单卡专题

开源模型应用落地-qwen2-7b-instruct-LoRA微调合并-ms-swift-单机单卡-V100(十三)
一、前言 本篇文章将使用ms-swift去合并微调后的模型权重,通过阅读本文,您将能够更好地掌握这些关键技术,理解其中的关键技术要点,并应用于自己的项目中。 二、术语介绍 2.1. LoRA微调 LoRA (Low-Rank Adaptation) 用于微调大型语言模型 (LLM)。 是一种有效的自适应策略,它不会引入额外的推理延迟,并在保持模型质量的同时显着减少下游

开源模型应用落地-qwen2-7b-instruct-LoRA微调模型合并-Axolotl-单机单卡-V100(十)
一、前言 本篇文章将使用Axolotl去合并微调后的模型权重,通过阅读本文,您将能够更好地掌握这些关键技术,理解其中的关键技术要点,并应用于自己的项目中。 二、术语介绍 2.1. LoRA微调 LoRA (Low-Rank Adaptation) 用于微调大型语言模型 (LLM)。 是一种有效的自适应策略,它不会引入额外的推理延迟,并在保持模型质量的同时显着减少下游任

pytorch使用DataParallel并行化保存和加载模型(单卡、多卡各种情况讲解)
话不多说,直接进入正题。 !!!不过要注意一点,本文保存模型采用的都是只保存模型参数的情况,而不是保存整个模型的情况。一定要看清楚再用啊! 1 单卡训练,单卡加载 #保存模型torch.save(model.state_dict(),'model.pt')#加载模型model=MyModel()#MyModel()是你定义的创建模型的函数,就是先初始化得到一个模型实例,之后再将模型参数加
[ deepSpeed ] 单机单卡本地运行 Docker运行
