本文主要是介绍学习笔记-李沐动手学深度学习(七)(19-21,卷积层、填充padding、步幅stride、多输入多输出通道),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
总结
19-卷积层
【补充】看评论区建议的卷积动画视频
数学中的卷积
【链接】https://www.bilibili.com/video/BV1VV411478E/?from=search&seid=1725700777641154181&vd_source=e81e116c4ffe5e79d4bc44738263eda4
【可判断是否为卷积的典型标志】两个函数中自变量相加是否可以消掉,如 下面的τ + x-τ = x
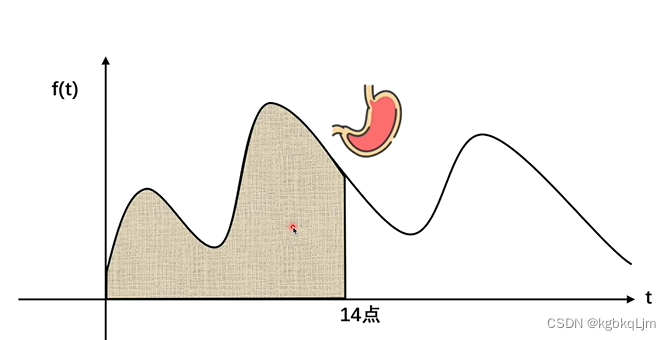
问在某一时刻 这个人的肚子中还有多少食物没消化:
f(t):进食的时间与进食的多少
g(t):某个吃进去的食物 剩余的比例

当不考虑用户消化食物时,下午两点时用户所剩食物就是f(t)的积分
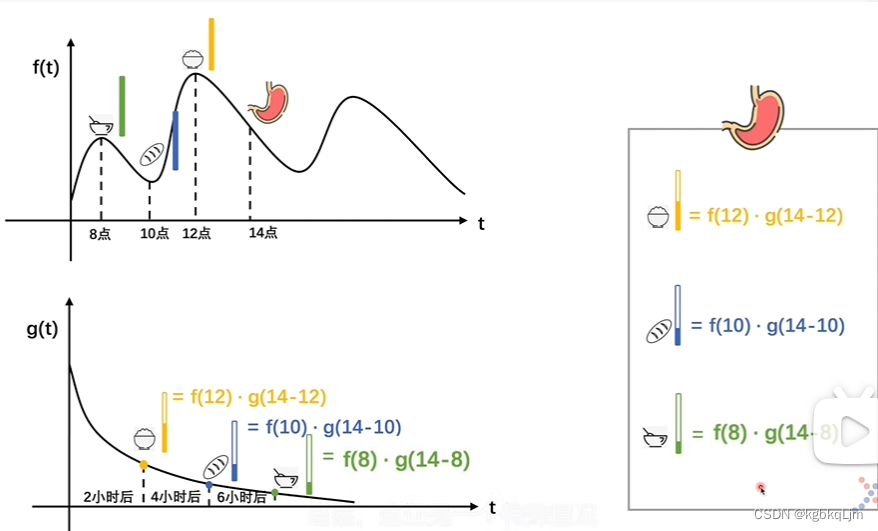
推广到一般情况:
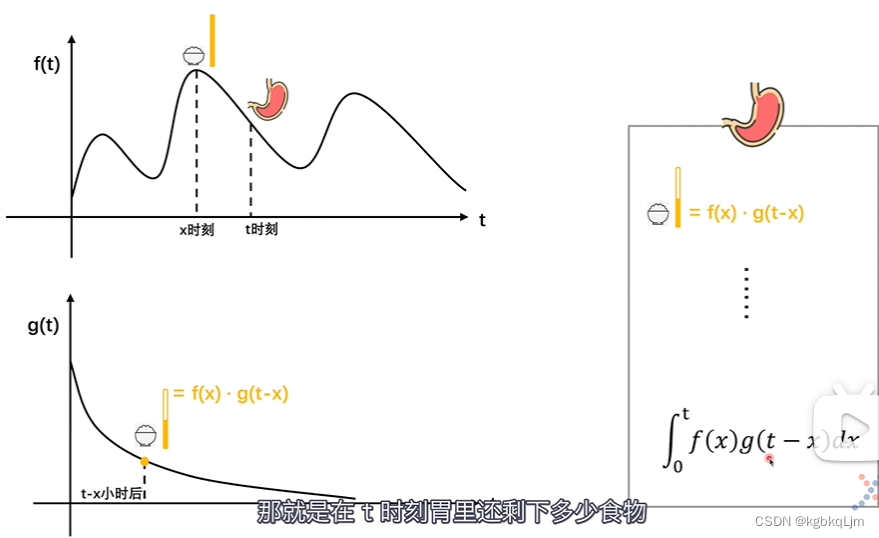

f(t)和g(t)中点的对应关系:
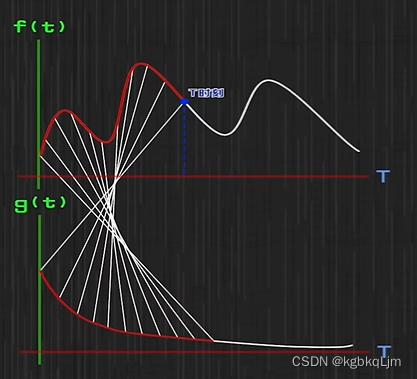
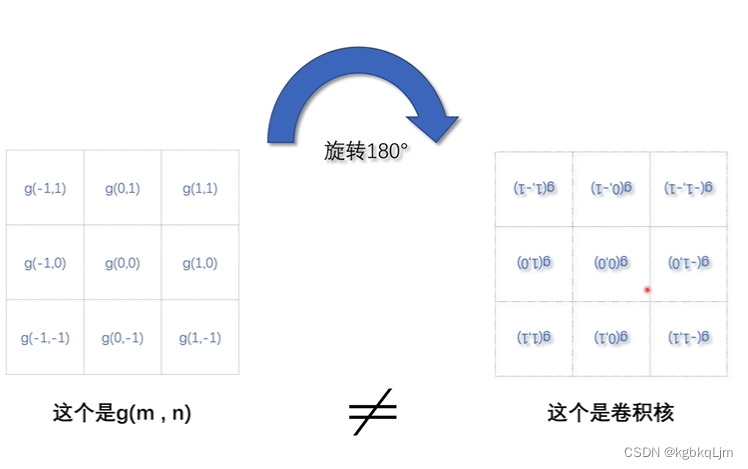
为什么叫卷积: g函数被翻转了一下
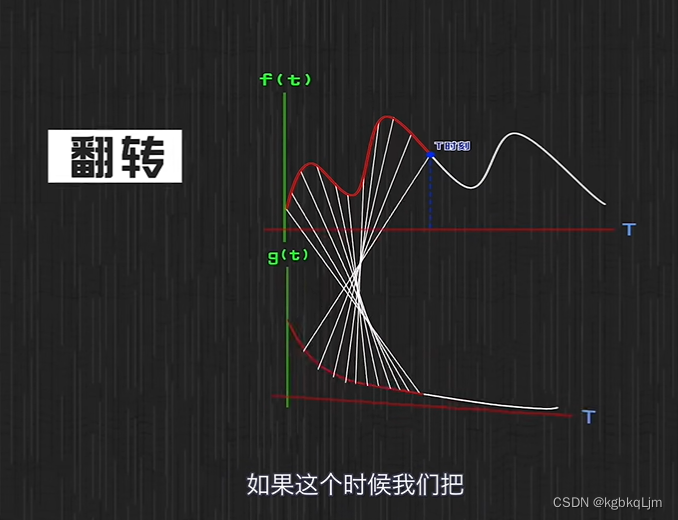
翻转后:
卷积神经网络



