本文主要是介绍MNIST数据集下的Softmax回归模型实验—我的第一个机器学习程序(包括MNIST数据集下载,Softmax介绍和源码),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MNIST数据集是一个入门级的计算机视觉数据集,它包含各种手写数字照片,它也包含每一张图片对应的标签,告诉我们这是数字几。
数据集被分成两部分:60000 行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。其中:60000 行的训练
部分拆为 55000 行的训练集和 5000 行的验证集。
接下来我将介绍一个简单的机器学习模型—CNN,来预测图片里面的数字。
首先介绍一下如何下载MNIST数据集
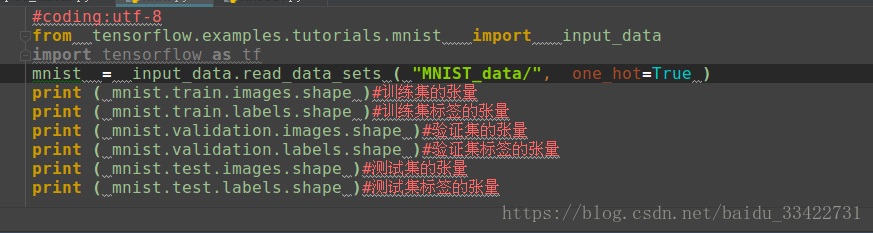
Tensorflow里面可以用如下代码导入MNIST数据集:
from tensorflow.examples.tutorials.mnist import input_datamnist = input_data.read_data_sets ( "MNIST_data/", one_hot=True )

成功获取MNIST数据集后,发现本地已经下载了4个压缩文件:
#训练集的压缩文件, 9912422 bytes
Extracting MNIST_data / train-images-idx3-ubyte.gz
#训练集标签的压缩文件,28881 bytes
Extracting MNIST_data / train-labels-idx1-ubyte.gz
#测试集的压缩文件,1648877 bytes
Extracting MNIST_data / t10k-images-idx3-ubyte.gz
#测试集的压缩文件,4542 bytes
Extracting MNIST_data / t10k-labels-idx1-ubyte.gz
我们可以在终端打印数据集的张量情况:
print ( mnist.train.images.shape ) #训练集的张量
print ( mnist.train.labels.shape ) #训练集标签的张量
print ( mnist.validation.images.shape ) #验证集的张量
print ( mnist.validation.labels.shape ) #验证集标签的张量
print ( mnist.test.images.shape ) #测试集的张量
print ( mnist.test.labels.shape ) #测试集标签的张量
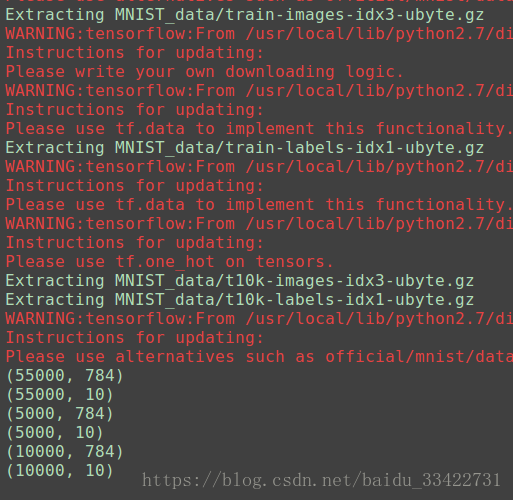
我们发现:
1、MNIST数据集包含 55000 行训练集、5000 行验证集和10000 行测试集
2、每一张图片展开成一个 28 X 28 = 784 维的向量,展开的顺序可以随意的,只要保证每张图片的展开顺序一致即可
3、每一张图片的标签被初始化成 一个 10 维的“one-hot”向量
数据集下载完之后就要进入构建模型阶段了
Softmax回归模型
当我们在数据集上进行训练的时候,模型判定一张图片是几往往依靠一个概率比如80%的概率为5,20%的概率为2,那么最终将会判定这个数字为5。
为了得到这个概率,我们使用Softmax模型,这个模型分为两步
第一步
为了得到一张给定图片属于某个特定数字类的证据(evidence),我们对图片像素值进行加权求和。如果这个像素具有很强的证据证明这张图片不属于该类,那么相应的权值为负数,相反如果这个像素拥有有利的证据支持这张图片属于这个类,那么权值是正数。我们也需要加入一个额外的偏置量(bias),因为输入往往会带有一些无关的干扰量。因此对于给定的输入图片x 它代表的是数字 i 的证据可以表示为
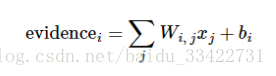