本文笔者基于官方示例DeepSpeedExamples/training/cifar/cifar10_deepspeed.py进行本地构建和Docker构建运行示例(下列代码中均是踩坑后可执行的代码,尤其是Docker部分), 全部code可以看笔者的github: cifiar10_ds_train.py 1 环境配置 1.1 cuda 相关配置 wget https://develope
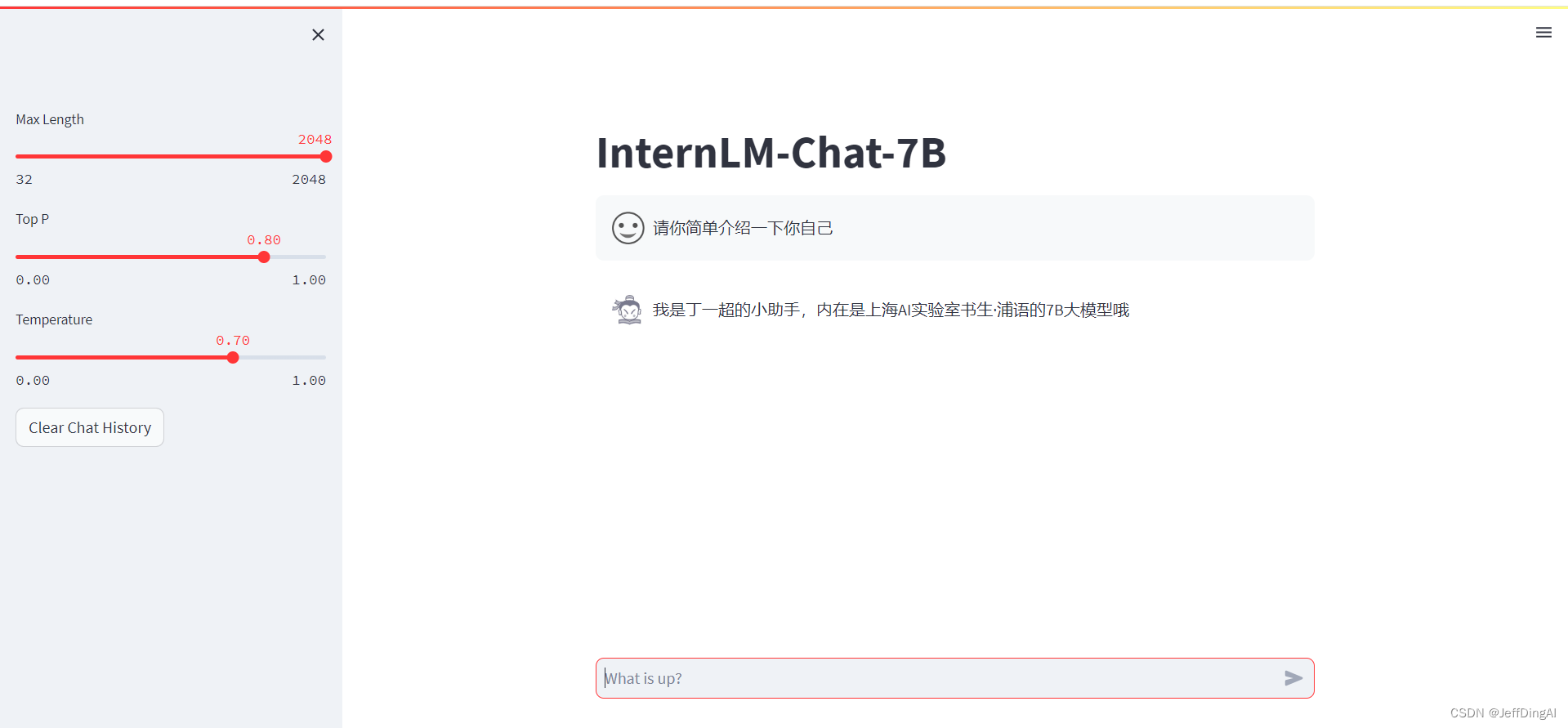
【InternLM 实战营笔记】XTuner 大模型单卡低成本微调实战
XTuner概述 一个大语言模型微调工具箱。由 MMRazor 和 MMDeploy 联合开发。 支持的开源LLM (2023.11.01) InternLM Llama,Llama2 ChatGLM2,ChatGLM3 Qwen Baichuan,Baichuan2 Zephyr 特色 傻瓜化: 以 配置文件 的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调。 轻量级:
XTuner 大模型单卡低成本微调实战
安装xtuner # 如果你是在 InternStudio 平台,则从本地 clone 一个已有 pytorch 2.0.1 的环境:/root/share/install_conda_env_internlm_base.sh xtuner0.1.9# 如果你是在其他平台:conda create --name xtuner0.1.9 python=3.10 -y# 激活环境conda
大模型实战营Day4 XTuner 大模型单卡低成本微调实战 作业