【举例】卷积处理图片后的效果
【卷积共有三层含义】

卷积核:过滤器,选择不同的卷积核可以提到不同的局部特征
【卷积核参数设置】
不想考虑某个位置时,卷积核某位置设为0;想重点考虑某位置时,将卷积核某位置数值设置比较高
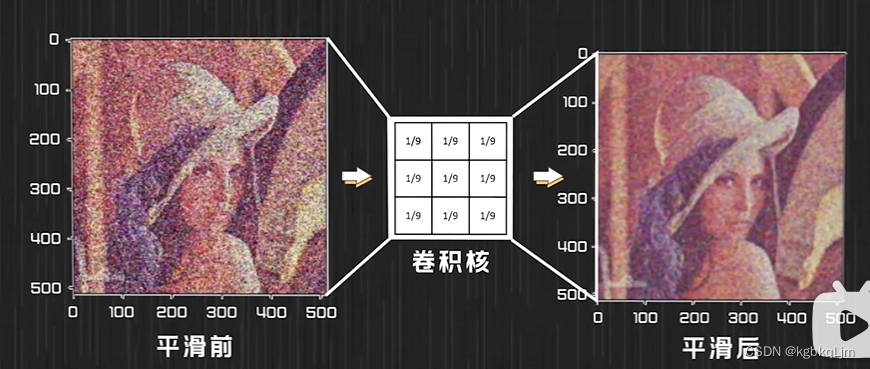
1.求均值的卷积核
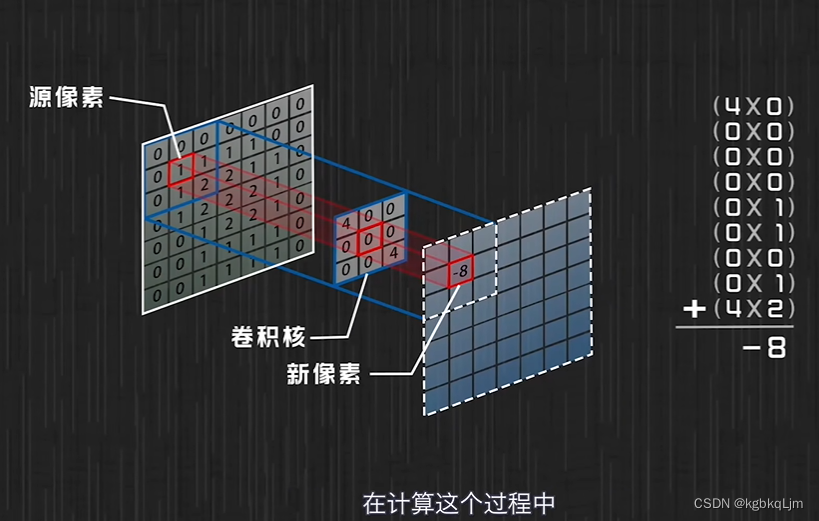
【符号】
*即卷积
Σ连加:因为 考虑的是像素点,是离散的,因此不用积分用 Σ累加
g函数相当于规定了 周围像素点如何对当前像素点产生的影响

下图看到,对应关系还是有点拧着的
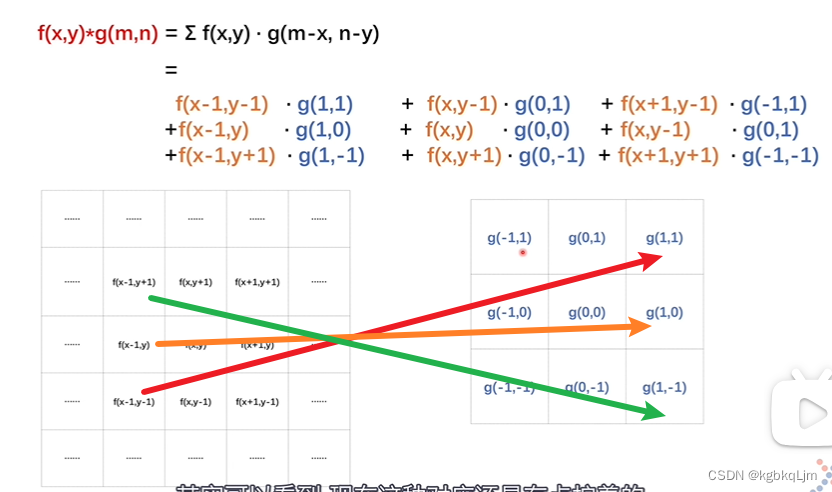

g函数旋转180°后才是卷积核
卷积核可以扣在图像上进行对应相乘并最后相加(其实省略了旋转这个步骤,但本质上仍然是卷积运算)


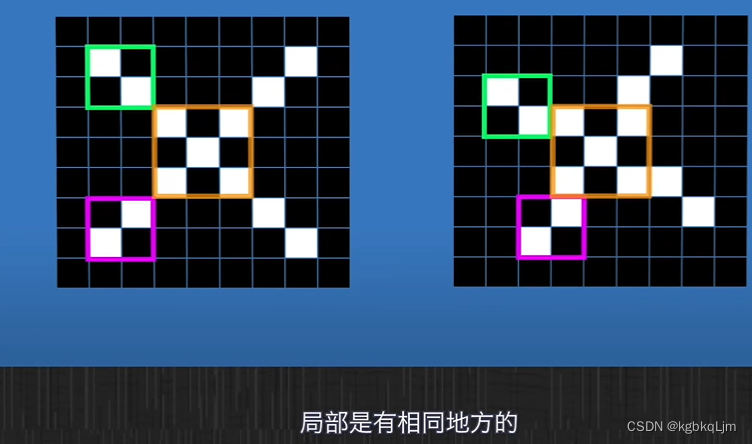
【局部性】看全局时,两个图片像素点不同,但是分别看局部,特征是一样的

当只看局部时
【不同的卷积核提取后的效果】

卷积(操作子)(从全连接到卷积)
下图说明了 为什么卷积层是特殊的全连接层:
首先将原全连接层的权重w改写为 四维的(即含二维输入和二维输出)i、j、a、b,
1.【平移不变性】然后对v进行一下重新索引(为保证其平移不变性) 丢掉i、j维度 (即在其他不关注的维度都是一样的东西)后 为va,b;
2.【局部性】然后 限制a、b在 负derta~derta的范围内(即只关注 某个位置i、j像素点 附近的东西)

