本文主要是介绍SuperMap GIS大数据分析调优行动指南,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SuperMap GIS大数据分析调优行动指南
文章目录
- SuperMap GIS大数据分析调优行动指南
- 一、大数据分析调优目的
- 二、调优思路
- 2.1 Spark环境调优
- 2.2 数据调优
- 2.2.1 如何选择合适的存储数据库
- 2.2.2 数据库调优
- HDFS
- PostGIS
- 2.2.3 数据优化
- 2.3 SuperMap GIS产品调优
- 2.3.1 SuperMap GIS引擎调优
- JDBC
- DSF
- SDX
- 2.3.2 JDBC、DSF、SDX该如何选择
- 三、可能遇到的问题及解决办法
- 问题一:Spark运行过程中报错java.Lang.UnsatisfiedinkError:supermap.data.EnvironmentNative.jni GetBasePath()Ljava/lang/String;
- 四、更便捷的大数据分析方式
一、大数据分析调优目的
项目数据量达到千万,如果需要进行千万级与千万级数据一起分析时,很多客户会考虑选择SuperMap GIS基础软件(下文简称GIS软件)大数据模块。大数据模块环境配置较其它产品相对复杂,Spark等环境需要在Linux通过命令行来设置,对项目实施来说可能会有一定门槛。
从多年大数据分析项目经验总结出一套调优参考办法,可供参考。
二、调优思路
大数据分析调优主要主要有三种思路:Spark集群调优、数据调优、 GIS软件调优,如下图:
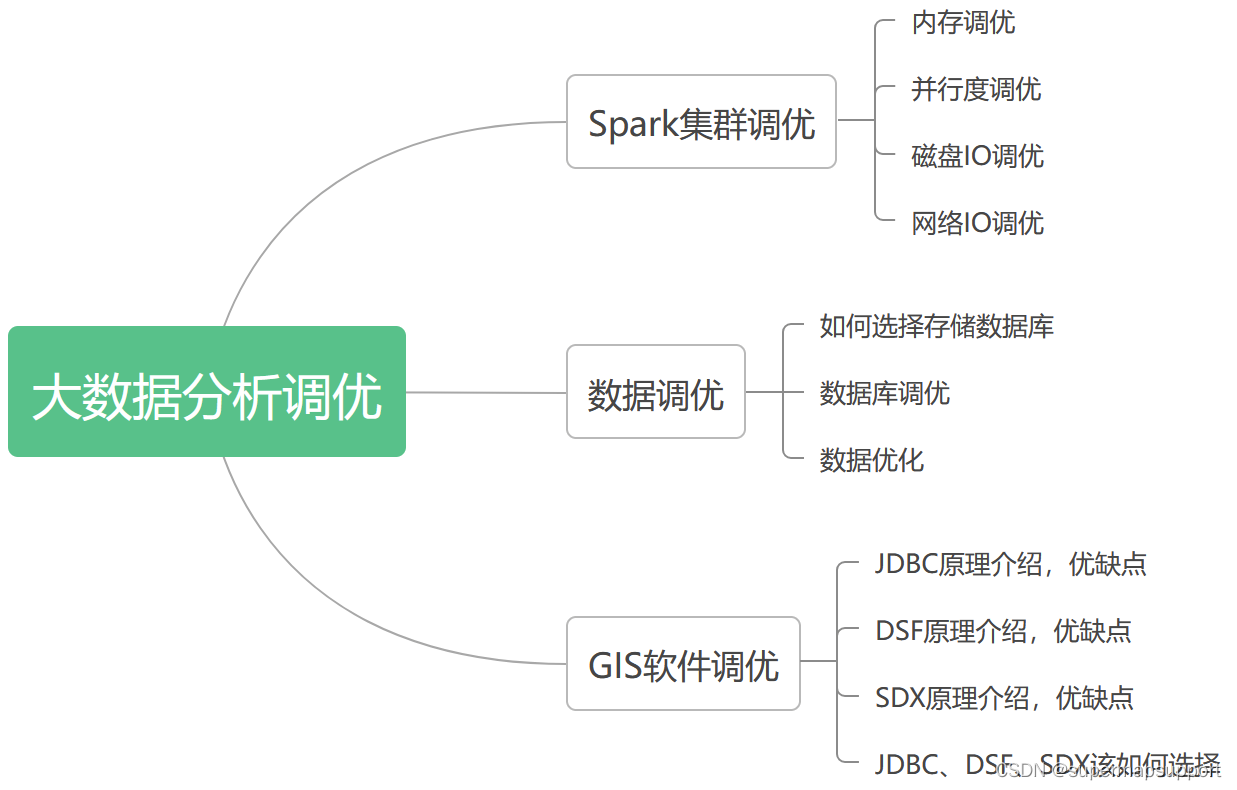
2.1 Spark环境调优
Spark参数优化主要集中在spark-defaults.conf文件中,本文从以下四个方面进行调优参数介绍:
-
内存调优:在spark-defaults.conf文件进行修改
-
并行度调优:在spark-defaults.conf文件进行修改
-
磁盘IO调优:在spark-defaults.conf文件进行修改
-
网络IO调优:在spark-defaults.conf文件进行修改
具体参数介绍及推荐值如下表所示,在您修改参数后,请重启Spark确保参数修改生效:
| 调优方向 | 配置项 | 配置项描述 | 默认值 | 推荐值 |
|---|---|---|---|---|
| 内存调优 | spark.driver.memory | 用于设置Driver进程的内存大小 | 1GB | 2GB或4GB |
| spark.executor.memory | 用于设置Executor进程的内存大小 | 1GB | 2GB或4GB | |
