本文主要是介绍torch 单机 多卡 训练(二),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pytorch.distributed.launch和torchrun的对比
多卡训练
真的烦
- 并行训练最大的好处,在于GPU内存变大,不是变快
torch.distributed.launch
CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 --nnodes=1 --use_env kdef_ir50_comb.py --batch_size 32 --learning_rate 0.001 --epochs 300 --temp 0.1 --weight_decay 1e-4 --model IR_50 --method SupCon --cosin --special mod_Linear_Bn
- 缺点:需要执行设备数
- 没有指定设备导致的问题
torch.distributed.run
python -m torch.distributed.run --nproc_per_node=4 --nnodes=1 kdef_ir50_comb.py --batch_size 32
--learning_rate 0.001 --epochs 300 --temp 0.1 --weight_decay 1e-4 --model IR_50 --method SupCon
--cosin --special mod_Linear_Bn
- 效果一样
有时候,直接python 也能并行
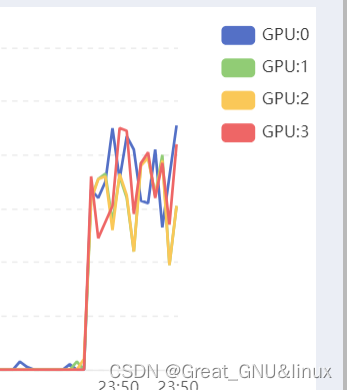
- 暂时不清楚机理
这篇关于torch 单机 多卡 训练(二)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