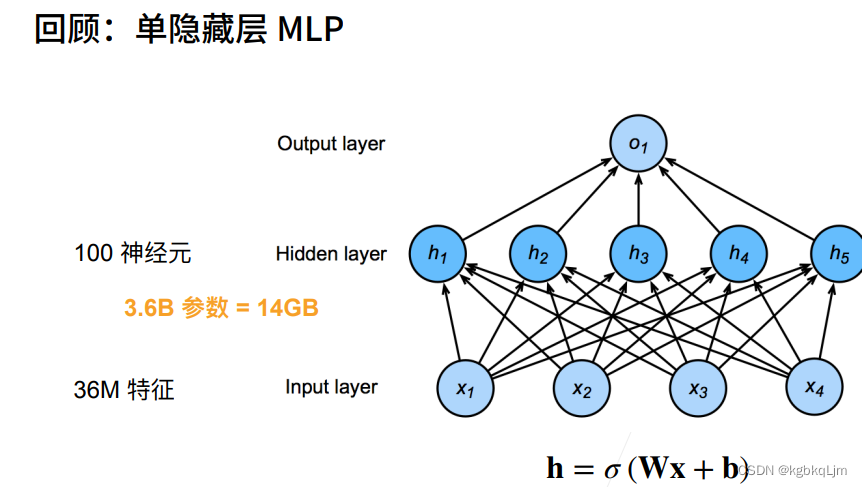
【引言】MLP处理图片分类任务存在的问题
如一个12M(即1200万)的彩色图片 有RGB三通道,则共 36M像素(每个像素点有一个值),用单隐藏层训练,在模型共有36亿个元素,远远多余所有的猫狗的数量,这样还不如直接记住所有种类

在图片中找物体的两个原则
【两个原则】
1.平移不变性:图片识别分类器在识别物体时不会因为该物体像素在图片中出现位置的不同 而改变识别结果(待识别物体出现在图片中任何位置时,应该都能准确识别才行)
2.局部性:只需要看局部信息即可,不需要看全部信息
这两个原则也启发了后续的设计
下面从全连接层出发,应用卷积(即特殊的全连接层)
重新考察全连接层
【此处用矩阵的原因】之前用全连接层时,就将二维矩阵转换成了一维向量,但此时要考察一些空间信息,因此需要用矩阵来计算。
【为何reshape为4D tensor】输入和输出都变成了二维的,权重表示使用下标,要显示输入输出的高宽,所以权重就是四维的
参数解释:(搜一下卷积的动图,原来全连接层是一个权重,现在是一个矩阵的权重)
hi,j:输出(之前学习的全连接层时 是 hi)
wi,j,k,l:权重(之前是二维,现在是四维)(之前得输入层和隐藏层是向量,所以w下标为两个。现在输入层和隐藏层变成矩阵,所以w下标是四个。)
xk,l:输入(之前学习的全连接层时是 xi)
(弹幕)Wijkl里面的kl是对应X的kl也就是输入的矩阵的元素,ij代表卷积核里面和kl相乘的那个值,因为卷积核的值不会变但是会滑动所以sigma下标是kl,实际就是滑动卷积的意思
【w下标的变换得到v】然后对w进行重新索引(即 重新排列),得到v, 因此 也会使得x的下标有点变化



平移不变性
【从图像卷积角度理解, 用卷积核去扫input图像时,卷积核的内容是不变的】
【i、j是位置,i+a、j+b是 以ij位置为参照点进行平移后得到的位置】
至此存在的问题:输入x的平移会导致v的平移(如 x 的i、j分别平移为i+a、j+b,则 识别图像的权重 v也会随之变化),但我们的目标是 x的变化不应该引起v的变化
【权重就是特征提取器,不应该随位置而发生变化】i、j应该是 图片中不同的位置索引,将v改为va,b后(即丢掉v的i、j两个维度),就不依赖于 输入x的位置i、j了
虽然下图红框是二维卷积,但是严格在数学上来说是 二维交叉相关

局部性
【从图像卷积角度理解, 用卷积核去扫input图像时,每次只关注input图像中 卷积核扫描的那一部分,而不是每次关注全部input图像】
理论上,以i、j为中心,可以平移到任意位置,但实际上 我们不应该看离i、j太远的位置(即令太远的va,b=0,即不关注了),应该只看其附近的点
即:关注的位置 即 i、j变化的位置i+a、j+b 只关注 a和b在 [-derta,+derta]的范围内(即下图橙框)
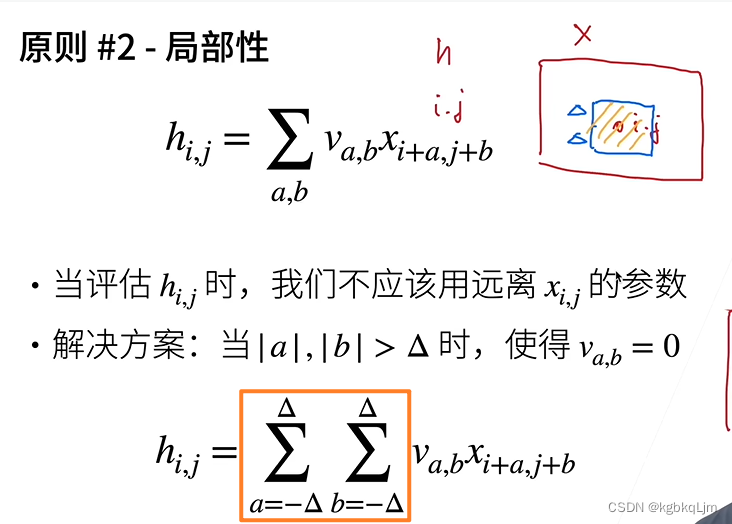
【局部性-补充】评论区推荐视频的通俗理解:
看全局时,两个图片像素点不同,但是分别看局部,特征是一样的
当只看局部时
卷积层
核矩阵(即卷积核)W和偏移b都是可以学习的参数
核矩阵(卷积核)的大小是超参数,其控制局部性

概述
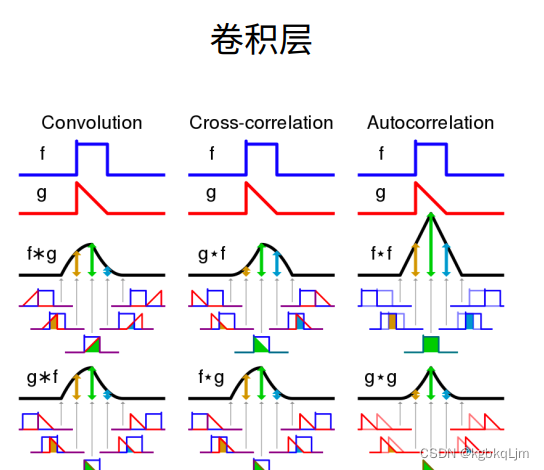
二维卷积
全程中 核是不变的(即平移不变形)
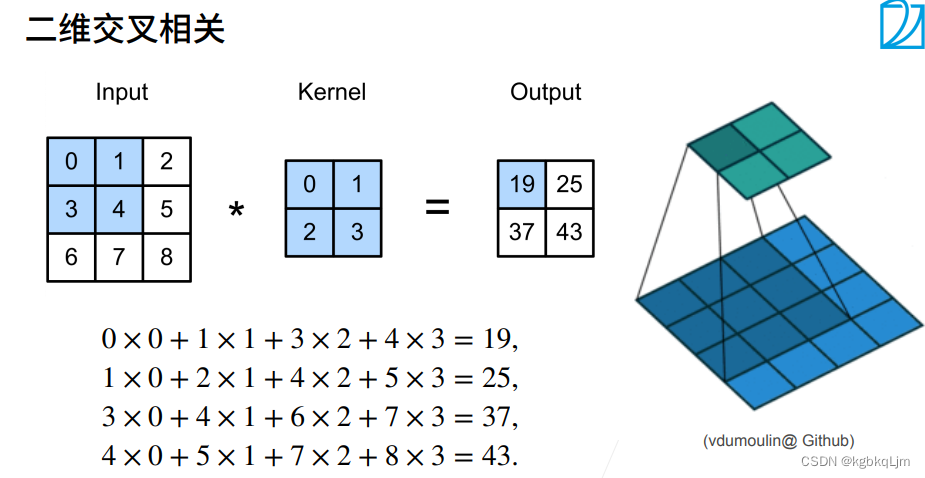
【二维卷积层】
用卷积核去扫描时,丢掉的内容就是 (kh - 1) x (kw - 1)
下图中 五角星 即为 上节定义的二维交叉相关操作子;
W和b都是可以学习的参数
【举例】
弹幕说:卷积核肯定是自己学,因为卷积核中每个元素都代表一个weight