| spark.memory.fraction | 用于设置Spark内存管理器的堆内存占比 | 0.6 | 0.5或0.7 | |
| spark.memory.storageFraction | 用于设置Spark内存管理器的存储内存占比 | 0.5 | 0.4或0.6 | |
| spark.executor.memoryOverhead | 用于设置Executor除了执行任务所需的内存之外,还需要额外保留的内存大小 | max(384m, 10% of spark.executor.memory) | Executor的额外内存大小,可以设置为一个较小的值,如256M | |
| 并行度调优 | spark.default.parallelism | 用于设置RDD的默认并行度 | 默认值为当前集群的CPU核数 | 2~4倍的CPU核数 |
| spark.sql.shuffle.partitions | 用于设置Shuffle操作的并行度 | 200 | 1000或更高 | |
| spark.cores.max | 设置每个应用程序能够使用的最大CPU核心数 | 当前集群CPU核数 | 如果您的应用程序需要大量的CPU资源,那么可以将这个参数设置为接近或等于可用CPU核心的总数,否则推荐设置为CPU核心数的70%~80%左右 | |
| 磁盘IO调优 | spark.local.dir | 用于设置本地磁盘临时目录存储路径 | /tmp | 设置为具有足够磁盘空间的本地目录路径,以确保Spark应用程序有足够的空间来存储中间结果和其他缓存数据 |
| spark.shuffle.file.buffer | 用于设置Shuffle操作的缓冲区大小 | 32k | 64k或128k | |
| spark.reducer.maxSizeInFlight | 用于设置Reducer的最大输出大小 | 48m | 128m或256m | |
| 网络IO调优 | spark.rpc.message.maxSize | 用于设置RPC消息的最大大小 | 128MB | 如果您的应用程序需要处理大规模数据,可以将这个参数的值增加到512MB或更高 |
官方配置项(3.3.0版本)说明
http://spark.incubator.apache.org/docs/3.3.0/configuration.html
2.2 数据调优
2.2.1 如何选择合适的存储数据库
适合大数据存储和分析的数据库类型,因业务场景不同而有所不同,如下为SuperMap GIS产品中适合大数据存储分析的数据库类型、介绍及优缺点简要说明:
| 数据库类型 | 数据库介绍 | 优缺点 |
|---|---|---|
| Hadoop HDFS | Hadoop HDFS是Hadoop分布式文件系统的缩写,它是一个分布式文件系统,核心设计思想是将大文件分成块(block),并将这些块存储在不同的节点上,实现高可靠性、高吞吐量的数据访问,并支持在大规模集群上存储和处理数据 | 优点:可扩展性强,支持PB级别的数据存储; 缺点:不适合存储结构化数据,读写性能相对较低 |
