本文主要是介绍【风格迁移】StyTr2:引入 Transformer 解决 CNN 在长距离依赖性处理不足和细节丢失问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
StyTr2:引入 Transformer 解决 CNN 在长距离依赖性处理不足和细节丢失问题
- 提出背景
- StyTr2 组成
- StyTr2 架构
提出背景
论文:https://arxiv.org/pdf/2105.14576.pdf
代码:https://github.com/diyiiyiii/StyTR-2
问题: 传统的神经风格迁移方法因卷积神经网络(CNN)的局部性,难以提取和维持输入图像的全局信息,导致内容表示偏差。
解法: 提出了一种新的方法StyTr2,这是一种基于变换器的图像风格迁移方法,考虑输入图像的长距离依赖性。
StyTr2 组成
-
两个不同的变换器编码器(双Transformer编码器) - 内容域和风格域的分别编码
之所以使用双变压器编码器,是因为图像的内容和风格信息在本质上是不同的域,需要独立处理以更准确地捕捉各自的特征。
-
采用多层变换器解码器,逐步生成输出序列。
接着使用变压器解码器来逐步生成图像块的输出序列,实现风格迁移。
之所以使用变压器解码器,是因为它可以有效地合并编码阶段得到的内容和风格信息,生成具有所需风格特征的内容图像。
-
内容感知位置编码(CAPE):提出了一种新的位置编码方法,解决现有方法的不足,该方法是尺度不变的,更适合图像风格迁移任务。
位置编码在Transformer模型中用于提供序列中每个元素的位置信息。传统的位置编码方法可能不适合图像生成任务,因为它们没有考虑到图像内容的语义信息。
CAPE通过将位置编码与图像内容的语义特征相结合,实现了对不同尺寸图像的有效处理。
