本文主要是介绍Pytorch——多卡GPU训练与单卡GPU训练相互切换,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
部分深度学习网络默认是多卡并行训练的,由于某些原因,有时需要指定在某单卡上训练,最近遇到一个,这里总结如下。
目录
- 一、多卡训练
- 1.1 修改配置文件
- 1.2 修改主训练文件
- 1.3 显卡使用情况
- 二、单卡训练
- 2.1 修改配置文件
- 2.2 显卡使用情况
- 三、总结
一、多卡训练
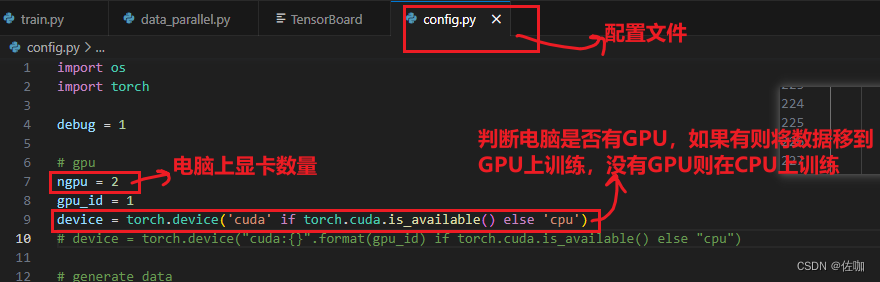
1.1 修改配置文件
1.2 修改主训练文件
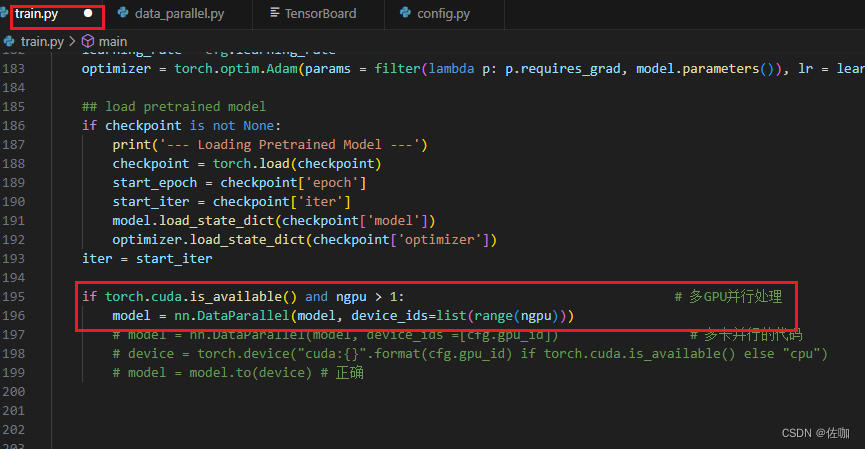
上面红框中代码解析:
if torch.cuda.is_available() and ngpu > 1: # 当 torch.cuda.is_available() 为真且 ngpu > 1 时 model = nn.DataParallel(model, device_ids=list(range(ngpu)))
model = nn.DataParallel(model, device_ids=list(range(ngpu))):