交叉相关
交叉相关和卷积没有太多区别,唯一的区别是w角标中的a、b和-a、-b
(弹幕说:是不是说卷积时他的核需要逆时针旋转180°,相关不需要。
实际运算时反正参数推出来了,效果也达到了,所以我们就不去深究里面翻转前后代表的意义了)
实际应用中虽然说 使用的是卷积操作,但是实际上用的是交叉相关(因为 严格来说卷积 要按照下图中这么写,即 w角标为-a、-b,但 我们 从使用者的角度 并不严格)

一维和三维交叉相关
主要关注的还是二维图像

代码
互相关运算


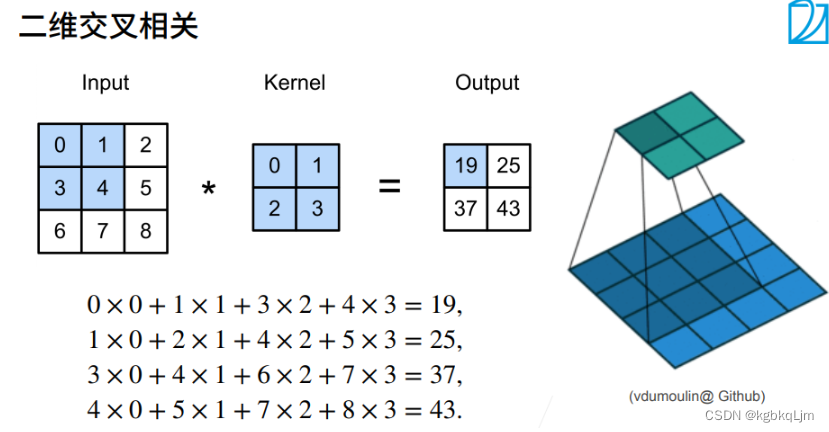
# 互相关运算
import torch
from torch import nn
from d2l import torch as d2ldef corr2d(X, K): # X 为输入,K为核矩阵"""计算二维互相关信息"""h, w = K.shape # 核矩阵的行数和列数Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1)) # 初始化输出Y的形状。X.shape[0]为输入高 for i in range(Y.shape[0]):for j in range(Y.shape[1]):Y[i, j] = (X[i:i + h, j:j + w] * K).sum() # 图片的小方块区域与卷积核做点积return Y# 验证上述二维互相关运算的输出
X = torch.tensor([[0.0,1.0,2.0],[3.0,4.0,5.0],[6.0,7.0,8.0]])
K = torch.tensor([[0.0,1.0],[2.0,3.0]])
corr2d(X,K)
二维卷积层
互相关运算,就是类似于点积,对应位置(卷积核覆盖的区域)元素相乘再相加,

【应用】检测图像颜色边缘
对于某一个图像,如果 某个像素与其相邻像素相同,则 与 [1,-1]核运算后 为0,则不是边缘; 如果某处是边缘(即 由0变为1或1变为0),则 与[1,-1]核运算后 不为0(要么是1,要么是-1)
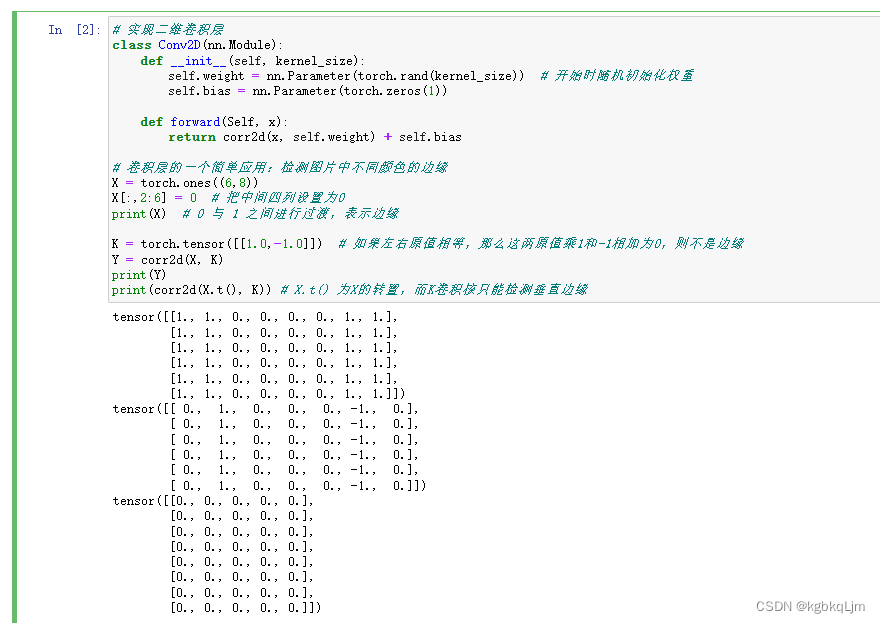
# 实现二维卷积层
class Conv2D(nn.Module):def __init__(self, kernel_size):self.weight = nn.Parameter(torch.rand(kernel_size)) # 开始时随机初始化权重self.bias = nn.Parameter(torch.zeros(1))def forward(Self, x):return corr2d(x, self.weight) + self.bias# 卷积层的一个简单应用:检测图片中不同颜色的边缘
X = torch.ones((6,8))
X[:,2:6] = 0 # 把中间四列设置为0
print(X) # 0 与 1 之间进行过渡,表示边缘K = torch.tensor([[1.0,-1.0]]) # 如果左右原值相等,那么这两原值乘1和-1相加为0,则不是边缘
Y = corr2d(X, K)
print(Y)
print(corr2d(X.t(), K)) # X.t() 为X的转置,而K卷积核只能检测垂直边缘