按照文档操作: 单卡跑完训练: 按照要求更改微调的数据: 完成微调数据的脚本生成: 修改配置文件: 替换好文件后启动: 启动后终端如图: 用于微调的一些数据显示: 训练时间,loss: 可见模型是经过微调数据反复纠正,慢慢被引导向微调设计者所想的方向: 3个epoch完: 参数转换、合并: 更改路径为现存的参数: 用streamlit进行启动模型,
第四节课 XTuner 大模型单卡低成本微调实战 作业
文章目录 笔记作业 笔记 XTuner 大模型单卡低成本微调原理:https://blog.csdn.net/m0_49289284/article/details/135532140XTuner 大模型单卡低成本微调实战:https://blog.csdn.net/m0_49289284/article/details/135534817 作业 基础作业:使用 XTuner
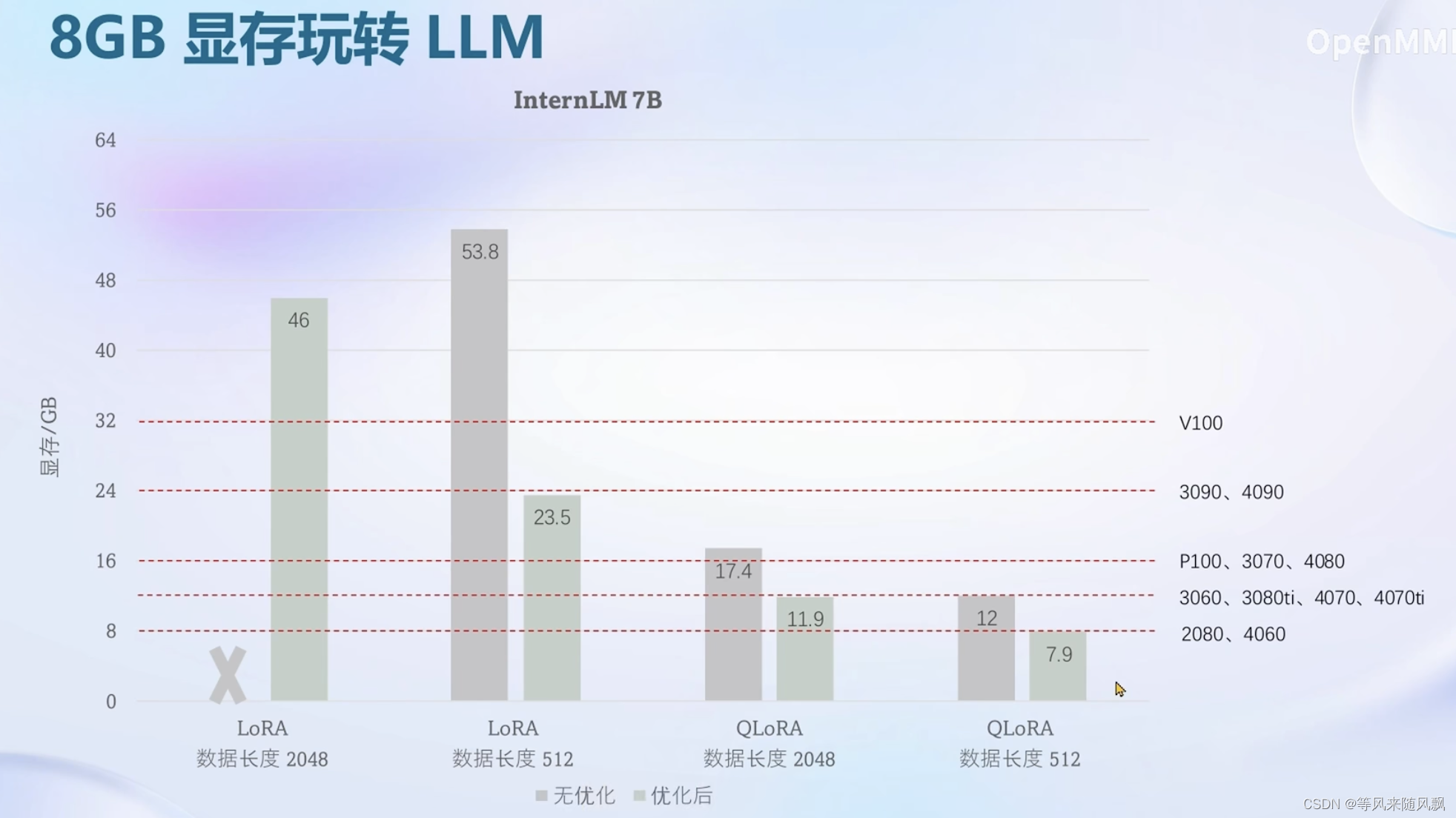
大模型实战笔记04——XTuner 大模型单卡低成本微调实战
大模型实战笔记04——XTuner 大模型单卡低成本微调实战 1、Finetune简介 2、XTuner 3、8GB显存玩转LLM 4、动手实战环节 注: 笔记内容均为截图 课程视频地址:https://www.bilibili.com/video/BV1yK4y1B75J/?spm_id_from=333.788&vd_source=2
Pytorch采坑记录:DDP 损失和精度比 DP 差,多卡GPU比单卡GPU效果差
