多卡专题

欺诈文本分类检测(十一):LLamaFactory多卡微调
1. 引言 前文训练时都做了一定的编码工作,其实有一些框架可以支持我们零代码微调,LLama-Factory就是其中一个。这是一个专门针对大语言模型的微调和训练平台,有如下特性: 支持常见的模型种类:LLaMA、Mixtral-MoE、Qwen、Baichuan、ChatGLM等等。支持单GPU和多GPU训练。支持全参微调、Lora微调、QLora微调。 …… 还有很多优秀的特性,详细参考

多机多卡分布式训练的一种简易实现
目录 1. 前言2. pssh技术2.1 pssh简介2.2 pssh使用 3. 多机互连4. 一键分布式训练4.1 全局变量4.2 在tmux中启动run.sh4.3 在master节点上进行启动 1. 前言 在没有机器学习平台(例如阿里云的PAI,美团的万象等)的情况下,启动多机多卡分布式训练通常需要手动在每台机器上启动相应的训练脚本,而启动脚本的前提是要先ssh连接到这台

基于华为昇腾910B和LLaMA Factory多卡微调的实战教程
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于大模型算法的研究与应用。曾担任百度千帆大模型比赛、BPAA算法大赛评委,编写微软OpenAI考试认证指导手册。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。授权多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。

多机多卡推理部署大模型
搭建一个多机多卡环境下的大模型推理系统,利用Ray和VLLM框架,可以充分利用分布式计算资源,提升模型的推理效率。下面是一个简化的指南,帮助你理解如何使用Ray和VLLM来部署一个分布式的大规模语言模型推理系统。 准备工作 1. 安装必要的软件包:确保你的环境中安装了Python、Ray库以及VLLM。VLLM是一个专门针对大规模语言模型的高性能推理库,支持多GPU和多节点部署。 pip inst
torch多机器多卡推理大模型
在PyTorch中,多机推理通常涉及使用DistributedDataParallel模块。以下是一个简化的例子,展示如何在多台机器上进行PyTorch模型的推理。 假设你有两台机器,IP分别为192.168.1.1和192.168.1.2,你想在第一台机器上进行模型的推理。 在每台机器上设置环境变量: export MASTER_ADDR=192.168.1.1export MAS

动手学深度学习33 单机多卡并行
单机多卡并行 更多的芯片 https://courses.d2l.ai/zh-v2/assets/pdfs/part-2_2.pdf 多GPU训练 https://courses.d2l.ai/zh-v2/assets/pdfs/part-2_3.pdf 当transformer模型很大,有100GB的时候只能用模型并行。 数据并行,拿的参数是完整的? QA 1 当有一块卡显
DeepSeek-V2-Chat多卡推理(不考虑性能)
@TOC 本文演示了如何使用accelerate推理DeepSeek-V2-Chat(裁剪以后的模型,仅演示如何将权值拆到多卡) 代码 import torchfrom transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfigfrom accelerate import init_empty_wei

【AI大模型】Transformers大模型库(七):单机多卡推理之device_map
目录 一、引言 二、单机多卡推理之device_map 2.1 概述 2.2 自动配置,如device_map="auto" 2.2 手动配置,如device_map="cuda:1" 三、总结 一、引言 这里的Transformers指的是huggingface开发的大模型库,为huggingface上数以万计的预训练大模型提供预测、训练等服