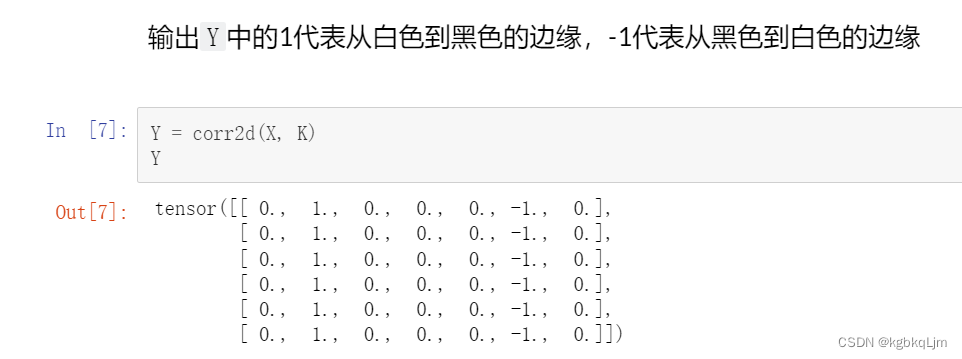

给定输入X和输出Y,学习得到卷积核K
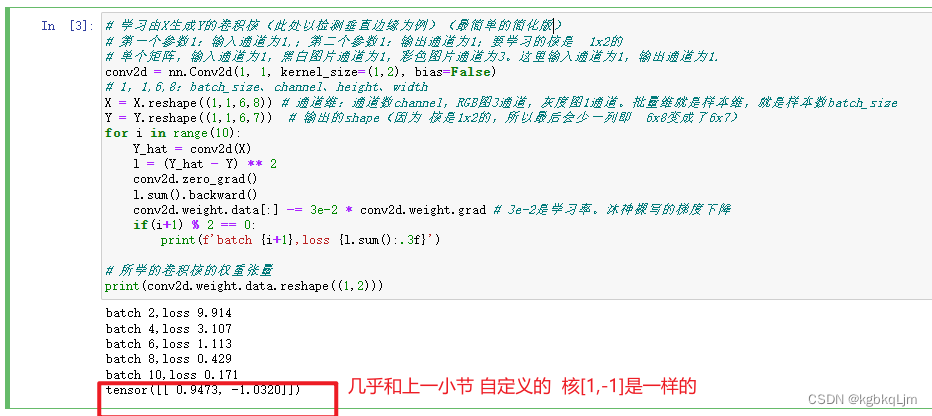
# 学习由X生成Y的卷积核(此处以检测垂直边缘为例)(最简单的简化版)
# 第一个参数1:输入通道为1,;第二个参数1:输出通道为1;要学习的核是 1x2的
# 单个矩阵,输入通道为1,黑白图片通道为1,彩色图片通道为3。这里输入通道为1,输出通道为1.
conv2d = nn.Conv2d(1, 1, kernel_size=(1,2), bias=False)
# 1,1,6,8:batch_size、channel、height、width
X = X.reshape((1,1,6,8)) # 通道维:通道数channel,RGB图3通道,灰度图1通道。批量维就是样本维,就是样本数batch_size
Y = Y.reshape((1,1,6,7)) # 输出的shape(因为 核是1x2的,所以最后会少一列即 6x8变成了6x7)
for i in range(10):Y_hat = conv2d(X)l = (Y_hat - Y) ** 2conv2d.zero_grad()l.sum().backward()conv2d.weight.data[:] -= 3e-2 * conv2d.weight.grad # 3e-2是学习率。沐神裸写的梯度下降if(i+1) % 2 == 0:print(f'batch {i+1},loss {l.sum():.3f}')# 所学的卷积核的权重张量
print(conv2d.weight.data.reshape((1,2)))


QA

17.没区别。
100个神经元的单隐藏层MLP 即有 一个输出维度为100的全连接层
只是为了说明 为什么卷积是特殊的全连接层
19.图片输入时就是一个二维的(就是个矩阵)
之前使用softmax回归时,把图片reshape成了一个一维向量
20.没听过
21.感受野即kernel的大小
这个问题类似于之前全连接层提到过的 一个很浅的很宽的全连接层的效果没有 一个 深一点且窄一点的全连接层效果好
同理对于卷积层,使用层数少且每层核大 的 效果不如 层数多且每层的核小一点 的效果好
一般用3x3或5x5
这个就是inception的设计思路

23.信号与处理中 就是那么定义的,深度学习只是拿来用用,并没纠结细节
24.不管在图片的哪个位置,核是不变的
25.只是为了讲课定义的
26.数字信号处理中 可以看看

27.抖动厉害的原因:(抖动没事,只要 呈下降趋势即可,但是一直抖不下降是有问题的)
(1)数据多样性很大,每次随机采样的数据 区别很大, 这样是没事的( 可以做平滑,好看一点)
(2)学习率很大。可以降低学习率lr (或者batch_size大一点)
不是这个意思。
全连接层最大的问题是 权重矩阵W的高(好像就是 矩阵的行数)取决于 输入的宽 。那么此时当给定的输入是 1200万像素的图片,那么 输入维度就是1200万,那么权重矩阵参数量太大 就炸掉了。
而 卷积不存在这种问题,因为卷积核大小是固定的,无论输入的大小是多大(而且实际上也不会直接丢进去一个 1200万像素的输入)
弹幕说:mlp放不下的原因是因为权重参数的矩阵过大
20-卷积层中的填充和步幅
填充和步幅
卷积核大小kernel_size、填充padding、步幅stride都是 超参数

博客:
① 奇数卷积核更容易做padding。我们假设卷积核大小为k * k,为了让卷积后的图像大小与原图一样大,根据公式可得到padding=(k-1)/2,这里的k只有在取奇数的时候,padding才能是整数,否则padding不好进行图片填充。
② k为偶数时,p为浮点数,所做的操作为一个为向上取整,填充,一个为向下取整,填充。
填充padding
【总结】通常情况下,padding的高宽是对称的,且取为核大小-1,即ph=kh-1、pw=kw-1(这个是指课件理论中的 含上下或左右的 某个方向一共填充的大小,如果 在代码中 要写为 padding=ph/2)。从而使得输出形状=输入形状
【注意ph、pw与代码中的padding】此处填充ph和pw是指 从高度方向、宽度方向 共填充了多少,如 ph=2 上下共填充了2行,相当于 代码中的padding=1。即 对于 卷积核大小为3x3的、padding=1(代码中写padding=1,课件理论中ph、pw=2,二者是二倍的关系) 进行卷积操作后,输入和输出形状相同;对于 5x5的卷积核大小、padding=2(代码中写padding=2,课件理论中ph、pw=4),输入和输出形状相同
nh和nw为输入数据的高、宽
【引言-填充】当不使用padding时,经过多层卷积后 形状会变得很小
下图中:每一层都会减4,第七层大小就变成4X4了

