本文主要是介绍【InternLM 实战营笔记】XTuner 大模型单卡低成本微调实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
XTuner概述
一个大语言模型微调工具箱。由 MMRazor 和 MMDeploy 联合开发。
支持的开源LLM (2023.11.01)
InternLM
Llama,Llama2
ChatGLM2,ChatGLM3
Qwen
Baichuan,Baichuan2
Zephyr
特色
傻瓜化: 以 配置文件 的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调。
轻量级: 对于 7B 参数量的LLM,微调所需的最小显存仅为 8GB : 消费级显卡,colab
微调原理
- 因此,你找到了一种叫 LoRA 的方法:只对玩具中的某些零件进行改动,而不是对整个玩具进行全面改动。
- 而 QLoRA 是 LoRA 的一种改进:如果你手里只有一把生锈的螺丝刀,也能改造你的玩具。
实践过程
安装
# 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 2.0.1 的环境:
/root/share/install_conda_env_internlm_base.sh xtuner0.1.9# 激活环境
conda activate xtuner0.1.9
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
mkdir xtuner019 && cd xtuner019# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner# 进入源码目录
cd xtuner# 从源码安装 XTuner
pip install -e '.[all]'
准备在 oasst1 数据集上微调 internlm-7b-chat
# 创建一个微调 oasst1 数据集的工作路径,进入
mkdir ~/ft-oasst1 && cd ~/ft-oasst1
微调
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
# 列出所有内置配置
xtuner list-cfg
拷贝一个配置文件到当前目录:
# xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH}
本例中
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
模型下载
直接复制模型
ln -s /share/temp/model_repos/internlm-chat-7b ~/ft-oasst1/
数据集下载
cd ~/ft-oasst1
# ...-guanaco 后面有个空格和英文句号啊
cp -r /root/share/temp/datasets/openassistant-guanaco .
修改配置文件
cd ~/ft-oasst1
vim internlm_chat_7b_qlora_oasst1_e3_copy.py
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'# 修改训练数据集为本地路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = './openassistant-guanaco'
开始微调
# 单卡
## 用刚才改好的config文件训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py# 多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py# 若要开启 deepspeed 加速,增加 --deepspeed deepspeed_zero2 即可
将得到的 PTH 模型转换为 HuggingFace 模型,即:生成 Adapter 文件夹
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER=GNU
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf
部署与测试
将 HuggingFace adapter 合并到大语言模型
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
与合并后的模型对话
xtuner chat ./merged --prompt-template internlm_chat
修改 cli_demo.py 中的模型路径
- model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b"
+ model_name_or_path = "merged"
运行
python ./cli_demo.py
自定义微调
基于 InternLM-chat-7B 模型,用 MedQA 数据集进行微调,将其往医学问答领域对齐。
数据集
https://github.com/abachaa/Medication_QA_MedInfo2019
准备工作
将数据转为 XTuner 的数据格式(jsonL
目标格式:(.jsonL)
[{"conversation":[{"system": "xxx","input": "xxx","output": "xxx"}]
},
{"conversation":[{"system": "xxx","input": "xxx","output": "xxx"}]
}]
通过 python 脚本:将 .xlsx 中的 问题 和 回答 两列 提取出来,再放入 .jsonL 文件的每个 conversation 的 input 和 output 中。
这一步的 python 脚本可以请 ChatGPT 来完成。
Write a python file for me. using openpyxl. input file name is MedQA2019.xlsx
Step1: The input file is .xlsx. Exact the column A and column D in the sheet named "DrugQA" .
Step2: Put each value in column A into each "input" of each "conversation". Put each value in column D into each "output" of each "conversation".
Step3: The output file is .jsonL. It looks like:
[{"conversation":[{"system": "xxx","input": "xxx","output": "xxx"}]
},
{"conversation":[{"system": "xxx","input": "xxx","output": "xxx"}]
}]
Step4: All "system" value changes to "You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions."