| PostGIS | PostGIS基于PostgreSQL的一个开源的空间地理信息系统扩展,适用于存储和处理空间数据。它支持复杂的空间查询和分析,具有较高的可靠性和性能 | 优点:适合存储空间数据,具有处理空间数据的能力,提供了许多用于空间数据操作的函数和操作符,可以进行空间数据的查询和分析; 缺点:不适合存储非空间数据 |
| 其它 | 达梦、瀚高、禹贡、人大金仓、Oracle | 优点:支持的数据库种类繁多,满足各种数据库连接读取需求; 缺点:大部分数据库不能以JDBC方式读取,分布式读写性能比不上支持JDBC的库 |
综上所述,根据具体的应用场景和需求,可以选择不同的数据库,以下为各个场景的推荐库:
| 应用场景 | 推荐数据库 |
|---|---|
| 数据量上千万,支持存储地理分区要素数据集,写入DSF目录 | Hadoop HDFS |
| 需要存储和处理空间数据 | PostGIS |
| 需要存储到关系型数据库 | 达梦、瀚高、禹贡、人大金仓、Oracle 等 |
2.2.2 数据库调优
HDFS
HDFS调优,主要修改Hadoop/etc/hadoop/hdfs-site.xml文件:
- 增加数据块大小:可以通过增加HDFS数据块大小来提高读取性能。在hdfs-site.xml配置文件中,可以设置dfs.blocksize参数,默认为128MB。
- 增加副本数:可以通过增加HDFS数据块的副本数来提高读取性能和数据可靠性。在hdfs-site.xml配置文件中,可以设置dfs.replication参数,默认为3。
- 启用压缩:可以通过启用数据压缩来减少磁盘空间占用和网络传输开销。在hdfs-site.xml配置文件中,可以设置io.compression.codecs参数,选择需要的压缩算法,如org.apache.hadoop.io.compress.GzipCodec。
PostGIS
PostGIS调优,主要修改PostgreSQL/data/postgresql.conf:
- 增加缓存:可以通过增加缓存大小来提高读取性能。可以通过postgresql.conf配置文件中的shared_buffers参数来设置缓存大小,默认为128MB,通常建议设置为系统内存的1/4到1/3。
- 调整查询计划:可以通过调整查询计划来提高查询性能。可以通过postgresql.conf配置文件中的effective_cache_size(通常建议将其设置为系统内存的一半)、work_mem(建议设置为shared_buffers的1/16到1/8之间)等参数来调整查询计划。
