李沐专题

李沐讲座:大语言模型的实践经验和未来预测 | 上海交大
本文简介 本博客记录了李沐关于语言模型与职业生涯分享的精彩讲座,涵盖了大语言模型的核心要素、工程实践中的挑战,以及演讲者个人职业生涯中的心得体会。 李沐简介 李沐(Mu Li)是一位在人工智能与深度学习领域具有广泛影响力的计算机科学家。他拥有丰富的学术背景和产业经验,曾在百度和Amazon等知名科技公司工作,并有两次成功的创业经历。李沐以其在深度学习、分布式系统以及大规模机器学习方面的杰出贡

李沐--动手学深度学习 ResNet
1.理论 2.残差块 import torchfrom torch import nnfrom torch.nn import functional as Ffrom d2l import torch as d2l#ResNet沿用了VGG完整的3*3卷积层设计.残差块的实现如下:#此代码生成两种类型的网络:#一种是当use_1x1conv=F

李沐第十八课《seq2seq》
这节课主要讲了两个东西,一个是seq2seq(编码器-解码器),一个是attention机制 seq2seq 当输入和输出都不是定长的时候,比如翻译等,我们可以采用编码器-解码器机制,编码器对应输入序列,解码器对应输出序列。 1,编码器的作用是将一个不定长的输入序列转换为一个定长的背景向量c 2,编码器最终输出的背景向量c,这个背景向量c编码了输入序列X1,X2,X3..XT的信息,

李沐第十六课《词向量word2vec》
首先word2vec只是一个工具,然后word2vec主要包含两个模型:skip-gram(跳字模型)和CBOW模型(continuous bag of words 连续词袋模型),然后还包括两种高效的训练方法:负采样(negative sampling)和层序softmax(hierarchical softmax)。word2vec可以较好的表达不同词之间的相似和类比关系。 sk

李沐69_BERT训练集——自学笔记
NLP里的迁移学习 1.使用预训练好的模型来抽取词、句子的特征,例如word2vec或语言模型 2.不更新预训练好的模型 3.需要构建新的网络来抓取新任务需要的信息:word2vec忽略了时序信息,语言模型只看了一个方向 BERT的动机 1.基于微调的NLP模型 2.预训练的模型抽取了足够多的信息 3.新的任务只需要增加一个简单的输出层 对输入的修改 1.每个样本是一个句子对

李沐68_Transformer架构——自学笔记
Transformer架构 1.基于编码器-解码器来处理序列对 2.跟使用注意力的seq2seq不同,Transformer是纯基于注意力 多头注意力 1.对同一key,value,query。希望抽取不同的信息:短距离关系和长距离关系 2.多头注意力使用h个独立的注意力池化:合并各个头head输出得到最终输出。 有掩码的多头注意力 1.解码器对序列中一个元素输出时,不应该考虑改元素

李沐64_注意力机制——自学笔记
注意力机制 1.卷积、全连接和池化层都只考虑不随意线索 2.注意力机制则显示的考虑随意线索 (1)随意线索倍称之为查询(query) (2)每个输入是一个值value,和不随意线索key的对 (3)通过注意力池化层来有偏向性的选择某些输入 总结 注意力机制中,通过query(随意线索)和key(不随意线索)来有偏向性的选择输入 代码实现:注意力汇聚:Nadaraya-Watson 核

李沐57_长短期记忆网络LSTM——自学笔记
LSTM 1.忘记门:将值朝着0减少 2.输入门:决定不是忽略掉输入数据 3.输出门:决定是不是使用隐状态 !pip install --upgrade d2l==0.17.5 #d2l需要更新 首先加载时光机器数据集。 import torchfrom torch import nnfrom d2l import torch as d2lbatch_size, num_ste

李沐56_门控循环单元——自学笔记
关注每一个序列 1.不是每个观察值都是同等重要 2.想只记住的观察需要:能关注的机制(更新门 update gate)、能遗忘的机制(重置门 reset gate) !pip install --upgrade d2l==0.17.5 #d2l需要更新 import torchfrom torch import nnfrom d2l import torch as d2lbatch