之所以使用内容感知位置编码,是因为它能够根据图像的语义内容动态调整位置信息,使得Transformer模型在处理具有不同尺寸和风格的图像时更加灵活和有效。
内容感知位置编码(CAPE)的示意图:
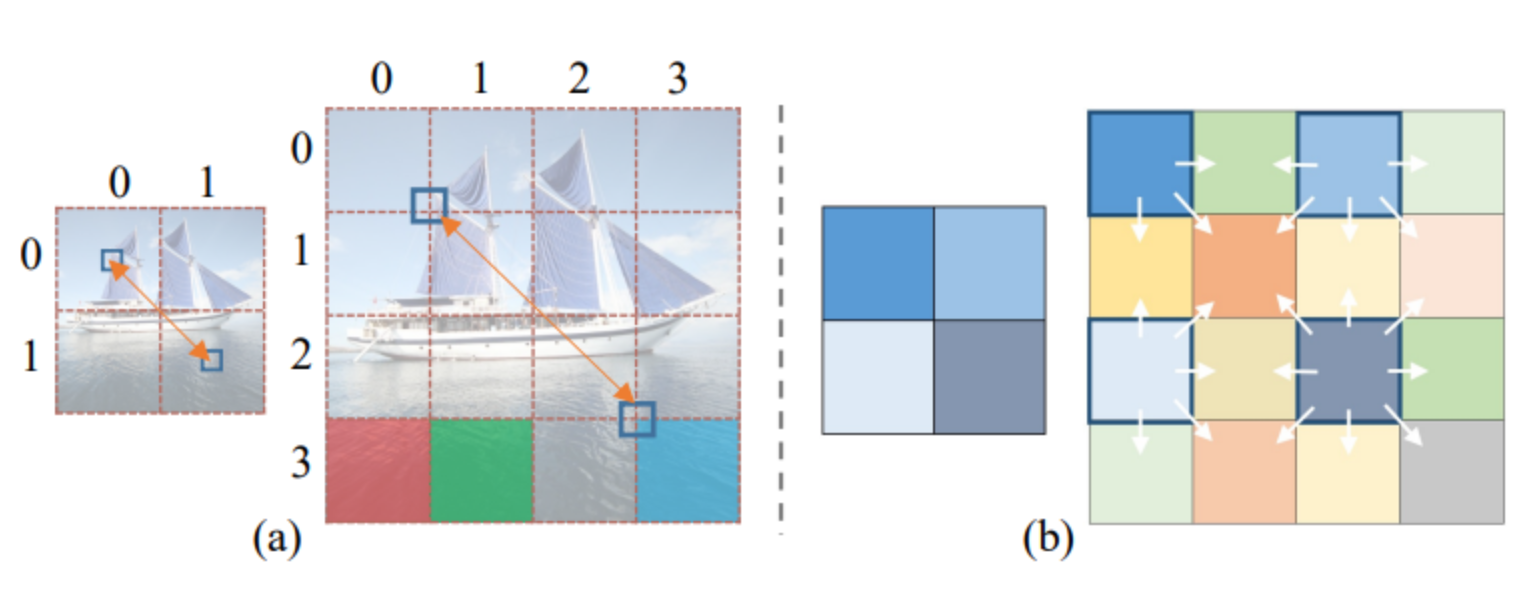
(a):展示了如何将一张图片分割成不同的区块,并对每个区块进行标记。
(b):展示了内容感知位置编码(CAPE)的结构,这是一个考虑图像内容语义的位置编码系统,与传统的Transformer模型中使用的位置编码不同,它基于图像的内容来调整每个区块的位置信息。
StyTr2 架构
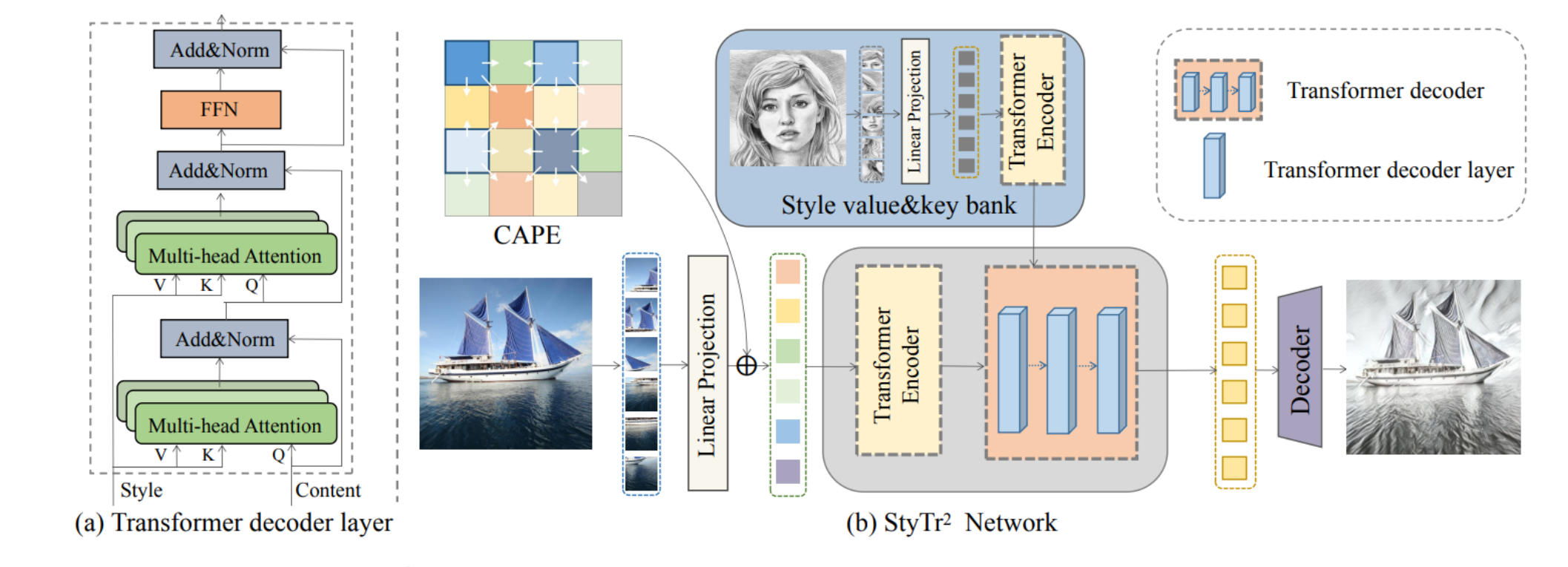
- (a) Transformer解码器层:展示了Transformer解码器的结构,包含多头注意力机制和前馈神经网络(FFN),说明了在风格迁移中,如何处理内容和风格信息。
- (b) StyTr2网络:展示了整个网络的结构,包括内容和风格图像的分割、转换成序列,以及使用Transformer编码器和解码器处理这些序列。最终,使用一个递进式上采样解码器来得到最终的输出图像。
效果对比:

这个表格显示了不同风格迁移方法在内容损失(Lc)和风格损失(Ls)方面的性能比较。
这些损失值用于衡量生成的图像在保留输入内容和风格方面的效果。
表格中,“我们的”结果指的是StyTr2方法的结果,它在保持内容和风格方面取得了最佳效果,其次是其他列出的方法。
这些结果说明StyTr2在风格迁移任务中表现出色,尤其是在保留内容结构和风格特征方面。
这篇关于【风格迁移】StyTr2:引入 Transformer 解决 CNN 在长距离依赖性处理不足和细节丢失问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