- 启用字段索引:可以通过启用索引来提高查询性能。可以通过CREATE INDEX命令或pgAdmin等工具来创建索引,如:
CREATE INDEX idx_name ON table_name (column_name) WHERE column_name > 0;
- 空间索引:可以通过调整PostGIS的索引来提高查询性能。可以通过CREATE INDEX命令或pgAdmin等工具来创建索引,如:
CREATE INDEX mytable_gist_idx ON mytable USING gist (geom);
- 使用空间聚合:如ST_Union、ST_Collect和ST_ConvexHull等,可以将多个几何对象合并成一个对象。使用空间聚合可以减少查询的数据量,从而提高查询性能。
2.2.3 数据优化
除数据库配置优化外,对于具体的数据和数据量,本文主要推荐2种做法:
- 保证精度前提下,减少参与计算和分析的数据量
○常用办法:抽稀或者用数据库函数等操作去简化数据
- 数据量不可变情况下,为数据创建索引
○常用办法:参考2.2.2数据库调优及2.3SuperMap GIS产品调优部分
2.3 SuperMap GIS产品调优
2.3.1 SuperMap GIS引擎调优
GIS软件中,针对不同数据库使用的连接引擎有所不同,不同连接引擎支持数据库不同、优势存在差异,具体情况如下:
JDBC
- 引擎对应的连接数据库有:PostGIS、OracleSpatial
- 引擎介绍:Java数据库连接的缩写,是Java语言中用于连接和操作关系型数据库的API。JDBC提供了一个标准的接口,使得Java程序可以连接到不同的关系型数据库,并执行SQL查询和更新操作。JDBC可以在Java应用程序和数据库之间建立一条连接,并提供了一系列的接口和方法,用于执行SQL语句、处理结果集、管理事务等操作
- 优点:可在集群模式下可以实现分布式读写,极大提升性能
- 缺点:JDBC方式目前只支持读取PostGIS和OracleSpatial中的空间数据
- 调优方式:参考2.2.2数据库调优部分
DSF
- 引擎对应的连接数据库有:Hadoop HDFS
- 引擎介绍:分布式空间文件引擎(Distributed Spatial File,以下简称DSF),能够管理矢量、栅格和影像数据,兼备大体量空间数据的高性能分布式存取、空间查询、统计、分布式分析、空间可视化及数据管理能力
- 优点:DSF更加适合全量空间数据的高性能分布式计算,能够进一步强化海量经典空间数据的分布式存储和管理能力,显著提高大数据量的计算性能
- 缺点:数据需要提前建立地理分区索引,比直接从矢量数据读取分析会多一步操作。
- 调优方式:构建合适的索引
格网索引:数据分布比较均匀时使用该索引,需要设置一个合适的行列号,行列数目的设置依据每个格网内对象数据,形成的格网中对象数目控制在一定程度,比如面对象10w以内,点50w以内