生成的代码如下:
import openpyxl
import jsondef process_excel_to_json(input_file, output_file):# Load the workbookwb = openpyxl.load_workbook(input_file)# Select the "DrugQA" sheetsheet = wb["DrugQA"]# Initialize the output data structureoutput_data = []# Iterate through each row in column A and Dfor row in sheet.iter_rows(min_row=2, max_col=4, values_only=True):system_value = "You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions."# Create the conversation dictionaryconversation = {"system": system_value,"input": row[0],"output": row[3]}# Append the conversation to the output dataoutput_data.append({"conversation": [conversation]})# Write the output data to a JSON filewith open(output_file, 'w', encoding='utf-8') as json_file:json.dump(output_data, json_file, indent=4)print(f"Conversion complete. Output written to {output_file}")# Replace 'MedQA2019.xlsx' and 'output.jsonl' with your actual input and output file names
process_excel_to_json('MedQA2019.xlsx', 'output.jsonl')
执行脚本:
python xlsx2jsonl.py
划分训练集和测试集
my .jsonL file looks like:
[{"conversation":[{"system": "xxx","input": "xxx","output": "xxx"}]
},
{"conversation":[{"system": "xxx","input": "xxx","output": "xxx"}]
}]
Step1, read the .jsonL file.
Step2, count the amount of the "conversation" elements.
Step3, randomly split all "conversation" elements by 7:3. Targeted structure is same as the input.
Step4, save the 7/10 part as train.jsonl. save the 3/10 part as test.jsonl
代码如下:
import json
import randomdef split_conversations(input_file, train_output_file, test_output_file):# Read the input JSONL filewith open(input_file, 'r', encoding='utf-8') as jsonl_file:data = json.load(jsonl_file)# Count the number of conversation elementsnum_conversations = len(data)# Shuffle the data randomlyrandom.shuffle(data)random.shuffle(data)random.shuffle(data)# Calculate the split points for train and testsplit_point = int(num_conversations * 0.7)# Split the data into train and testtrain_data = data[:split_point]test_data = data[split_point:]# Write the train data to a new JSONL filewith open(train_output_file, 'w', encoding='utf-8') as train_jsonl_file:json.dump(train_data, train_jsonl_file, indent=4)# Write the test data to a new JSONL filewith open(test_output_file, 'w', encoding='utf-8') as test_jsonl_file:json.dump(test_data, test_jsonl_file, indent=4)print(f"Split complete. Train data written to {train_output_file}, Test data written to {test_output_file}")# Replace 'input.jsonl', 'train.jsonl', and 'test.jsonl' with your actual file names
split_conversations('MedQA2019-structured.jsonl', 'MedQA2019-structured-train.jsonl', 'MedQA2019-structured-test.jsonl')
开始自定义微调
此时,我们重新建一个文件夹来玩“微调自定义数据集”
mkdir ~/ft-medqa && cd ~/ft-medqa
把前面下载好的internlm-chat-7b模型文件夹拷贝过来。
cp -r ~/ft-oasst1/internlm-chat-7b .
别忘了把自定义数据集,即几个 .jsonL,也传到服务器上。
git clone https://github.com/InternLM/tutorial
cp ~/tutorial/xtuner/MedQA2019-structured-train.jsonl .