结论:调大学习率或者调小多卡GPU的batch_size 转换DDP模型后模型的整体学习率和batch_size都要变。 当前配置::1GPU:学习率=0.1,batch_size=64 如果8GPU还按之前1GPU配置:8GPU:学习率=0.1,batch_size=64 那么此时对于8GPU而言,效果几乎等于::1GPU:学习率=0.1,batch_size=64 * 8=512 这种

QLoRA实战 | 使用单卡高效微调bloom-7b1,效果惊艳
来自:YeungNLP 进NLP群—>加入NLP交流群 在文章Firefly(流萤): 中文对话式大语言模型、中文对话式大语言模型Firefly-2b6开源,使用210万训练数据中,我们介绍了关于Firefly(流萤)模型的工作。对大模型进行全量参数微调需要大量GPU资源,所以我们通过对Bloom进行词表裁剪,在4*32G的显卡上,勉强训练起了2.6B的firefly模型。 在本文中,我们将介绍

pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed模型训练
pytorch单精度、半精度、混合精度、单卡、多卡(DP / DDP)、FSDP、DeepSpeed模型训练、模型保存、模型推理、onnx导出、onnxruntime推理等示例代码,并对比不同方法的训练速度以及GPU内存的使用。 代码:pytorch_model_train FairScale(你真的需要FSDP、DeepSpeed吗?) 在了解各种训练方式之前,先来看一下 FairSc

PyTorch单卡/多卡下模型保存/加载
由于训练和测试所使用的硬件条件不同,在模型的保存和加载过程中可能因为单GPU和多GPU环境的不同带来模型不匹配等问题。这里对PyTorch框架下单卡/多卡下模型的保存和加载问题进行排列组合(=4),样例模型是torchvision中预训练模型resnet152,不尽之处欢迎大家补充。 1 数据格式与存储内容 1.1 模型存储格式 PyTorch存储模型主要采用pkl,pt,pth三种格