李沐62_序列到序列学习seq2seq——自学笔记
"英-法”数据集来训练这个机器翻译模型。 !pip install --upgrade d2l==0.17.5 #d2l需要更新 import collectionsimport mathimport torchfrom torch import nnfrom d2l import torch as d2l 循环神经网络编码器。 我们使用了嵌入层(embedding laye

李沐45_SSD实现——自学笔记
主体思路: 1.生成一堆锚框 2.根据真实标签为每个锚框打标(类别、偏移、mask) 3.模型为每个锚框做一个预测(类别、偏移) 4.计算上述二者的差异损失,以更新模型weights 先读取一张图像。 它的高度和宽度分别为561和728像素。 %matplotlib inlineimport torchfrom d2l import torch as d2limg = d2l.plt.im

李沐-19 卷积层【动手学深度学习v2】
记录下关于权重下标变换的理解: 从原来的Wi,j到Wi,j,k,l是从二维到四维的过程,如下图所示 对全连接层使用平移不变性(如:卷积核在移动过程是不变的)和局部性(如:卷积核有一定大小)得到卷积层,这是卷积层的引入,下方Vi,j,a,b--->Va,b表示了平移不变性,给a,b限制在||内保证了局部性:

李沐29_残差网络ResNet——自学笔记
残差网络 残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。 残差块 串联一个层改变函数类,我们希望扩大函数类,残差块加入快速通道来得到f(x)=x+g(x)的结果 ResNet块 1.高宽减半的ResNet块(步幅2) 2.后接多个高宽不变的ResNet块 ResNet架构 1.类似VGG和GoogLeNet总体架构 2.但替换成ResNet块 总结

47 转置卷积【李沐动手学深度学习v2课程笔记】
1. 转置卷积 卷积层和汇聚层通常会减少下采样输入图像的空间维度(高和宽),卷积通常来说不会增大输入的高和宽,要么保持高和宽不变,要么会将高宽减半,很少会有卷积将高宽变大的。可以通过 padding 来增加高和宽,但是如果 padding 得比较多的话,因为填充的都是 0 ,所以最终的结果也是 0 ,因此无法有效地利用 padding 来增加高宽。 如果输入和输出图像的空间维度相同,会便
自定义层与自定义块(李沐代码解析)
沐神文章与代码链接: https://zh-v2.d2l.ai/chapter_deep-learning-computation/model-construction.html#id3 1.块是什么: 一个“块”可能指的是一系列层的组合 2.块的功能: 1. 将输入数据作为其前向传播函数的参数。2. 通过前向传播函数来生成输出。请注意,输出的形状可能与输入的形状不同。例如,我们上面

AI论文精读(李沐) - AlexNet
文章目录 如何读论文论文精读AlexNet摘要1.Introduction2.The Dataset3.The Architecture3.1 ReLU Nonlinearity3.2 Training on Multiple GPUs 7. Discussion 如何读论文 先读标题,摘要,结论 然后读方法,实验 论文精读AlexNet 摘要 我们训练了一个大型深度卷积
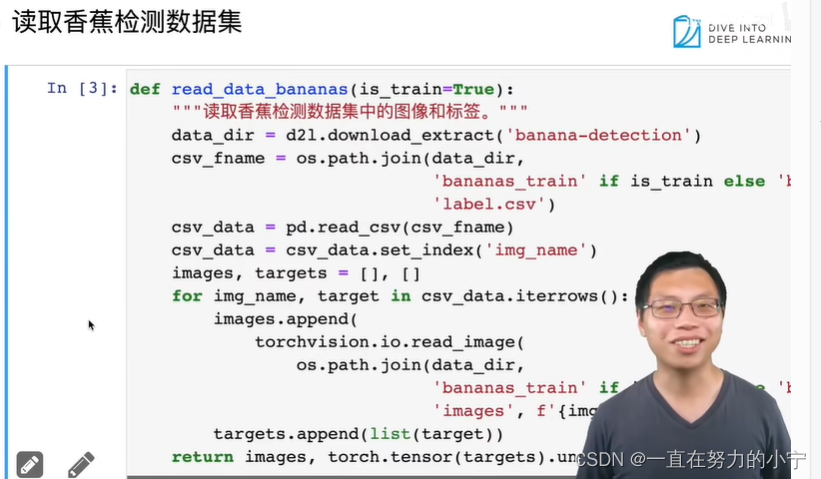
41 物体检测和目标检测数据集【李沐动手学深度学习v2课程笔记】
目录 1. 物体检测 2. 边缘框实现 3.数据集 4. 小结 1. 物体检测 2. 边缘框实现 %matplotlib inlineimport torchfrom d2l import torch as d2ld2l.set_figsize()img = d2l.plt.imread('../img/catdog.jpg')d2l.plt.imsh
【李沐论文精读】CLIP改进工作串讲精读
参考:CLIP改进工作串讲(上)、CLIP改进工作串讲(下)、李沐精读系列、CLIP 改进工作串讲(上)笔记 由于是论文串讲,所以每个链接放在每一个小节里。 CLIP的应用如下: 回顾: CLIP:CLIP就是用对比学习的方式去训练一个视觉语言的多模态模型。训练方式:给定一个图像文本对,图像通过图像编码器,文本通过文本编码器后得到一系列图像文本的特征