准备配置文件
# 复制配置文件到当前目录
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
# 改个文件名
mv internlm_chat_7b_qlora_oasst1_e3_copy.py internlm_chat_7b_qlora_medqa2019_e3.py# 修改配置文件内容
vim internlm_chat_7b_qlora_medqa2019_e3.py
减号代表要删除的行,加号代表要增加的行。
# 修改import部分
- from xtuner.dataset.map_fns import oasst1_map_fn, template_map_fn_factory
+ from xtuner.dataset.map_fns import template_map_fn_factory# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'# 修改训练数据为 MedQA2019-structured-train.jsonl 路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = 'MedQA2019-structured-train.jsonl'# 修改 train_dataset 对象
train_dataset = dict(type=process_hf_dataset,
- dataset=dict(type=load_dataset, path=data_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),tokenizer=tokenizer,max_length=max_length,
- dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=None,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length)
启动
xtuner train internlm_chat_7b_qlora_medqa2019_e3.py --deepspeed deepspeed_zero2
用 MS-Agent 数据集 赋予 LLM 以 Agent 能力
MSAgent 数据集每条样本包含一个对话列表(conversations),其里面包含了 system、user、assistant 三种字段。其中:
-
system: 表示给模型前置的人设输入,其中有告诉模型如何调用插件以及生成请求
-
user: 表示用户的输入 prompt,分为两种,通用生成的prompt和调用插件需求的 prompt
-
assistant: 为模型的回复。其中会包括插件调用代码和执行代码,调用代码是要 LLM 生成的,而执行代码是调用服务来生成结果的
微调
xtuner 是从国内的 ModelScope 平台下载 MS-Agent 数据集,因此不用提前手动下载数据集文件。
# 准备工作
mkdir ~/ft-msagent && cd ~/ft-msagent
cp -r ~/ft-oasst1/internlm-chat-7b .# 查看配置文件
xtuner list-cfg | grep msagent# 复制配置文件到当前目录
xtuner copy-cfg internlm_7b_qlora_msagent_react_e3_gpu8 .# 修改配置文件中的模型为本地路径
vim ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
开始微调
xtuner train ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py --deepspeed deepspeed_zero2
使用
由于 msagent 的训练非常费时,大家如果想尽快把这个教程跟完,可以直接从 modelScope 拉取咱们已经微调好了的 Adapter。如下演示。
下载 Adapter
cd ~/ft-msagent
apt install git git-lfs
git lfs install
git lfs clone https://www.modelscope.cn/xtuner/internlm-7b-qlora-msagent-react.git
OK,现在目录应该长这样:
internlm_7b_qlora_msagent_react_e3_gpu8_copy.py
internlm-7b-qlora-msagent-react
internlm-chat-7b
work_dir(可有可无)`
有了这个在 msagent 上训练得到的Adapter,模型现在已经有 agent 能力了!就可以加 --lagent 以调用来自 lagent 的代理功能了!
添加 serper 环境变量
开始 chat 之前,还要加个 serper 的环境变量:
去 serper.dev 免费注册一个账号,生成自己的 api key。这个东西是用来给 lagent 去获取 google 搜索的结果的。等于是 serper.dev 帮你去访问 google,而不是从你自己本地去访问 google 了。
添加 serper api key 到环境变量:
export SERPER_API_KEY=你的API_KEY
启动
xtuner chat ./internlm-chat-7b --adapter internlm-7b-qlora-msagent-react --lagent
报错处理
xtuner chat 增加 --lagent 参数后,报错
TypeError: transfomers.modelsauto.auto factory. BaseAutoModelClass.from pretrained() got multiple values for keyword argument "trust remote code"
注释掉已安装包中的代码:
vim /root/xtuner019/xtuner/xtuner/tools/chat.py