【正文-填充】
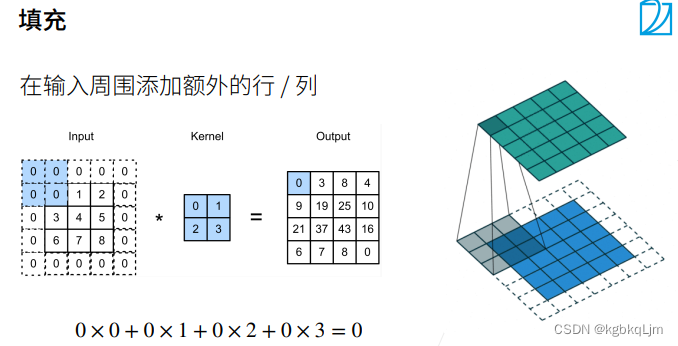
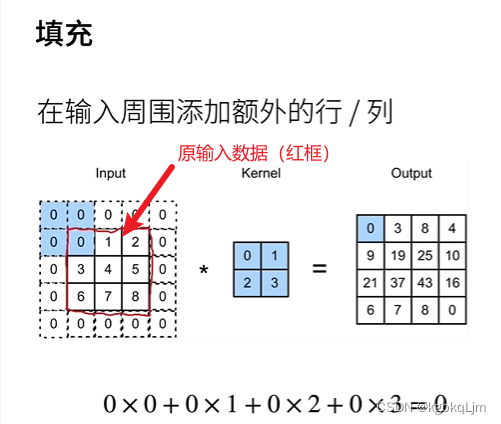
【有填充时的输出形状计算】
【注意ph、pw与代码中的padding】此处填充ph和pw是指 从高度方向、宽度方向 共填充了多少,如 ph=2 上下共填充了2行,相当于 代码中的padding=1。即 对于 卷积核大小为3x3的、padding=1 进行卷积操作后,输入和输出形状相同;对于 5x5的卷积核大小、padding=2,输入和输出形状相同
p为padding,当 按下图中通常方式取ph和pw(即ph=kh-1、pw=kw-1)时,无论核的大小如何,输出和输入的形状相同
一般来说很少用核长宽为偶数的卷积核
下图中的类似[ ] 的是向上、下取整

步幅stride
【引言-步幅】

【正文-步幅】每次移动核时,可以 一次向右和向下 移动几格
下图中第一个图的两个蓝色区域是 分别从 起点(即左上角)向右移动一次(2步幅)、向下移动一次(3步幅)。
当继续移动 剩余区域不够时,就不移动了
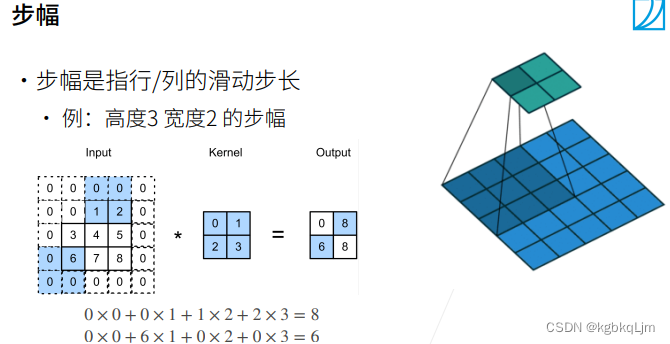
【有步幅时的输出形状计算】
根据公式,如果 stride=2,那么 输出尺寸的高宽相当于减半

类似中括号的是 floor向下取整

代码
【通常情况下都是对称的】输入的数据形状是 高宽相同的,padding是对称的,stride也是对称的
【注意ph、pw与代码中的padding】此处填充ph和pw是指 从高度方向、宽度方向 共填充了多少,如 ph=2 上下共填充了2行,相当于 代码中的padding=1。即 对于 卷积核大小为3x3的、padding=1 进行卷积操作后,输入和输出形状相同
# 在所有侧边填充1个像素
import torch
from torch import nndef comp_conv2d(conv2d, X): # conv2d 作为传参传进去,在内部使用# 在维度前面加入一个批量大小数batch_size和通道数channel(因为暂时没考虑批量大小数和通道数)X = X.reshape((1,1)+X.shape) Y = conv2d(X) # 卷积处理是一个四维的矩阵return Y.reshape(Y.shape[2:]) # 将前面两个维度拿掉# 【填充】在所有侧边分别填充1个像素
conv2d = nn.Conv2d(1,1,kernel_size=3,padding=1) # padding=1 为左右都填充一行,相当于之前讲的ph、pw=2
X = torch.rand(size=(8,8))
print(comp_conv2d(conv2d,X).shape) # torch.Size([8, 8]) 即没改变输入的形状
# 【填充】填充不同的高度和宽度(核的形状为5x3, 填充时上下分别填充2行、左右分别填充1列)
conv2d = nn.Conv2d(1,1,kernel_size=(5,3),padding=(2,1))
print(comp_conv2d(conv2d,X).shape) # torch.Size([8, 8]) 即没改变输入的形状# 【填充+步幅】将高度和宽度的步幅设置为2
conv2d = nn.Conv2d(1,1,kernel_size=3,padding=1,stride=2)
print(comp_conv2d(conv2d,X).shape) # torch.Size([4, 4])。
# 因为步幅sh、sw为2,可以被输入的高、宽整除,因此输出为(nh/sh) x (nw/sw)# 【填充+步幅】一个稍微复杂的例子
conv2d = nn.Conv2d(1,1,kernel_size=(3,5),padding=(0,1),stride=(3,4))
print(comp_conv2d(conv2d,X).shape) # torch.Size([2, 2]) 。 套公式计算




QA

-
ppt错了,55层
重要程度:核大小> 填充通常取默认的、步幅取值取决于你要把你的模型大小控制在什么程度
卷积核大小kernel_size:
填充padding:通常ph和pw取值为 卷积核大小-1 ,从而实现 卷积核不改变输入形状大小(注意 如果是代码中 padding=1 相当于课件中的ph、pw=2)
步幅stride:通常padding=1(因为如果每层都减半,经过几个卷积层后 图片就很小 几乎没了 这样就 做不了深的神经网络了,因此减半是个别情况)。 不为1时 是因为计算量太大了,此时通常步幅取2。步幅越大,计算量越小;步幅越小,模型所需层数就很大(因为一般是 想将一个很大的输入图片 变成一个很小的)
3.是的。因为padding(课件理论中)=kernel-1,而padding是分在图片上下的,kernel为基数,padding就可以对半分。
注意 课件理论中的 ph、pw 除以2才为代码中的 padding
当然,也可以取偶数
4.看第二个问题
减半是很少的情况,大多数情况是不变的
padding、stride、通道数,这些是神经网络架构设计的一部分,当用不同的神经网络时 一般都会告诉你这些参数如何设定

6.一般来说很少会自己纯手写神经网络, 如用ResNet(kaiming大神的残差神经网络)就够了,其也分很多系列。除非你的输入是非常不一样的情况,如 是20x1000,很扁的这种,可能需要自己设计神经网络,否则一般用经典的即可 或 在经典的基础上做调整。
即便自己设计神经网络,也是参照经典神经网络的基础上
7.回看代码
8.回看代码
9.不存在这种情况

虽然单独看3x3很小,但是 如果神经网络很深时, 较深的层中的每个元素 能看到 足够大的图片信息
高层会看到低层所看到信息总和
对于后面比较深的卷积层中的 1x1、3x3这种,其实 每个元素对应的是 较浅层中很大的图片范围的,看到的信息并不小

11.NAS(Neural Network Architecture Search),也是自动机器学习的一部分
弹幕说:autodl和automl,计算成本太高,不是一般人研究的起的
(1)方式一:设计很多神经网络结构,从中选择效果最好的
12.从信息论的角度来说,特征信息肯定会丢失的
ML本质是一个极端的压缩算法:给你一个图片,最后得到一个类别、有语义信息的数值。 即把 比较原始的计算机能理解的像素信息、文字字符串的信息压缩到人能理解的 语义空间中
13.有,但是成本极大(沐神的一个实验跑了100w美金)
14.同13
15.是可以人为控制的
16.从理论上来说,大概是:三个3x3卷积核的效果是可以用2个5x5卷积核来替代的;10层3x3卷积的效果可以等效成5或6层 的5x5的卷积,
但是,3x3卷积更快,(涉及计算复杂度、成本方面的问题、更“贵”)