pytorch使用DataParallel并行化保存和加载模型(单卡、多卡各种情况讲解)
话不多说,直接进入正题。 !!!不过要注意一点,本文保存模型采用的都是只保存模型参数的情况,而不是保存整个模型的情况。一定要看清楚再用啊! 1 单卡训练,单卡加载 #保存模型torch.save(model.state_dict(),'model.pt')#加载模型model=MyModel()#MyModel()是你定义的创建模型的函数,就是先初始化得到一个模型实例,之后再将模型参数加
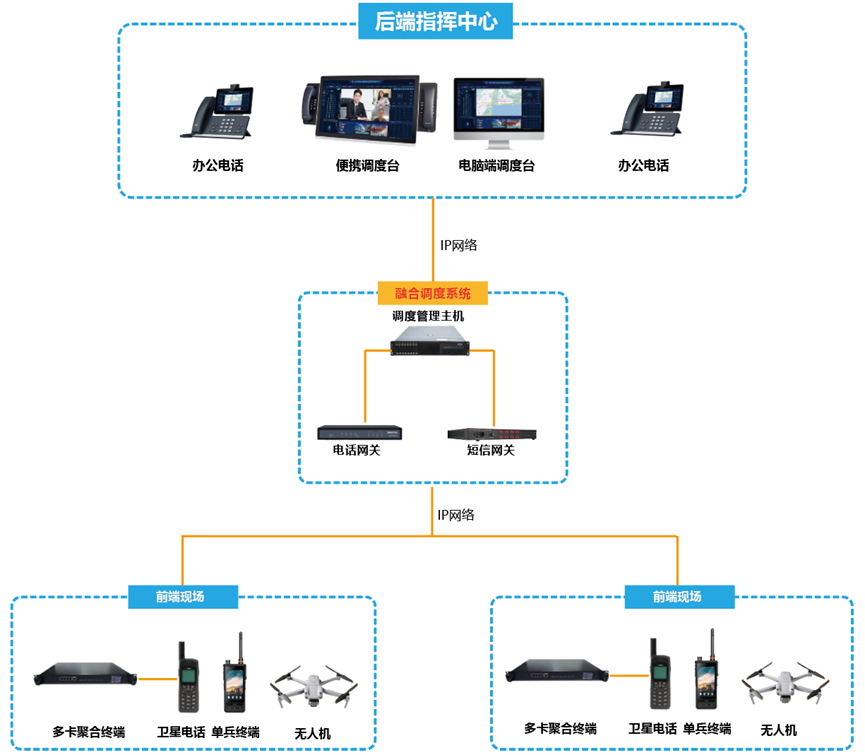
多卡聚合智能融合通信设备在无人机无线视频传输应用
无人驾驶飞机简称“无人机”,是利用(无线电)遥控设备和自备的程序控制装置操纵的不载人飞行器,现今无人机在航拍、农业、快递运输、测绘、新闻报道多个领域中都有深度的应用。 无人机无线视频传输保证地面人员利用承载的高灵敏度照相机可以进行不间断的画面拍摄,获取影像资料,并将所获得信息和图像通过图像传输系统传送回地面,将飞行中的无人机所拍摄的画面实时稳定的发射给地面无线图传遥控接收设备。
Ubuntu Nvidia Docker单机多卡环境配置
ubuntu版本是22.04,现在最新版本是24.xx,截止当前,Nvidia的驱动最高还是22.04版本,不建议更新至最新版本。本部分是从0开始安装Nvidia docker的记录,若已安装Nvdia驱动,请直接跳至3。 1、更新软件软件列表 更新apt,安装gcc、g++等 apt-get updateapt-get install g++ gcc make 2、Nvidia显卡安
yolov8 ultralytics库实现多机多卡DDP训练
参考: https://github.com/ultralytics/ultralytics/issues/6286 ddp训练报错,问题修改: https://blog.csdn.net/weixin_41012399/article/details/134379417 RuntimeError: CUDA error: invalid device ordinal CUDA kernel
yolov8 ultralytics库进行多机多卡DDP训练
参考: https://github.com/ultralytics/ultralytics/issues/6286 ddp训练报错,问题修改: https://blog.csdn.net/weixin_41012399/article/details/134379417 RuntimeError: CUDA error: invalid device ordinal CUDA kernel
torch 单机 多卡 训练(二)
pytorch.distributed.launch和torchrun的对比 多卡训练 真的烦 并行训练最大的好处,在于GPU内存变大,不是变快 torch.distributed.launch CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 -
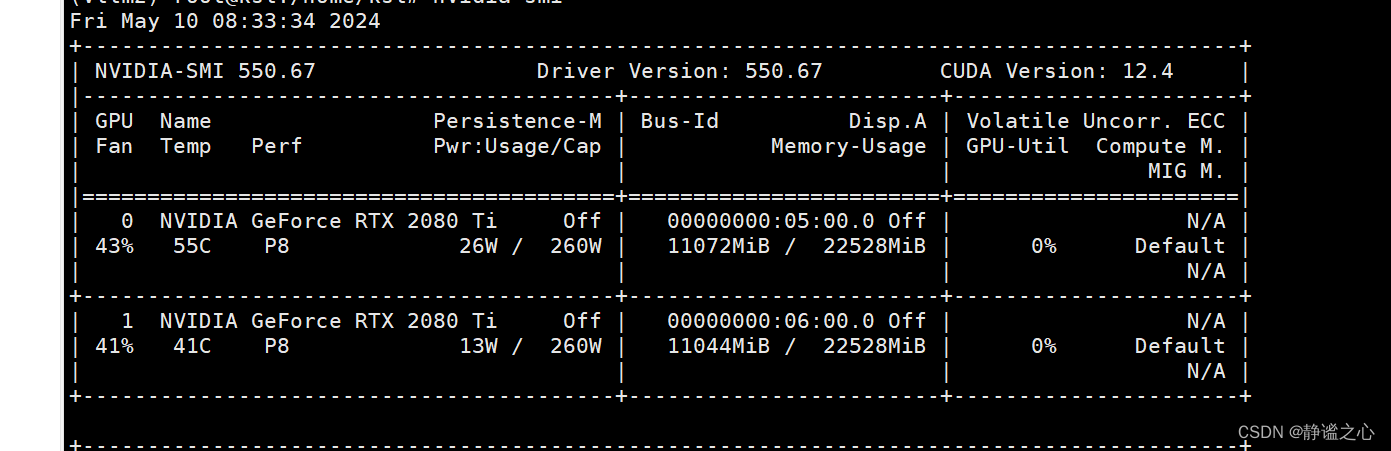
Fastchat + vllm + ray + Qwen1.5-7b 在2080ti 双卡上 实现多卡推理加速