此行代码创建了一个 DataParallel包装器,用于在多个GPU上并行处理神经网络模型。DataParallel 是 PyTorch 中的一个模块,它可以将输入数据分割并发送到不同的GPU进行处理,然后汇总结果。
model:要并行化的神经网络模型。
device_ids=list(range(ngpu)):指定要使用的GPU。在这里,它使用了所有可用的GPU,数量上限为指定的 ngpu。
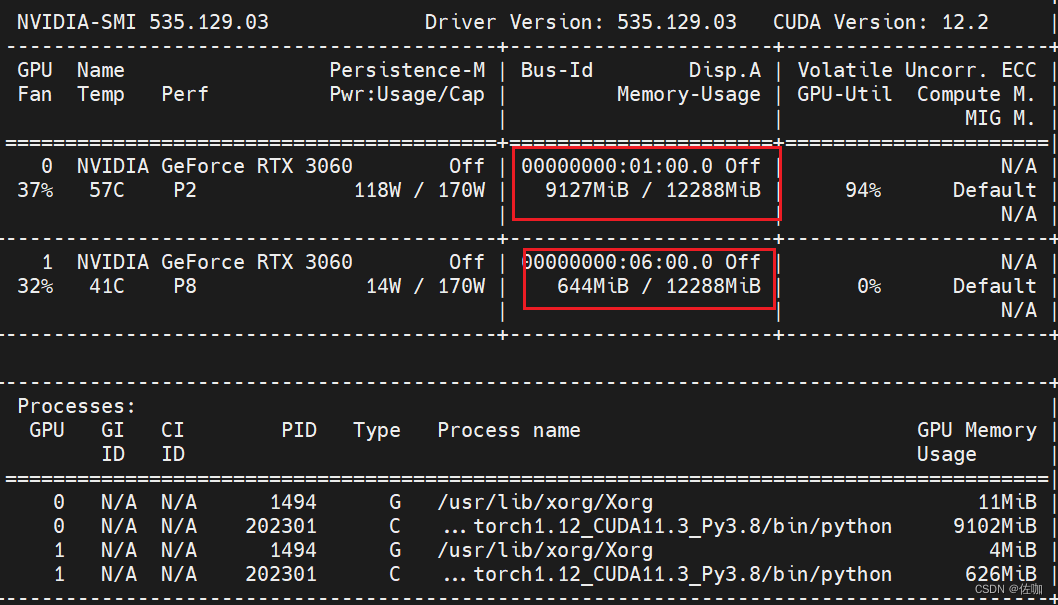
1.3 显卡使用情况
二、单卡训练
2.1 修改配置文件
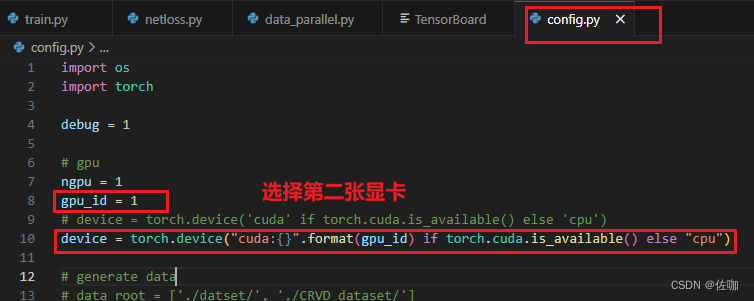
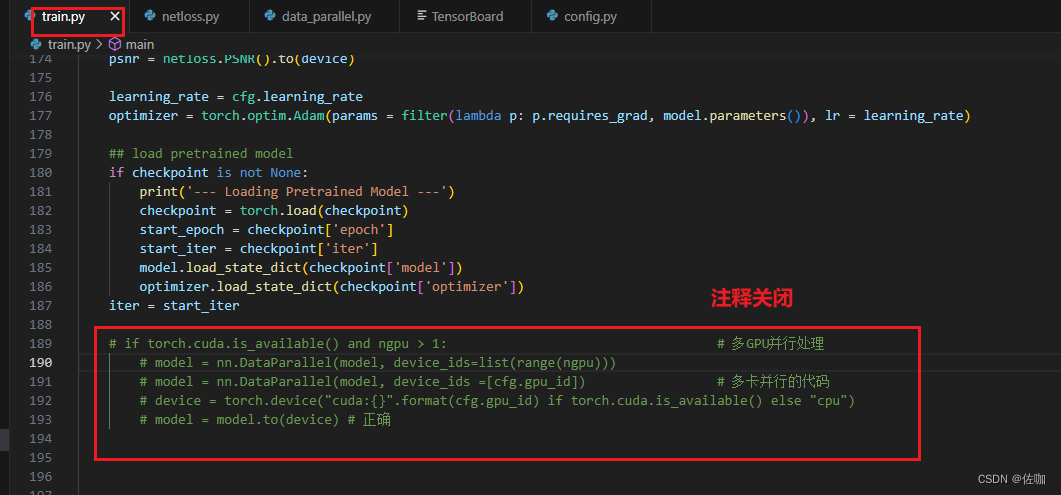
2.2 显卡使用情况
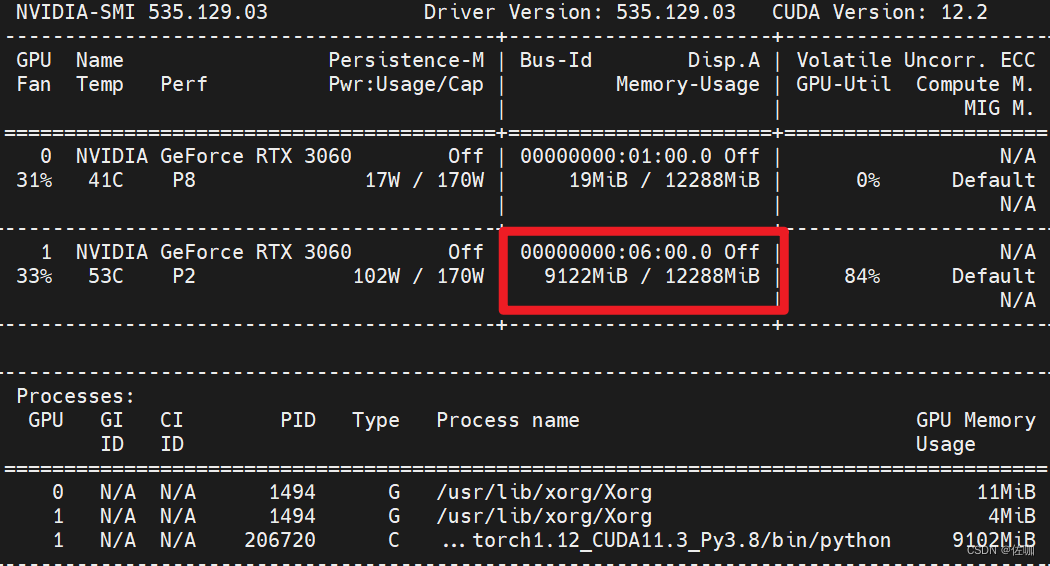
修改好后开始训练,查看显卡使用情况:
三、总结
以上就是多卡GPU训练与单卡GPU训练相互切换的操作过程,希望能帮到你,谢谢!
这篇关于Pytorch——多卡GPU训练与单卡GPU训练相互切换的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