【李沐论文精读】GPT、GPT-2和GPT-3论文精读
论文: GPT:Improving Language Understanding by Generative Pre-Training GTP-2:Language Models are Unsupervised Multitask Learners GPT-3:Language Models are Few-Shot Learners 参考:GP
27 含并行连结的网络 GoogLeNet / Inception V3【李沐动手学深度学习v2】
目录 1. GoogLeNet 2. 代码 2.1 Inception 2.2 GoogLeNet模型 2.3 训练模型 3. 小结 1. GoogLeNet 白色框:用来改变通道数 蓝色框:用来抽取信息 2. 代码 2.1 Inception 如图所示,Inception块由四条并行路径组成。 前三条

李沐老师 PyTorch版——线性回归 + 基础优化算法(1)
文章目录 前言08 线性回归 + 基础优化算法torch.normal 正太分布torch.arangetorch.randntorch.matmulplt.scatter linear-regression-scratch.ipynb生成随机样本定义模型定义损失函数定义优化算法定义训练 前言 在李老师的《动手学深度学习》系列课程的学习过程中,李老师深入浅出地介绍了不少实打
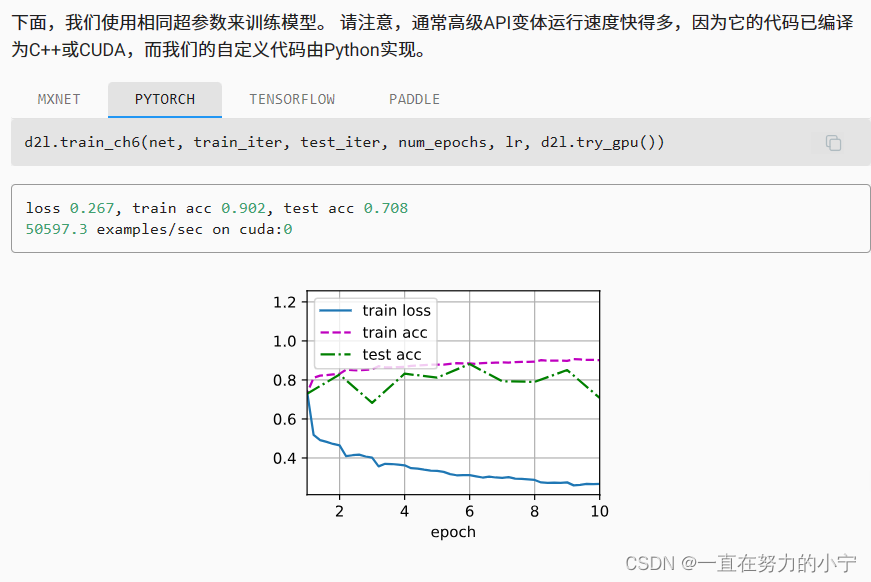
28 批量归一化【李沐动手学深度学习v2课程笔记】(备注:这一节讲的很迷惑,很乱)
目录 1.批量归一化 1.1训练神经网络时出现的挑战 1.2核心思想 1.3原理 2.批量规范化层 2.1 全连接层 2.2 卷积层 2.3 总结 3. 代码实现 4. 使用批量规范化层的LeNet 5. 简明实现 1.批量归一化 现在主流的卷积神经网络几乎都使用了批量归一化 批量归一化是一种流行且有效的技术,它可以持续加速深层网络的收敛速度 1.1训练
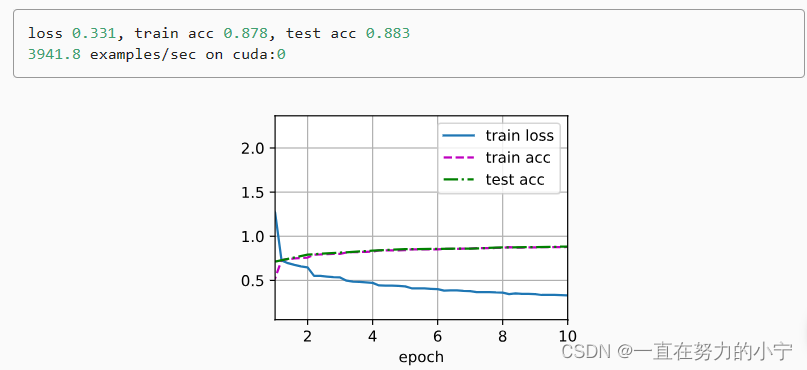