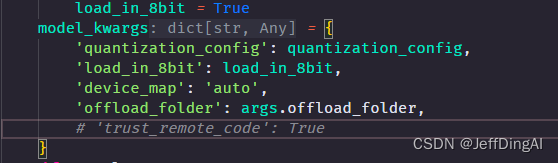
作业
conda create --name personal_assistant --clone=/root/share/conda_envs/internlm-base
# 如果在其他平台:
# conda create --name personal_assistant python=3.10 -y# 激活环境
conda activate personal_assistant
# 进入家目录 (~的意思是 “当前用户的home路径”)
cd ~
# 创建版本文件夹并进入,以跟随本教程
# personal_assistant用于存放本教程所使用的东西
mkdir /root/personal_assistant && cd /root/personal_assistant
mkdir /root/personal_assistant/xtuner019 && cd /root/personal_assistant/xtuner019# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner# 进入源码目录
cd xtuner# 从源码安装 XTuner
pip install -e '.[all]'
数据准备
mkdir -p /root/personal_assistant/data && cd /root/personal_assistant/data
在data目录下创建一个json文件personal_assistant.json作为本次微调所使用的数据集。json中内容可参考下方(复制粘贴n次做数据增广,数据量小无法有效微调,下面仅用于展示格式,下面也有生成脚本)
其中conversation表示一次对话的内容,input为输入,即用户会问的问题,output为输出,即想要模型回答的答案。
以下是一个python脚本,用于生成数据集。在data目录下新建一个generate_data.py文件,将以下代码复制进去,然后运行该脚本即可生成数据集。
import json# 输入你的名字
name = 'Shengshenlan'
# 重复次数
n = 10000data = [{"conversation": [{"input": "请做一下自我介绍","output": "我是{}的小助手,内在是上海AI实验室书生·浦语的7B大模型哦".format(name)}]}
]for i in range(n):data.append(data[0])with open('personal_assistant.json', 'w', encoding='utf-8') as f:json.dump(data, f, ensure_ascii=False, indent=4)
配置准备
mkdir -p /root/personal_assistant/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/personal_assistant/model/Shanghai_AI_Laboratory#创建用于存放配置的文件夹config并进入
mkdir /root/personal_assistant/config && cd /root/personal_assistant/configxtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
修改拷贝后的文件internlm_chat_7b_qlora_oasst1_e3_copy.py
# Copyright (c) OpenMMLab. All rights reserved.
import torch
from bitsandbytes.optim import PagedAdamW32bit
from datasets import load_dataset
from mmengine.dataset import DefaultSampler
from mmengine.hooks import (CheckpointHook, DistSamplerSeedHook, IterTimerHook,LoggerHook, ParamSchedulerHook)
from mmengine.optim import AmpOptimWrapper, CosineAnnealingLR
from peft import LoraConfig
from transformers import (AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfig)from xtuner.dataset import process_hf_dataset
from xtuner.dataset.collate_fns import default_collate_fn
from xtuner.dataset.map_fns import oasst1_map_fn, template_map_fn_factory
from xtuner.engine import DatasetInfoHook, EvaluateChatHook
from xtuner.model import SupervisedFinetune
from xtuner.utils import PROMPT_TEMPLATE#######################################################################
# PART 1 Settings #
#######################################################################
# Model
pretrained_model_name_or_path = '/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b'# Data
data_path = '/root/personal_assistant/data/personal_assistant.json'