17.可以这样用。但是一般来说,简单高效易懂的更容易被人记住,即类似 都用比较简单的核。
太复杂的 可以不容易被人理解
18.后面会讲,不同的卷积层 可以看不同的纹理特征
DL不是有钱人的游戏。
如果不用DL:
1、用人,机器成本可能会低点,可能效果差,就需要更多的调参,即人力成本。
2、其次数据成本很大,数据很贵
DL使用GPU的算力来替代 人力成本和数据成本, 虽然计算算力变高。
NAS现在是有钱人的游戏,但是任何科技都是从很贵到很便宜的过程(如当年的磁盘计算机也很贵)
21-卷积层里的多输入和多输出
输出通道是当前卷积层的超参数, 输入通道是 上一个卷积层的 超参数(即上一个卷积层的输出通道)

多输入输出通道
引言
之前Fashion mnist是单通道(只有一个灰)


正文-多个输入通道
【多个输入通道】
如下图,通道0的数据和通道0的卷积核做点积运算,同理通道1,最后将两个通道的结果相加
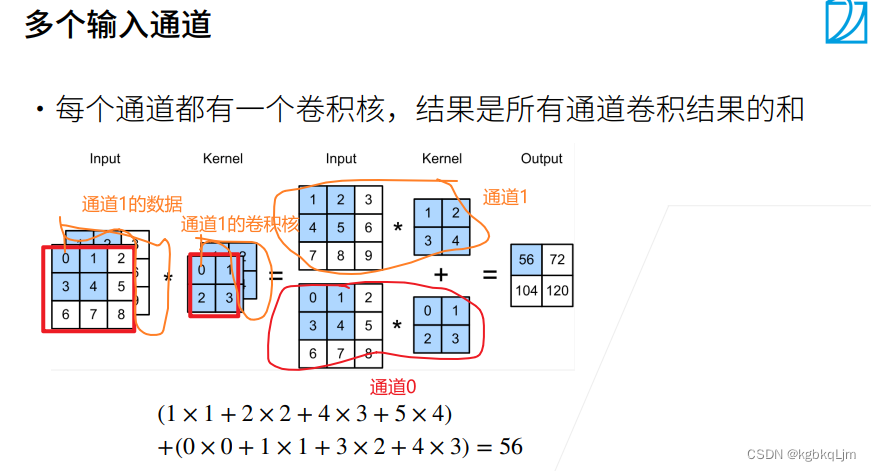
现在假定输入数据X是三维的tensor,即三个通道,则卷积核也变成了三维的(与输入数据维度相同);每个通道都有一个 偏移(即长为ci的向量),此处只是没写
i:input
输出是单通道的,因为不管输入有多少个通道,都是最后按通道相加

正文-多个输出通道
【多个输出通道】 多个输入通道和多个输出通道其实是没有相关性的,可以分别设置
【个人理解,暂时没问题】输出通道数=卷积核个数,即下图中co
对于每个输出的通道,都有一个自己的三维卷积核,
co:output channel
弹幕说:这里等于就是利用多个卷积核,分别对输入进行上一页PPT的卷积操作,最后将结果分通道叠在一起。ci个通道,每个通道co种卷积核,共有ci*co种卷积核。
老师说:对每一个输入(下图中第一个红框),把它对应的一个输出通道的核拿出来(第二个红框),就会得到一个对应的输出通道(第三个红框),对每一个输出通道一一这样运算,最后将结果concat起来,得到输出Y
Yi,:,:输出里面的第i个通道

【多个输入和多个输出通道的意义】
多输出通道:每个输出通道可以取识别一种模式(如不同的卷积核 可以提取不同 角度的特征,如 边缘、锐化、颜色、纹理等),通过学习不同的卷积核权重 来匹配不同的模式,如下图中有6个输出通道
多输入通道:假设将上一层 得到的六个输出通道的结果 丢给下一层,将每个通道的到的结果组合起来(如 加权相加),得到组合的模式识别。这是对于相邻的两层,从整体的深度网络来看,浅层、下面的层识别 具体细节特征如 边缘特征、纹理等,
深层次的层可以将之前浅层得到的 分别的特征(模式)进行组合(如 将 胡须、眼睛等 组合起来 得到一个猫头,最深层、最高层 可能得到一整只猫)

1x1卷积层
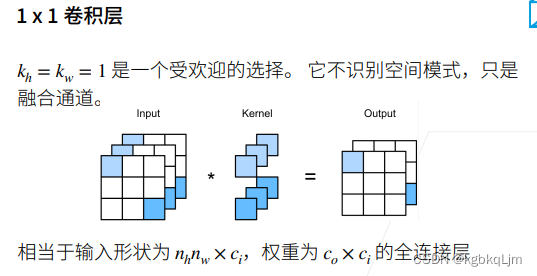
【1x1卷积层可以认为是卷积层,也可以等价认为是一个全连接层】
卷积核的高宽均为1,每次只看一个像素(即不看 周围空间的特征,即其不识别空间信息,不看当前这个像素与周围其他像素的关系)
本质上等价于一个 形状为nhnw x ci、权重为co x ci x 1 x 1的全连接层
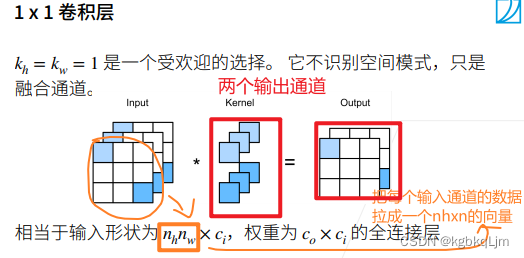
输出为0的通道,输出为1的通道
弹幕说:
1.其实就是对input里的3个矩阵做全连接,这里是做了两次不同权重的全连接
2. 3个输入通道经过一个核得到一个输出通道,这里有两个核,所以得到两个输出通道
3. 对的,这里理解为两组核或者两套核比较好一些,一组核包括三个核
最通用情况下的二维卷积层
【偏差B的理解(弹幕说)】
每一个卷积核都对应一个单独的偏差
pytorch的官方文档,bias是和卷积核个数相同
其实就是Co组核,每组核有Ci个偏差
这里+B是用了广播机制(不确定)
【计算复杂度的理解】
可以这么理解,输出层共有CoMhMw个元素,每个元素都是size大小为CiKhKw的卷积核计算得到的

代码
多输入通道互相关计算
【zip的作用】
弹幕:
zip(X, K)函数可以将X和K的每个通道配对,返回一个可迭代对象,其中每个元素是一个(x, k)的元组,表示一个输入通道和一个卷积核。
zip函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。

