本文主要是介绍Python爬虫练习:并尝试将数据写入txt文本,execl表格,mysql数据库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
该文章只供技术学习使用.
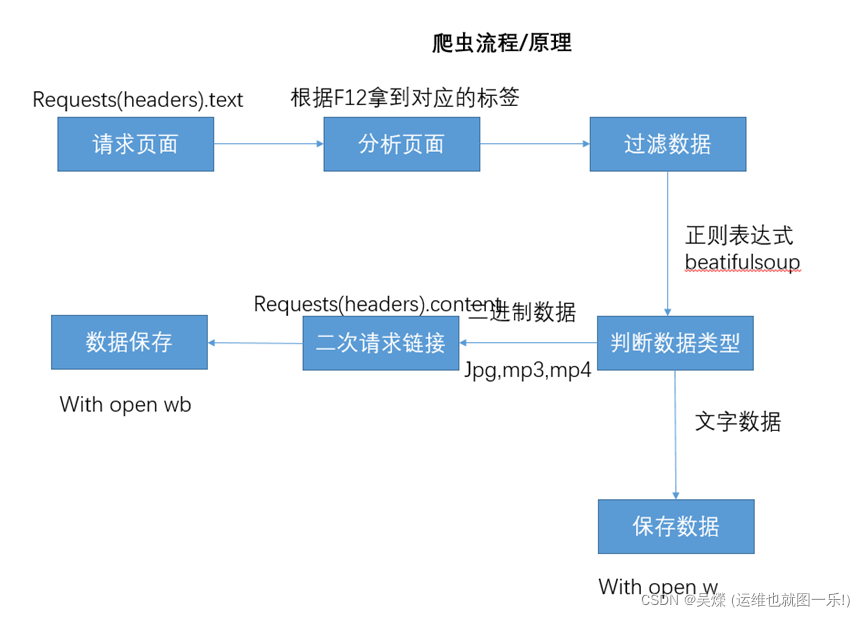
爬虫流程图:
爬虫代码:
# -*-coding:utf-8 -*-
# 爬虫模块练习: 并尝试将数据写入txt文本,execl表格,mysql数据库中,
import requests
import pymysql
import xlwt
import redef data_list(url):headers = { # 浏览器中响应头获取'Cookie': 'aliyungf_tc=018d0cffa99caeaf6a43b05c1ca2a035e271e2dfa5ab484e9f7d4c99b025ef02; ''acw_tc=b65cfd4316487269571516221e46be5fe70272c16e4ba909e68ee7d1b13887; ''acw_sc__v2=624593ad266cf74ca4a2d299d6a6d6da9363f4fd; HTTP_REFERER=book.km.com ', 'Referer': 'http://book.km.com/boy.html','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/99.0.4844.74 Safari/537.36 Edg/99.0.1150.55 '}repose = requests.get(url, headers=headers).textparroe = re.compile(r'<h1 class="fontSize17andHei" title="(.*?)">')book_tile = parroe.findall(repose) # 拿到书名author_list = [] # 存储作者名author_name1 = re.findall(r'<span class="fontSize14andsHui">(.*?)</span>', repose)for item in author_name1:parroe1 = re.compile(r'<a.*>(.*?)</a>')author_name2 = parroe1.findall(item)author_name2 = str(author_name2)author_name2 = re.sub('[\[\]\']', '', author_name2)author_list.append(author_name2)parroe2 = re.compile(r'<span class="fontSize14andHui">(.*?)</span>')novel_type1 = parroe2.findall(repose)novel_type = [] # 存储小说类型for item in novel_type1:parroe3 = re.compile(r'<a.*?>(.*?)</a>')novel_type2 = parroe3.findall(item)novel_type.append(novel_type2[0])parroe4 = re.compile(r'<span class="fontSize14andHui">(.*?)</span></div>')text = parroe4.findall(repose)novel_text = [] # 拿到周点击,字数,更新日期,里面是三个元素组成的列表.for item in text:text1 = re.findall(r'<span>(.*?)</span>', item)date_text = text1[-1]date_time = re.findall(r'日期:<font class="fontSize14andChen"><font color=".*">(.*?)</font></font>', date_text)novel_text.append([text1[1], text1[3], date_time[0]])book2 = [] # 将上面的全部数据封装到一个大的列表中,for x in range(0, len(book_tile)):book = []book.append(book_tile[x])book.append(author_list[x])book.append(novel_type[x])book.append(novel_text[x][0])book.append(novel_text[x][1])book.append(novel_text[x][2])book2.append(tuple(book))return book2def save_text(book2):try:with open('novel.txt', 'w', encoding="UTF-8") as text:h1 = ['书名', '作者', '类型', '周点击', '字数', '更新时间']for x in h1:text.write(x + "-------------")text.write("\n")for i in range(0, 30):for x in range(0, 6):text.write(book2[i][x] + "---")text.write("\n")print("写入文本中执行成功!")except BaseException:print("写入文本中执行失败!")# 写入execl中