24 深度卷积神经网络 AlexNet【李沐动手学深度学习v2课程笔记】(备注:含AlexNet和LeNet对比)
目录 1. 深度学习机器学习的发展 1.1 核方法 1.2 几何学 1.3 特征工程 opencv 1.4 Hardware 2. AlexNet 3. 代码 1. 深度学习机器学习的发展 1.1 核方法 2001 Learning with Kernels 核方法 (机器学习) 特征提取、选择核函数来计算相似性、凸优化问题、漂亮的定理 1.2 几何学
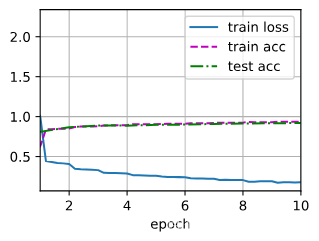
25 使用块的网络 VGG【李沐动手学深度学习v2课程笔记】
目录 1. VGG块 2. VGG网络 3. 训练模型 4. 小结 虽然AlexNet证明深层神经网络卓有成效,但它没有提供一个通用的模板来指导后续的研究人员设计新的网络。 与芯片设计中工程师从放置晶体管到逻辑元件再到逻辑块的过程类似,神经网络架构的设计也逐渐变得更加抽象。研究人员开始从单个神经元的角度思考问题,发展到整个层,现在又转向块,重复层的模式。 使用块的想法首先出现在

19 卷积层【李沐动手学深度学习v2课程笔记】
目录 1. 从全连接到卷积 2. 卷积层 3. 图像卷积代码 3.1 互相关运算 3.2 实现二维卷积层 3.3 图像中目标的边缘检测 3.4 学习卷积核 4. 小结 1. 从全连接到卷积 在欧几里得几何中,平移是一种几何变换,表示把一幅图像或一个空间中的每一个点在相同方向移动相同距离。比如对图像分类任务来说,图像中的目标不管被移动到图片的哪个位置,
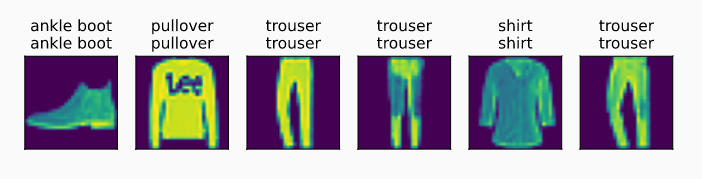
【李沐】动手学习ai思路softmax回归实现
来源:https://www.cnblogs.com/blzm742624643/p/15079086.html 一、从零开始实现 1.1 首先引入Fashion-MNIST数据集 1 import torch2 from IPython import display3 from d2l import torch as d2l4 5 batch_size = 2566 tr