首先先搞清各主要组件的名称与作用: FastChat FastChat框架是一个训练、部署和评估大模型的开源平台,其核心特点是: 提供SOTA模型的训练和评估代码 提供分布式多模型部署框架 + WebUI + OpenAI API Controller管理分布式模型实例 Model Worker是大模型服务实例,它在启动时向Controller注册 OpenAI API提供OpenAI兼容的A
LLaMA Factory多卡微调的实战教程
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,CCF比赛第二名,科大讯飞比赛第三名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍了LLaMA Factory多卡微调的实战教程,希望对学习大语言模型的
Trl SFT: llama2-7b-hf使用QLora 4bit量化后ds zero3加上flash atten v2单机多卡训练(笔记)
目录 一、环境 1.1、环境安装 1.2、安装flash atten 二、代码 2.1、bash脚本 2.2、utils.py 注释与优化 2.3、train.py 注释与优化 2.4、模型/参数相关 2.4.1、量化后的模型 2.4.1.1 量化后模型结构 2.4.1.2 量化后模型layers 2.4.2
Trl: llama2-7b-hf使用QLora 4bit量化后ds zero3加上flash atten v2单机多卡训练(笔记)
目录 一、环境 1.1、环境安装 1.2、安装flash atten 二、代码 2.1、bash脚本 2.2、utils.py 注释与优化 2.3、train.py 注释与优化 2.4、模型/参数相关 2.4.1、量化后的模型 a) 量化后模型结构 b) 量化后模型layers 2.4.2、参数
Pytorch多机多卡分布式训练
多机多卡分布式: 多机基本上和单机多卡差不多: 第一台机器(主设备): torchrun --master_port 6666 --nproc_per_node=8 --nnodes=${nnodes} --node_rank=0 --master_addr=${master_addr} train_with_multi_machine_and_multi_gpu.py 第二台机器(从
DistributedDataParallel后台单机多卡训练
后台单机多卡训练 文章目录 后台单机多卡训练参考链接如何单机多卡DistributedDataParallel 如何后台训练screen ......nohup train.sh ..... 参考链接 Pytorch分布式训练(单机多卡)Linux screen命令Linux使用screen执行长时间运行的任务 如何单机多卡 一种是torch.nn.DataPara
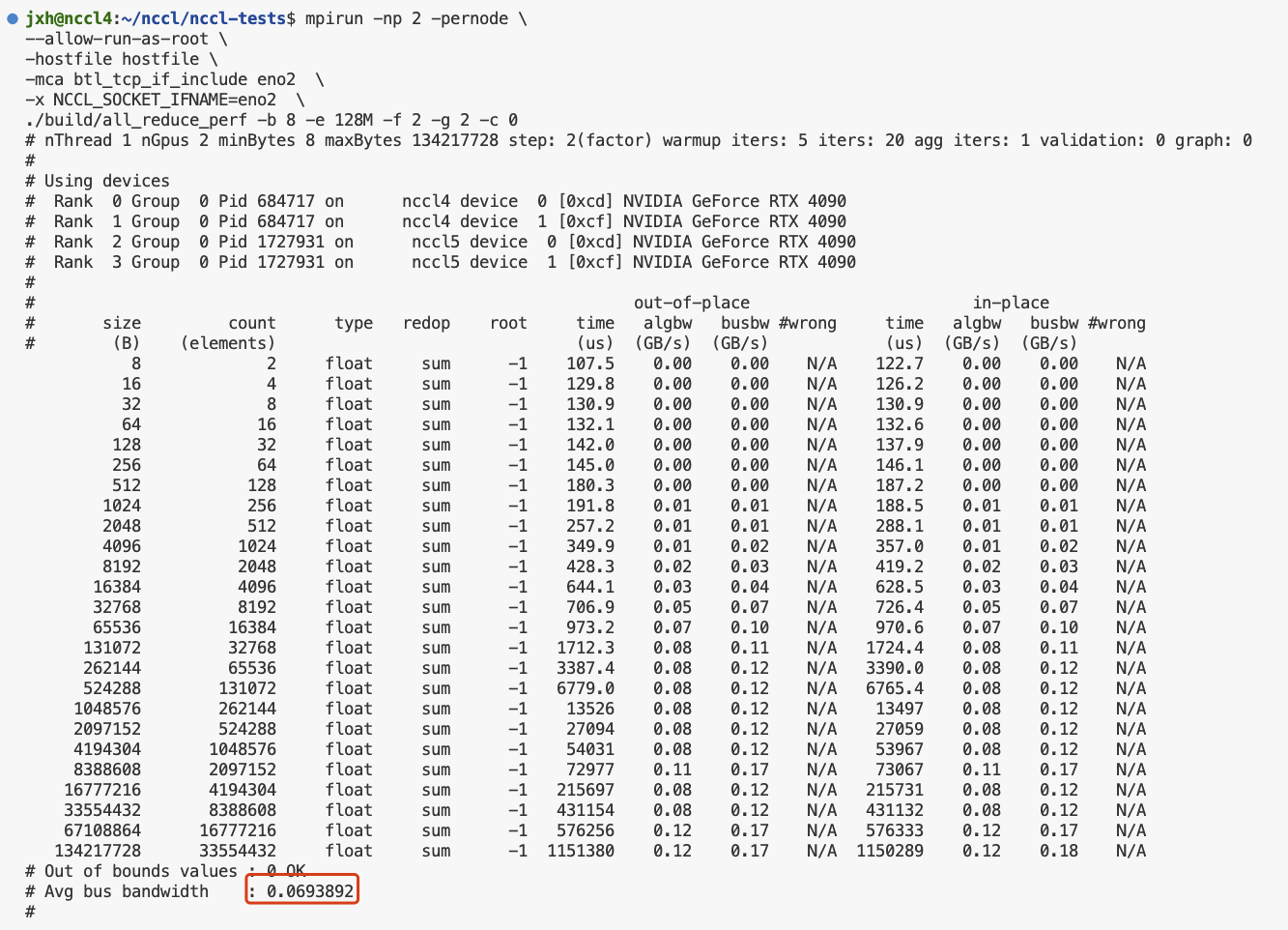
多机多卡运行nccl-tests和channel获取
nccl-tests 环境1. 安装nccl2. 安装openmpi3. 单机测试4. 多机测试mpirun多机多进程多节点运行nccl-testschannel获取 环境 Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)cuda 11.8+ cudnn 8nccl 2.15.1NVIDIA GeForce RTX