prompt_template = PROMPT_TEMPLATE.internlm_chat
max_length = 512
pack_to_max_length = True# Scheduler & Optimizer
batch_size = 2 # per_device
accumulative_counts = 16
dataloader_num_workers = 0
max_epochs = 3
optim_type = PagedAdamW32bit
lr = 2e-4
betas = (0.9, 0.999)
weight_decay = 0
max_norm = 1 # grad clip# Evaluate the generation performance during the training
evaluation_freq = 90
SYSTEM = ''
evaluation_inputs = [ '请介绍一下你自己', '请做一下自我介绍' ]#######################################################################
# PART 2 Model & Tokenizer #
#######################################################################
tokenizer = dict(type=AutoTokenizer.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,padding_side='right')model = dict(type=SupervisedFinetune,llm=dict(type=AutoModelForCausalLM.from_pretrained,pretrained_model_name_or_path=pretrained_model_name_or_path,trust_remote_code=True,torch_dtype=torch.float16,quantization_config=dict(type=BitsAndBytesConfig,load_in_4bit=True,load_in_8bit=False,llm_int8_threshold=6.0,llm_int8_has_fp16_weight=False,bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=True,bnb_4bit_quant_type='nf4')),lora=dict(type=LoraConfig,r=64,lora_alpha=16,lora_dropout=0.1,bias='none',task_type='CAUSAL_LM'))#######################################################################
# PART 3 Dataset & Dataloader #
#######################################################################
train_dataset = dict(type=process_hf_dataset,dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),tokenizer=tokenizer,max_length=max_length,dataset_map_fn=None,template_map_fn=dict(type=template_map_fn_factory, template=prompt_template),remove_unused_columns=True,shuffle_before_pack=True,pack_to_max_length=pack_to_max_length)train_dataloader = dict(batch_size=batch_size,num_workers=dataloader_num_workers,dataset=train_dataset,sampler=dict(type=DefaultSampler, shuffle=True),collate_fn=dict(type=default_collate_fn))#######################################################################
# PART 4 Scheduler & Optimizer #
#######################################################################
# optimizer
optim_wrapper = dict(type=AmpOptimWrapper,optimizer=dict(type=optim_type, lr=lr, betas=betas, weight_decay=weight_decay),clip_grad=dict(max_norm=max_norm, error_if_nonfinite=False),accumulative_counts=accumulative_counts,loss_scale='dynamic',dtype='float16')# learning policy
# More information: https://github.com/open-mmlab/mmengine/blob/main/docs/en/tutorials/param_scheduler.md # noqa: E501
param_scheduler = dict(type=CosineAnnealingLR,eta_min=0.0,by_epoch=True,T_max=max_epochs,convert_to_iter_based=True)# train, val, test setting
