立分开,可以认为是刚好相等。
1.3 拟合值/预测值(算出来的)
- 用模型去拟合现有的观测值/样本值,目的是为了产生一些现实中没有的预测值(如时间序列未来的预测值)。
- 但是同时,因为模型拟合很难100%贴合观察数据,对于之前的观测值/样本值,也产生了对应的拟合值。
- 这个也是客观存在得,算出来的值。
- 模型Function(观察值)→ 拟合值+预测值
2 对数据的各种描述
- 对数据可以进行描述,也需要描述
- 一个系列的数据,描述存在多种不同的维度
- 比如从总体还是部分的区别来描述
- 从相对和绝对的角度
- 从数据分析的角度
2.1 维度1:总体和相对指标
- 总量指标, sum,比如总利润等等
- 相对指标, ratio percent,比如同比环比等等
2.2 数据分析的角度描述数据
2.2.1 为什么有这个角度?
假如我们有多组数据,每组数据各有差别,因为我们要描述数据,就必须把下面的这些问题搞清楚:
- 比如
- 有的数据很集中,有的数据很分散
- 有的数据很符合观察数据,有的偏离非常园
- 有的数据呈现圆形,有的呈现正态分布,有的是直线型。。。。
2.2.2 具体是3个: 数据的集中趋势,数据的离散趋势,数据的形状
- 描述数据分布的集中趋势:反映数据向其中心靠拢或聚集程度
- 描述数据分布的离散程度:反映数据远离中心的趋势或程度
- 描述数据分布的形状变化:反应数据分布的形状特征
2.2.3 分散程度/ 离散程度
- 分散程度,离散程度,虽然好像在非数学领域有时候有区分, 据我了解好像没看到数学领域区别,暂时认为是一个东西了。
- 比如经济学领域
- 离散程度:variance/ standard deviation数据之间本身的分散程度大,波动大,不够集中聚拢。
- 分散程度:diversification分散化风险的意思
2.2.4 离散程度,集中趋势:相对的一对指标
- 我认为是相对的一对指标,但略有差别,不能互相替代。
- 数据资料的频数分布有集中趋势和离散趋势两个主要特征。
- 仅仅用集中趋势来描述数据的分布特征是不够的,只有把两者结合起来
- 举例:我们经常会碰到平均数相同的两组数据其离散程度不同。
3 数据的集中程度
3.1 数据的集中程度的定义
- 集中趋势(central tendency):集中趋势反映了一组数据的中心点位置所在及该组数据向中心靠拢或聚集的程度。(描述数据中心)
- 适合查看符合正态分布等数据。
- 如果数据本身比较偏,看集中趋势意义大吗?
3.2 数据的集中程度的多种指标
- 在统计学中,集中趋势或中央趋势,在口语上也经常被称为平均,
- 表示一个机率分布的中间值。
- 最常见的几种集中趋势包括算数平均数、中位数及众数
- 平均值,
- 代数平均值
- 几何平均值
- 加权平均值,如期望就是一种以概率为权重的加权平均数
- 调和平均数
3.3 中位数
- 中位数:数据序列序号中间的那个数
3.4 众数
- 众数: 出现次数最多的数
3.5 分位数
- 分位数(百分位数):经常画箱图
- 2分位数,50%左右,其实就是中位数
- 四分位数,下四分位数25%
- 十分位数:1/10
3.6 百分位数
- 百分位数,尤其是,正态分布的,68%,95%,99% 等3 个区间
- 正态分布的3σ原则为:
- 数值分布在(μ-σ,μ+σ)中的概率为0.6827;
- 数值分布在(μ-2σ,μ+2σ)中的概率为0.9545;
- 数值分布在(μ-3σ,μ+3σ)中的概率为0.9973
4 数据的离散程度
4.1 数据的离散程度
所谓离散程度(Measures of Dispersion),即观测变量各个取值之间的差异程度。它是用以衡量风险大小的指标
- 离散程度反映了各个数据属性值远离其中心值的程度,是数据分布的另一个重要特征。
- 数据的离散程度越大,则集中趋势的测度值对该组数据的代表性就越差,反之亦然。
- 反映各变量值远离其中心值的程度,是数据分布的另一个重要特征
- 从另一个侧面说明 集中趋势测度值的代表程度 (数据距离集中区域分散程度)
- 离散程度越大,均值代表的东西就越少。
- 离散趋势适用情况:均数相差不大,单位相同的资料。
4.2 数据的离散程度的多种指标
- 极差
- 方差
- 标准差
- 四分位数间距。
4.3 极差(Range)
- 极差又称全距, 常规理解:数据宽度?跨度?
- 是观测变量的最大取值与最小取值之间的离差,也就是观测变量的最大观测值与最小观测值之间的区间跨度.极差的计算公式为:
- R= Max(Xi) - Min(Xi)
- 容易受极端值的影响
- 极差是用来衡量数据的最大值与最小值之间的差异程度。
- 极差简单易懂,但只考虑了数据的两个极端值,不能完全反映数据集的分散情况。
4.4 平均差
4.4.1 平均差
- 平均差是总体各单位标志对其算术平均数的离差绝对值的算术平均数.
- 它综合反映了总体各单位标志值的变动程度.
- 平均差越大,则表示标志变动度越大,反之则表示标志变动度越小
- 其实就是, 平均差=Σ|Xi-X均值|/n
4.4.2 平均差必须用abs()
- 必须用 abs() ,否则离散程度的正负差别就会互相抵消,无法反映离散程度!
- 其实就是, 平均差=Σ(Xi-X均值)/n 是错的
5 用来衡量形态的:变异指标
- 偏态和峰态(形状)反映数据总体分布形态的指标
- 变异系数(Coefficient of Variation):
- 变异系数是标准差与均值之比,用来比较不同数据集的离散程度。
- 变异系数可以消除数据单位的影响,更适合用于比较不同尺度或大小的数据集。
5.1 变异系数
变异系数= 标准差除以均值。
离散系数相同时
需要对比两件事物的离散程度,是利用变异系数进行对比。
从公式来看变异系数是以其数学期望为单位去度量随机变量取值波动程度的特征数,标准差的量纲与数学期望的量纲是一致的,所以变异系数是一个无量纲的量,也说明消除了量纲对波动的影响。
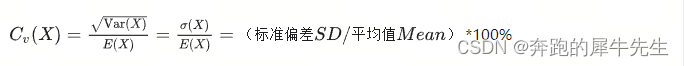
5.2 偏态与峰度测度
- 偏态与峰度测度(偏态及其测度、峰度及其测度)。
- 偏态:反映数据分布不对称的方向和程度
- 峰态:反映数据分布图的尖峭程度或扁平程度
5.3 偏态系数
- 是数据分布偏斜程度的测度
- 偏态系数 = 0时:对称分布
- 偏态系数 > 0时:右偏分布
- 偏态系数 < 0时:左偏分布
5.4 峰态系数
- 是数据分布尖峭程度的测度
- 峰态系数 = 0时:峰度适中
- 峰态系数 > 0时:尖峰分布
- 峰态系数 < 0时:偏平分布


6 数据标准化
定义:数据指数化
- 意义:能够去除数据的单位限制,将其转化为无单位的纯数值,便于不同单位或量级的指标能够进行比较和加权
- 0-1标准化:也叫离差标准化,是对原始数据进行线性变换,是结果落到 [0,1] 区间
- z-score标准化:也叫标准差标准化,经过处理的数据符合标准正态分布,即均值为0,标准差为1
这篇关于【小白学机器学习6】真实值,观测值,拟合值,以及数据的误差的评价:集中趋势,离散度,形状等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