mmpose单机多卡训练问题
当使用单卡训练时运行命令:python tools/train.py ${CONFIG_FILE} [ARGS]是可以跑通的,但是使用官方提供的:bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]进行单机多卡训练时却报如下错误: ....torch.cuda.OutOfMemoryError: CUDA out of m

多卡聚合设备保障智能安防网络 稳定安全
随着平安城市、智慧城市等项目的不断推进,目前,我国一个二线以上城市的监控摄像头数量就可能达到百万量级。若将这些摄像头产生的原始视频传送到云端进行分析,耗费的资源可想而知。 5G带给安防4K/8K等超高清体验,并使海量终端接入网络,但与此同时,通信网络的承载负担无疑也在之前的基础上被大大加重。 面对5G带来的海量数据,边缘计算能够在近端进行处理,减少在云端之间来回传输数据的需要,可对生物识别、人
deepseed 单机多卡程序报错:exits with return code -7
现象:exits with return code -7原因:Setting the shm-size to a large number instead of default 64MB when creating docker container solves the problem in my case. It appears that multi-gpu training relies on
数据采集卡:4位32路256K同步模拟量输入卡,支持外触发、外时钟,支持多卡同步
产品应用 USB-XM2432是一款基于USB2.0总线的数据采集卡,可直接和计算机的USB口相连,构成实验室、产品质量检测中心等各种领域的数据采集、波形分析和处理系统。也可构成工业生产过程监控系统。它的主要应用场合为: 电子产品质量检测 医学检测 高精度信号同步采集 IO控制 性能特点 A/D转换器:24-bit Σ-Δ型ADC:AD7768 本体噪声低,通道隔离度高; 差分输
pytorch 多卡训练 accelerate gloo
目录 accelerate 多卡训练 Windows例子 gloo 多卡训练 accelerate 多卡训练 Windows例子 import torchfrom torch.nn.parallel import DistributedDataParallel as DDPfrom torch.utils.data import DataLoader, RandomSample