train_cfg = dict(by_epoch=True, max_epochs=max_epochs, val_interval=1)#######################################################################
# PART 5 Runtime #
#######################################################################
# Log the dialogue periodically during the training process, optional
custom_hooks = [dict(type=DatasetInfoHook, tokenizer=tokenizer),dict(type=EvaluateChatHook,tokenizer=tokenizer,every_n_iters=evaluation_freq,evaluation_inputs=evaluation_inputs,system=SYSTEM,prompt_template=prompt_template)
]# configure default hooks
default_hooks = dict(# record the time of every iteration.timer=dict(type=IterTimerHook),# print log every 100 iterations.logger=dict(type=LoggerHook, interval=10),# enable the parameter scheduler.param_scheduler=dict(type=ParamSchedulerHook),# save checkpoint per epoch.checkpoint=dict(type=CheckpointHook, interval=1),# set sampler seed in distributed evrionment.sampler_seed=dict(type=DistSamplerSeedHook),
)# configure environment
env_cfg = dict(# whether to enable cudnn benchmarkcudnn_benchmark=False,# set multi process parametersmp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),# set distributed parametersdist_cfg=dict(backend='nccl'),
)# set visualizer
visualizer = None# set log level
log_level = 'INFO'# load from which checkpoint
load_from = None# whether to resume training from the loaded checkpoint
resume = False# Defaults to use random seed and disable `deterministic`
randomness = dict(seed=None, deterministic=False)
微调启动
xtuner train /root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
微调后参数转换/合并
# 创建用于存放Hugging Face格式参数的hf文件夹
mkdir /root/personal_assistant/config/work_dirs/hfexport MKL_SERVICE_FORCE_INTEL=1# 配置文件存放的位置
export CONFIG_NAME_OR_PATH=/root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py# 模型训练后得到的pth格式参数存放的位置
export PTH=/root/personal_assistant/config/work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_3.pth# pth文件转换为Hugging Face格式后参数存放的位置
export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf# 执行参数转换
xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH
网页DEMO
安装依赖
pip install streamlit==1.24.0
下载项目
# 创建code文件夹用于存放InternLM项目代码
mkdir /root/personal_assistant/code && cd /root/personal_assistant/code
git clone https://github.com/InternLM/InternLM.git
将 /root/code/InternLM/web_demo.py 中 29 行和 33 行的模型路径更换为Merge后存放参数的路径 /root/personal_assistant/config/work_dirs/hf_merge
启动
streamlit run /root/personal_assistant/code/InternLM/web_demo.py --server.address 127.0.0.1 --server.port 6006
运行效果
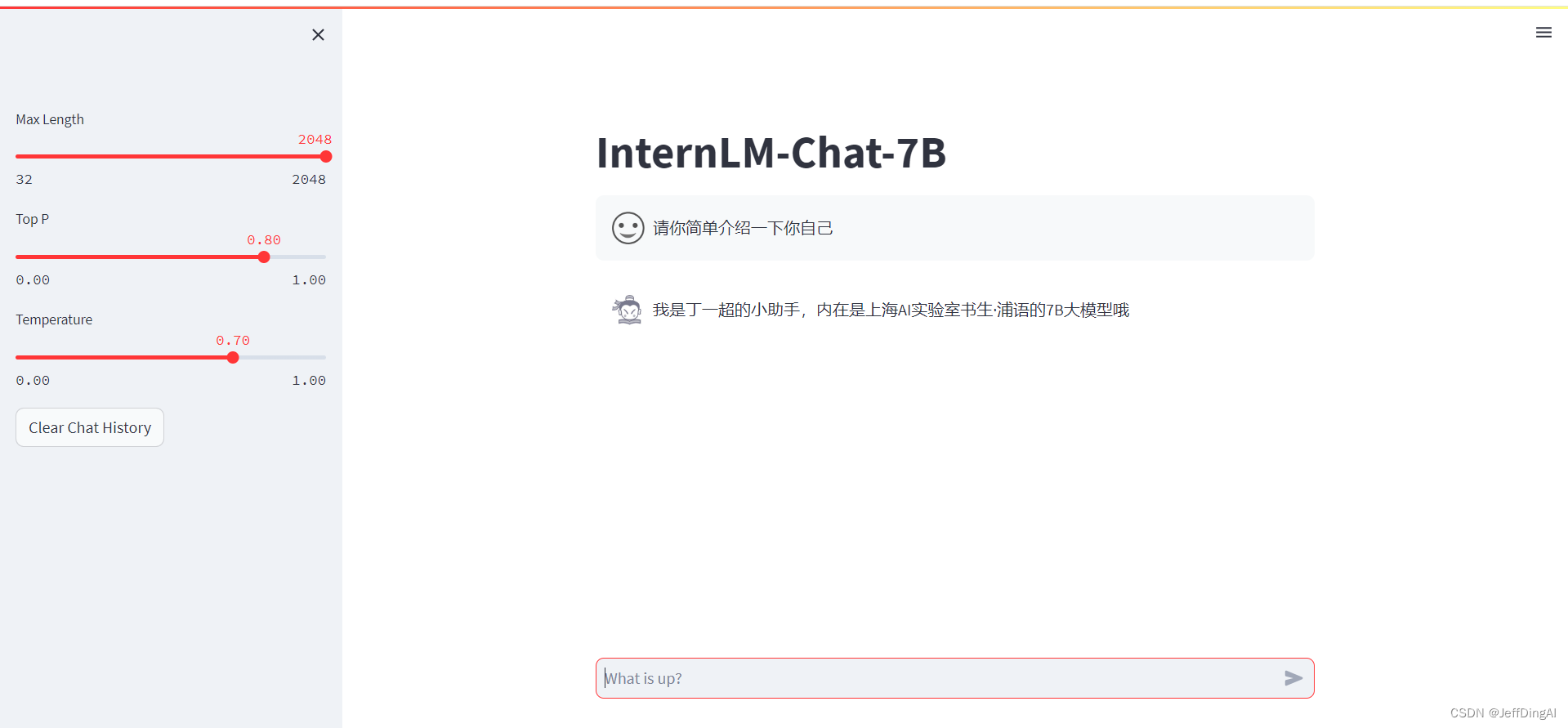
这篇关于【InternLM 实战营笔记】XTuner 大模型单卡低成本微调实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