其中bi代表数字 i 类的偏置量,j代表给定图片 x 的像素索引用于像素求和。然后用softmax函数可以把这些证据转换成概率 y :
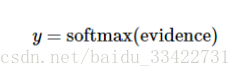
这里的softmax可以看成是一个激励(activation)函数或者链接(link)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。
softmax函数可以定义为:
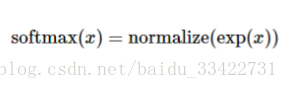
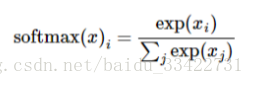
但是更多的时候把softmax模型函数定义为前一种形式:把输入值当成幂指数求值,再正则化这些结果值。这个幂运算表示,更大的证据对应更大的假设模型(hypothesis)里面的乘数权重值。反之,拥有更少的证据意味着在假设模型里面拥有更小的乘数系数。假设模型里的权值不可以是0值或者负值。Softmax然后会正则化这些权重值,使它们的总和等于1,以此构造一个有效的概率分布。
更进一步我们把Softmax模型写为
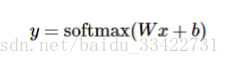
接下来我们来实现模型
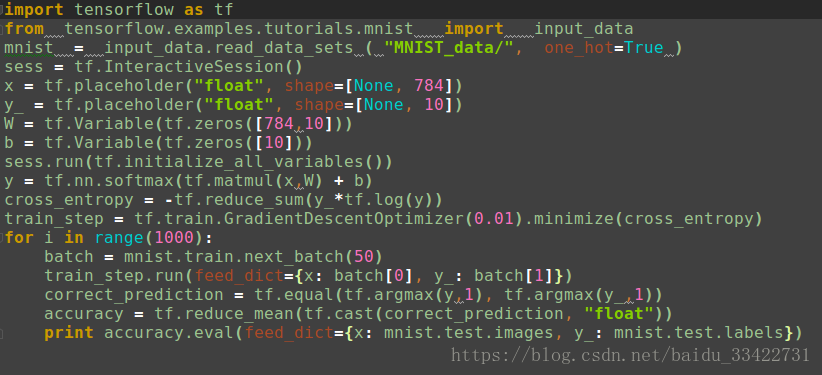
首先我们在使用Tensorflow时需要先导入:
import tensorflow as tf
然后设置一个占位符x,作为Tensorflow计算时的输入,允许输入任意数量图像,并且将其张开为784维向量我们用2维的浮点数张量来表示这些图,这个张量的形状是 [None,784 ] 。(这里的 None 表示此张量的第一个维度可以是任何长度的。)
x = tf.placeholder("float", shape=[None, 784])
我们的模型也需要权重值和偏置量,当然我们可以把它们当做是另外的输入(使用占位符),但TensorFlow有一个更好的方法来表示它们: Variable 。它们可以用于计算输入值,也可以在计算中被修改。对于各种机器学习应用,一般都会有模型参数,可以用 Variable 表示。
W = tf.Variable(tf.zeros([784,10])) b = tf.Variable(tf.zeros([10]))
我们赋予 tf.Variable 不同的初值来创建不同的 Variable :在这里,我们都用全为零的张量来初始化 W 和b 。因为我们要学习 W 和b 的值,它们的初值可以随意设置。
注意, W 的维度是[784,10],因为我们想要用784维的图片向量乘以它以得到一个10维的证据值向量,每一位对应不同数字类。 b 的形状是[10],所以我们可以直接把它加到输出上面。
现在,我们可以实现我们的模型
y = tf.nn.softmax(tf.matmul(x,W) + b)
模型至此已经写完了,接下来就要训练我们的模型
在机器学习中衡量一个模型好坏的因素,往往要通过损失(loss)或者是成本(cost),然后尽量最小化这两种指标来获取更好的模型,但从本质上来说两种方法取得的是一样的结果。
一个非常常见的成本函数是“交叉熵”(cross-entropy),今天我们也采用这个函数来训练我们的模型,它的定义如下:
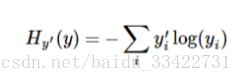
y 是我们预测的概率分布, y' 是实际的分布(我们输入的one-hot vector)。比较粗糙的理解是,交叉熵是用来衡量我们的预测用于描述真相的低效性。
为了计算交叉熵,我们首先需要添加一个新的占位符用于输入正确值:
y_ = tf.placeholder("float", shape=[None, 10])
然后我们可以用
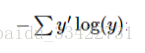
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