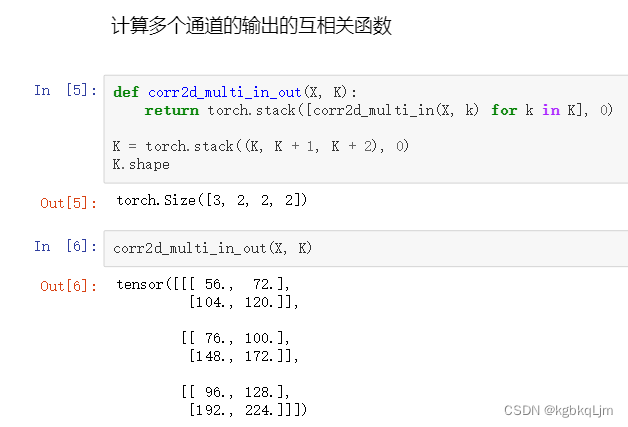
多输出通道的互相关计算
torch.stack():沿着一个新维度对输入张量序列进行连接,序列中所有的张量都应该为相同形状
下图中即在dim=0这个维度上 进行堆叠
三个卷积核,每个卷积核有两个通道,每个通道是2*2的矩阵
# 多输入通道互相关运算
import torch
from d2l import torch as d2l
from torch import nn# 多通道输入时的互相关运算
def corr2d_multi_in(X,K): # 此处假设X和K都是3D的return sum(d2l.corr2d(x,k) for x,k in zip(X,K)) # X,K为3通道矩阵,for使得对最外面通道进行遍历
# zip(X, K)函数可以将X和K的每个通道配对,返回一个可迭代对象,其中每个元素是一个(x, k)的元组,表示一个输入通道和一个卷积核。X = torch.tensor([[[0.0,1.0,2.0],[3.0,4.0,5.0],[6.0,7.0,8.0]],[[1.0,2.0,3.0],[4.0,5.0,6.0],[7.0,8.0,9.0]]])
K = torch.tensor([[[0.0,1.0],[2.0,3.0]],[[1.0,2.0],[3.0,4.0]]])
print(corr2d_multi_in(X,K))# 多输出通道运算
def corr2d_multi_in_out(X,K): # X为3通道矩阵;K为4通道矩阵,最外面维为输出通道 # 弹幕说:就是从4D的K中拿出一个3D的k进行上一步操作# 大K中每个小k是一个3D的Tensor。0表示stack堆叠函数里面在0这个维度堆叠。 return torch.stack([corr2d_multi_in(X,k) for k in K],0) print(K.shape)
print((K+1).shape)
print((K+2).shape)
print("K:",K)
print(K+1)
K = torch.stack((K, K+1, K+2),0) # 原来的K是3D的,现在使用stack创建一个 三输出通道的新K
print(K.shape) # torch.Size([3, 2, 2, 2]) : 输出通道为3,输入通道为2,h、w分别为2
print("新的K:",K)
print(corr2d_multi_in_out(X,K))

1x1卷积
验证一下 1x1的卷积 等价于 一个全连接

# 【定义一个用全连接实现 1x1的 多输入多输出通道 的互相关操作】1×1卷积的多输入、多输出通道运算
def corr2d_multi_in_out_1x1(X,K):c_i, h, w = X.shape # 输入的通道数、宽、高c_o = K.shape[0] # 输出的通道数X = X.reshape((c_i, h * w)) # 拉平操作(把高宽拉成一个向量),每一行表示一个通道的特征。此时X是一个矩阵K = K.reshape((c_o,c_i)) # 原K完整是 co x ci x 1 x 1,去掉1x1后 ,K也是一个矩阵Y = torch.matmul(K,X) return Y.reshape((c_o, h, w))X = torch.normal(0,1,(3,3,3)) # norm函数生成0到1之间的(3,3,3)矩阵
K = torch.normal(0,1,(2,3,1,1)) # 输出通道是2,输入通道是3,核是1X1Y1 = corr2d_multi_in_out_1x1(X,K)
Y2 = corr2d_multi_in_out(X,K)
assert float(torch.abs(Y1-Y2).sum()) < 1e-6
print(float(torch.abs(Y1-Y2).sum()))

QA

20.输入通道基本是固定的, 因为输入是给定的。输出通道理论上可以设为任意值(虽然实际上肯定不能随便设)
【直观理解】一般来说,输入和输出的数据 高宽不变时, 输出通道也会设为和输入通道一致。
但是如果输出的数据 高宽都减半了,那么 输出通道数 会 设为 输入通道数的二倍(即 把空间信息压缩了, 并把提取出的信息在更多的通道上存储起来)
21.不会影响模型的精度、模型的性能(当然 很多0会影响计算性能,计算变慢了)
22.每个通道上的卷积核是不一样的;(一般来说)不同通道的卷积核大小是一样的,这样方便计算、计算上的效率更高(当然理论上也可以让不同通道的卷积核大小不同)
23.偏移的影响并不是很大(况且后续还有BN的存在),而且几乎不会对计算性能产生影响
24.核的参数是学习出来的

不是的。有深度图信息后要使用三维卷积,此时输入数据变为 4D的(即 输入通道 x 深度 x 宽 x 高),核变为5D的,输出为4D的
26.对于多输入通道,一个输入通道有一个卷积核 得到一个计算结果, 多个输入通道计算结果会累加。
多输出通道数 取决于co,与 多输入通道数的独立的,
三维卷积核是五维的, 含 输入通道、输出通道、高、宽、深度信息
27.信号处理区分高低频,图像里面好像不太注重这个。 数据丢进去 网络自己学习
28.卷积核的高宽均为1,每次只看一个像素(即不看 周围空间的特征,即其不识别空间信息,不看当前这个像素与周围其他像素的关系)
29.是的。这个就是mobile net(音译,移动端用的卷积神经网络,计算复杂度很低)

30.卷积有位置信息,而且对位置很敏感。
输出数据中第i行第j列的元素 就是对应 输入数据中第i行第j列元素附近那一块的信息。
因此 卷积输出的那些信息、位置信息 是 输出的元素在矩阵中的位置决定的,后续会讲基于 池化层 使得不对位置那么敏感。
31.通道之间是不共享参数的,我们希望每个通道能学习到不同的东西、模式。
弹幕说:同一卷积层共享参数,通道之间的不共享
卷积层参数共享指的是整个图像用同一个卷积核来扫描,和全连接网络相比共享了参数。
可以把 计算复杂度中的 mh和mw用 含nh nw去替换,因为 mh mw就是通过nh nw计算出来的。
只是用mh、mw表示 会简单一点,且可以直观看出 计算复杂度与 输出数据中高宽的关系

33.同32
34.我们无法控制每个卷积核究竟能提取到什么信息,核参数都是学习出来的。
当然 一般需要多次卷积 即深度卷积神经网络。
35.需要save和load
老师一般用 vim + VSCode
弹幕说:Vscode安装jupyterlab插件,简直不要太爽

36.正确。
37.feature map就是卷积的输出
38.输入通道不是动态变化的。
39.奇数在padding时方便一点。
40.rgbd可以用3D卷积,也可以用2D卷积(每个深度做一个2D卷积,然后用RNN或直接concat起来)
本次课程不会讲3D卷积,其在视频中用的多,其效果稍微比2D卷积好一点点、但是计算复杂度高很多
这篇关于学习笔记-李沐动手学深度学习(七)(19-21,卷积层、填充padding、步幅stride、多输入多输出通道)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