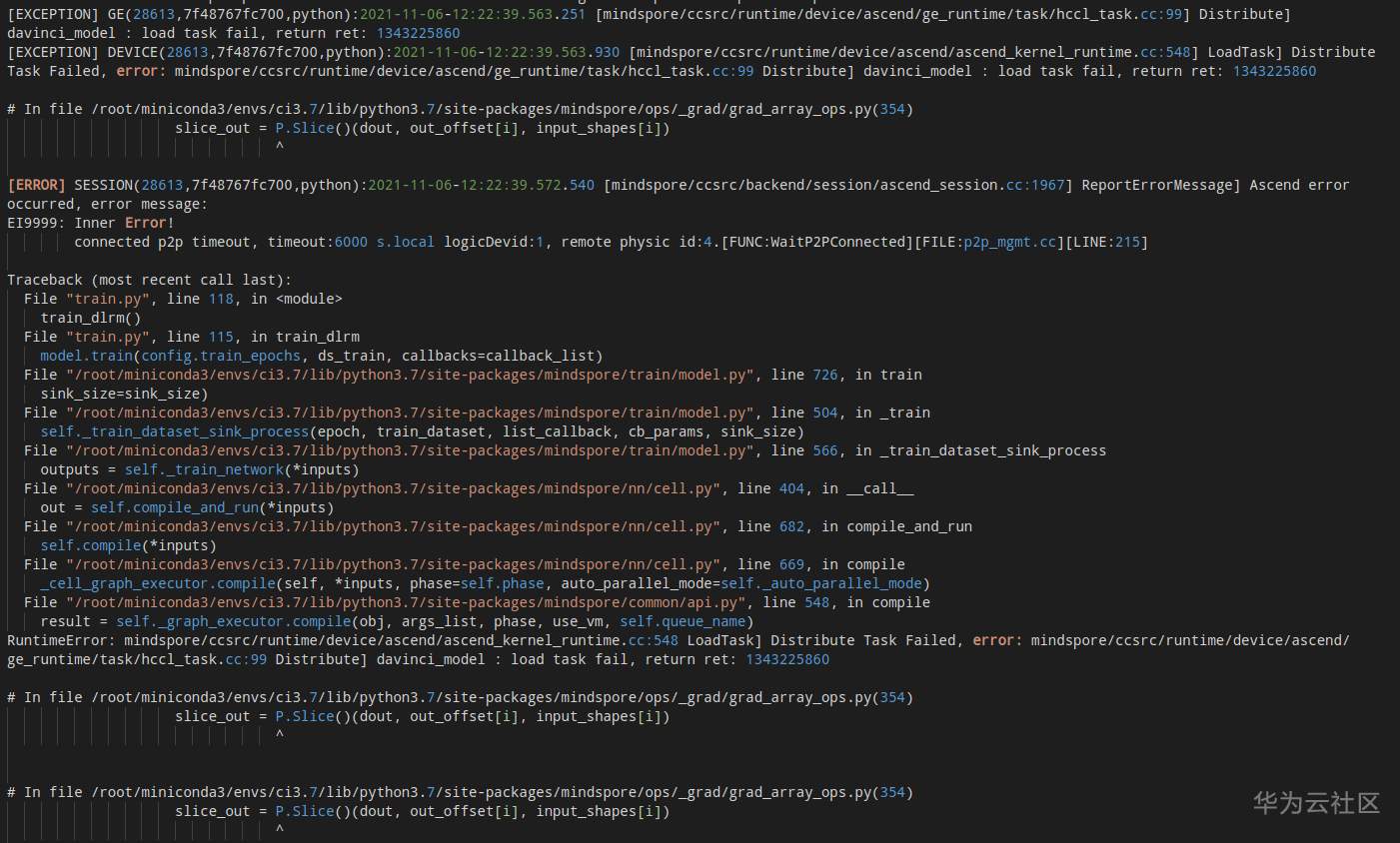
mindspore-NPU单卡可以执行,多卡会报错
图模式,数据并行 单卡可以正常执行训练和推断,多卡训练会报错,hccl 的 json 文件和多卡的脚本都按照官方文档构建的。 建立 hccl 的 json 文件的问题,我在 8p 的机器上只希望使用 4 张卡,在构建 json 文件时就要指出,不能构建 8 卡的 json 文件,但是使用四张卡。

Pytorch(1.2.0+):多机单卡并行实操(MNIST识别)
背景 简单实际操作一下用Pytorch(1.2.0+)进行多机单卡并行训练,可能就不太关注原理了。 参考 https://blog.csdn.net/u010557442/article/details/79431520 https://zhuanlan.zhihu.com/p/116482019 https://blog.csdn.net/gbyy42299/article/detai
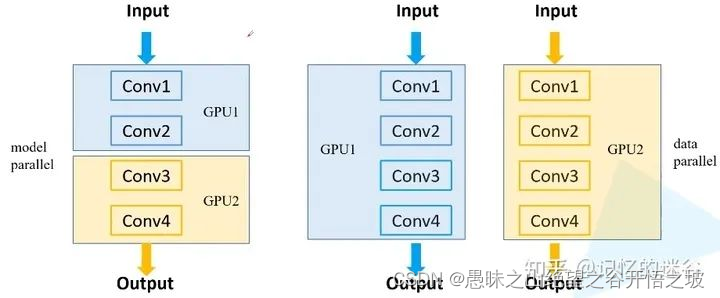
为什么要使用多GPU并行训练,单卡和多卡训练,bs和lr的关系
参考 https://jishuin.proginn.com/p/763bfbd63d50 理解 为什么要使用多GPU并行训练 简单来说,有两种原因:第一种是模型在一块GPU上放不下,两块或多块GPU上就能运行完整的模型(如早期的AlexNet)。第二种是多块GPU并行计算可以达到加速训练的效果。想要成为“炼丹大师“,多GPU并行训练是不可或缺的技能。 常见的多GPU训练方法: 1.模型并