TensorFlow拥有一张描述你各个计算单元的图,它可以自动地使用反向传播算法(backpropagation algorithm)来有效地确定你的变量是如何影响你想要最小化的那个成本值的。然后,TensorFlow会用你选择的优化算法来不断地修改变量以降低成本。
在这里,我们要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵。梯度下降算法(gradient descent algorithm)是一个简单的学习过程,TensorFlow只需将每个变量一点点地往使成本不断降低的方向移动在这里,我们要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵。梯度下降算法(gradient descent algorithm)是一个简单的学习过程,TensorFlow只需将每个变量一点点地往使成本不断降低的方向移动。
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
现在,我们已经设置好了我们的模型。
Tensorflow依赖于一个高效的C++后端来进行计算。与后端的这个连接叫做session。一般而言,使用TensorFlow程序的流程是先创建一个图,然后在session中启动它。
这里,我们使用更加方便的 InteractiveSession 类。通过它,你可以更加灵活地构建你的代码。它能让你在运行图的时候,插入一些计算图,这些计算图是由某些操作(operations)构成的。这对于工作在交互式环境中的人们来说非常便利,比如使用IPython。如果你没有使用 InteractiveSession ,那么你需要在启动session之前构建整个计算图,然后启动该计算图。
sess = tf.InteractiveSession()
变量 需要通过seesion初始化后,才能在session中使用。这一初始化步骤为,为初始值指定具体值(本例当中是全为零),并将其分配给每个 变量 ,可以一次性为所有 变量 完成此操作。
sess.run(tf.initialize_all_variables())然后开始训练模型,这里我们让模型循环训练1000次!
for i in range(1000): batch = mnist.train.next_batch(50) train_step.run(feed_dict={x: batch[0], y_: batch[1]})该循环的每个步骤中,我们都会随机抓取训练数据中的100个批处理数据点,然后我们用这些数据点作为参数替换
之前的占位符来运行 train_step 。
使用一小部分的随机数据来进行训练被称为随机训练(stochastic training)- 在这里更确切的说是随机梯度下降训练。在理想情况
下,我们希望用我们所有的数据来进行每一步的训练,因为这能给我们更好的训练结果,但显然这需要很大的计算开销。所以,每一次
训练我们可以使用不同的数据子集,这样做既可以减少计算开销,又可以最大化地学习到数据集的总体特性。
最后就是评估我们的模型
tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如 tf.argmax(y,1) 返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
最后,我们计算所学习到的模型在测试数据集上面的正确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels})到这里Softmax模型就全部完成了,正确率在91%左右。
这篇关于MNIST数据集下的Softmax回归模型实验—我的第一个机器学习程序(包括MNIST数据集下载,Softmax介绍和源码)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