四叉树索引:数据分布不均匀,呈现明显的聚集特点时使用该索引。地理分区要素数据集中每个分区对象数目最大值处理原则一般是,将数据集以 DSF
方式存储,每个 DSF 文件大小不超过 Hadoop 块文件大小(默认情形下,Hadoop 块大小是
256M)。例如点类型的要素数据集为50w对象,国土地类图斑数据为5w对象等
SDX
- 引擎对应的连接数据库有:达梦、瀚高、禹贡、人大金仓、Oracle 、PostGIS等
- 引擎介绍:SDX是SuperMap的空间引擎技术,它提供了一种通用的访问机制(或模式)来访问存储在不同引擎里的数据。这些引擎类型有数据库引擎、文件引擎和Web 引擎
- 优点:SDX面支持目前的主流商用关系数据库平台,提供了R树索引、四叉树索引、动态索引(多级格网索引)和图幅索引(三级索引),充分发挥每一种索引的优势,提高了数据访问和查询效率
- 缺点:由于SDX读写都是整库取到内存中,分布式读写效率不高
- 调优方式:通过桌面端提前对数据创建合适的空间索引与字段索引
2.3.2 JDBC、DSF、SDX该如何选择
| 使用场景 | 推荐的引擎 |
|---|---|
| 千万级别以上的数据 | DSF |
| 常规使用 | JDBC |
| 对于数据存储到不支持JDBC和DSF的库 | SDX |
三、可能遇到的问题及解决办法
问题一:Spark运行过程中报错java.Lang.UnsatisfiedinkError:supermap.data.EnvironmentNative.jni GetBasePath()Ljava/lang/String;
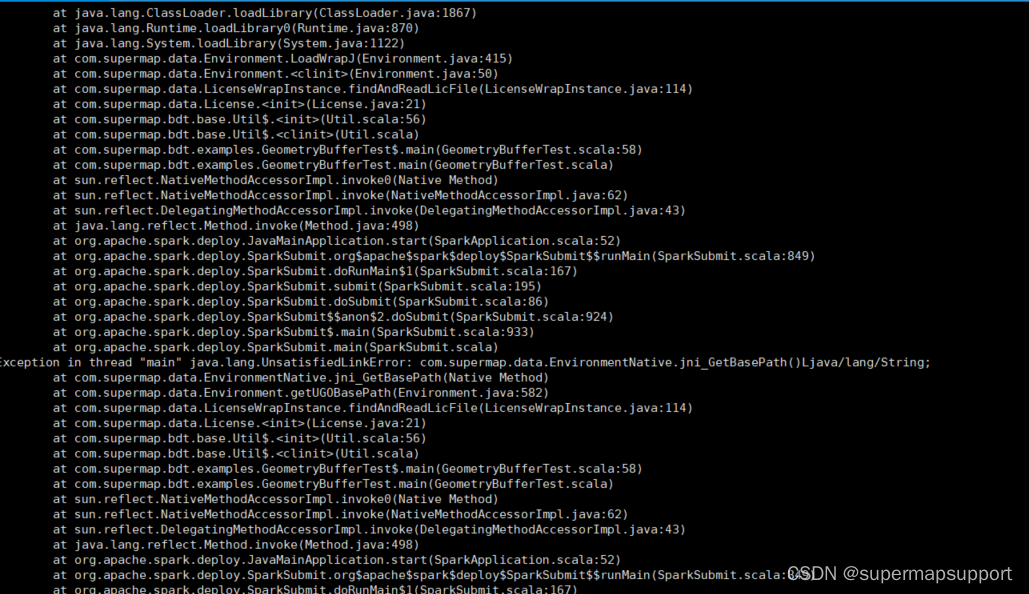
解决方案:这是由于没能读取到JAVA组件,需要检查JAVA组件是否已安装、安装后在系统中配置是否正确、是否缺少依赖;待组件配置正常后,再重新提交任务即可。
四、更便捷的大数据分析方式
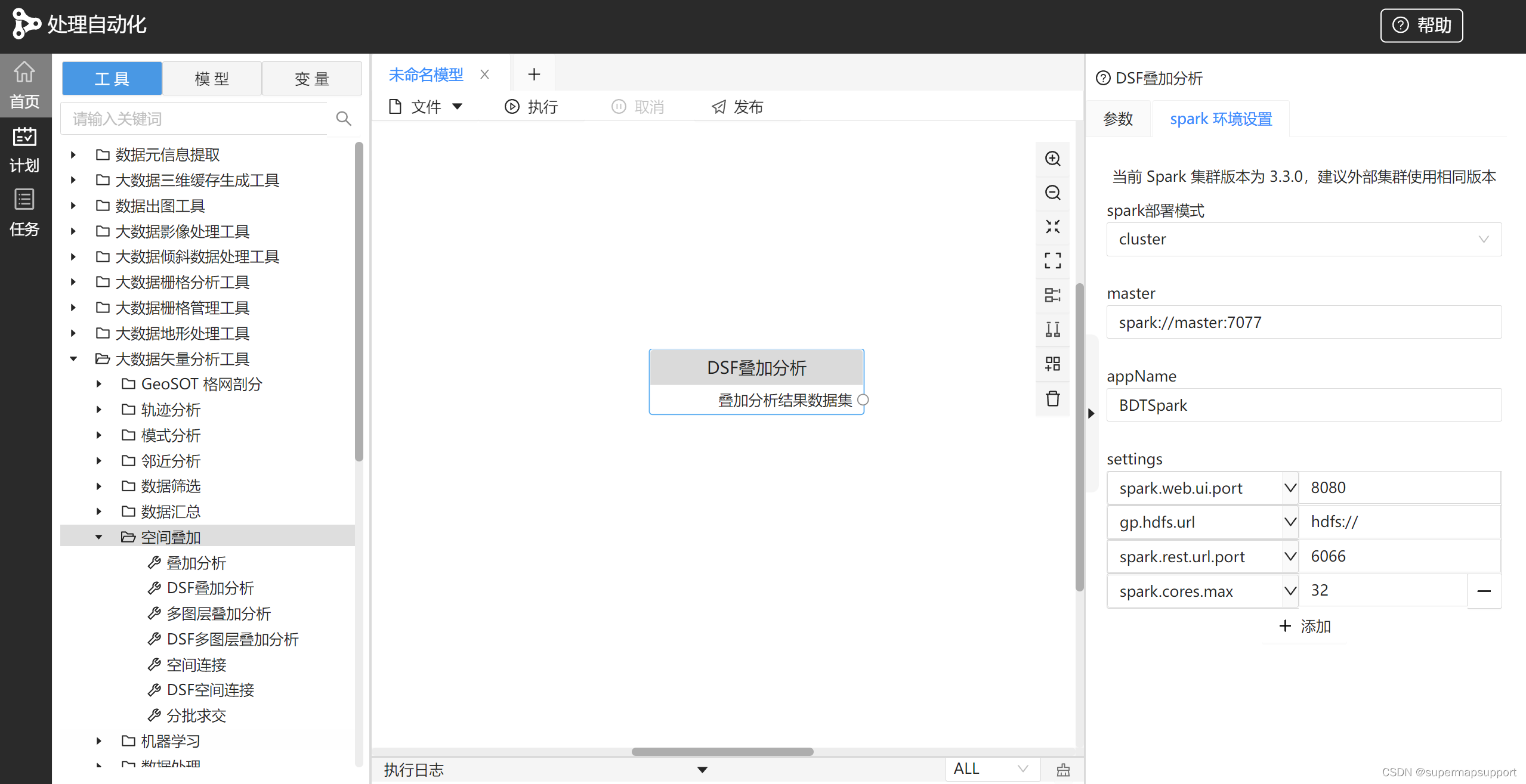
使用SuperMap GIS产品时,您可通过多种方式使用大数据分析。在此,推荐您使用SuperMap GIS中GPA模块(SuperMap iDesktopX与SuperMap iServer中均有提供)
- GPA提供100+算子,支持扩展自定义工具,开发人员无需编写复杂代码,便可以通过可视化建模简单快捷的搭建自己的业务流程,实现空间数据处理与分析过程的自动化;
- 对于Spark调优参数支持UI界面直接修改,无需重复修改Spark配置文件;
- 已有业务模型,支持导出与导入,可以方便快捷地共享复用,极大降低大数据分析的使用门槛。
这篇关于SuperMap GIS大数据分析调优行动指南的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