Pytorch采坑记录:DDP 损失和精度比 DP 差,多卡GPU比单卡GPU效果差
结论:调大学习率或者调小多卡GPU的batch_size 转换DDP模型后模型的整体学习率和batch_size都要变。 当前配置::1GPU:学习率=0.1,batch_size=64 如果8GPU还按之前1GPU配置:8GPU:学习率=0.1,batch_size=64 那么此时对于8GPU而言,效果几乎等于::1GPU:学习率=0.1,batch_size=64 * 8=512 这种
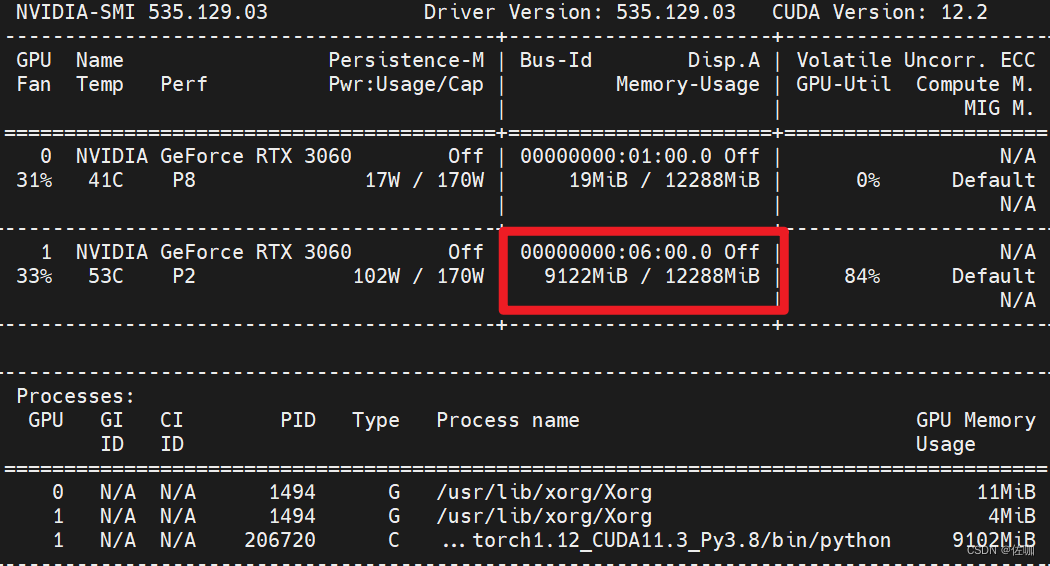
Pytorch——多卡GPU训练与单卡GPU训练相互切换
部分深度学习网络默认是多卡并行训练的,由于某些原因,有时需要指定在某单卡上训练,最近遇到一个,这里总结如下。 目录 一、多卡训练1.1 修改配置文件1.2 修改主训练文件1.3 显卡使用情况 二、单卡训练2.1 修改配置文件2.2 显卡使用情况 三、总结 一、多卡训练 1.1 修改配置文件 1.2 修改主训练文件 上面红框中代码解析: if torch.cuda.is

esxi能直通的显卡型号_单卡gpu直通,黑苹果,amd_cpu教程
本文github地址: Bebove/macos-kvmgithub.com 适用: amd cpu(intel 也行?) nvidia 显卡,单卡。 安装黑苹果,(qemu虚拟机),通过pcie硬件直通,完成几乎没有性能损耗的黑苹果虚拟机。 难点: 单卡,ubuntu宿主机器需要关闭xserver释放显卡占用。需要主板支持iommu直通。 step1 install ubuntu 1