def save_book_execl(book2):try:book_text = xlwt.Workbook(encoding='utf-8', style_compression=0)sheet = book_text.add_sheet('小说', cell_overwrite_ok=True)col = ('小说名', '作者', '类型', '周点击', '字数', '更新日期')for i in range(0, len(col)):sheet.write(0, i, col[i])for i in range(0, 30):for z in range(0, len(col)):sheet.write(i + 1, z, book2[i][z])savepath = 'D:/酷狗音乐/novel.xls'book_text.save(savepath)print("写入execl中执行成功!")except BaseException:print("写入execl中执行失败!")# 写入数据库
def save_mysql(book2):try:# 链接数据库conn = pymysql.connect(host='localhost', user='root', password='Nebula@123', db='python', port=3306,charset='utf8')# 创建游标:cur = conn.cursor()# #创建表:# sql_table="CREATE TABLE xiaoshuo(id int(8) not null auto_increment primary key,book_name VARCHAR(100),book_author " \# "VARCHAR(100),boook_type VARCHAR(100),clik VARCHAR(100),number VARCHAR(100),date VARCHAR(100) ) "### cur.execute(sql_table) #执行一个数据库查询和命令# conn.commit() #提交但前事物(写入数据时也会用到)# 将数据写入数据库:for i in range(0, 30):into = "INSERT INTO xiaoshuo(book_name,book_author,boook_type,clik,number,date) VALUES ( %s, %s,%s,%s,%s,%s)"values = (book2[i][0], book2[i][1], book2[i][2], book2[i][3], book2[i][4], book2[i][5])cur.execute(into, values)conn.commit() # 提交事务print("写入数据库中成功!")except BaseException:print("写入数据库中失败!")# 可视化处理函数
def guis(lists, type):# 处理大列表,取出前10的点击量小说信息.list1 = []list_navel_name = []for x in lists:click_num = x[3].split(':')list1.append(int(click_num[1]))list1.sort(reverse=True)#排序list2 = []for i in range(0, 10):list2.append(list1[i]) #获取排名前十的点击量数值# print(list2)for y in lists:equ = int(y[3].split(':')[1]) #处理字符串# print(equ)for j in range(0, len(list2)):if equ == int(list2[j]):list_navel_name.append(y) #获取到小说名x = []y = list2for num in range(0, len(list_navel_name)):x.append(list_navel_name[num][0])# 实现可视化图形;plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']plt.rcParams['axes.unicode_minus'] = Falsematplotlib.use('WebAgg')if type == "histogram": # 柱状图plt.bar(x, y, width=0.3, color='blue')elif type == "chart": # 条形图plt.barh(x, y, height=0.3, color='blue')elif type == "line": # 折线图plt.plot(x, y, linewidth=2, linestyle='-')elif type == "Area": # 面积图plt.stackplot(x, y)elif type == "scatter": # 散点图plt.scatter(x, y)elif type == "pie": # 饼图plt.pie(y, labels=x, autopct='%3.2f%%')else:print("输入错误!")plt.show()# 展示词云函数
def cloud(book2):with open('string.text', 'w', encoding="utf-8") as file:for x in book2:file.write(x[0] + x[2])with open('string.text', 'r', encoding='UTF-8') as file:text = file.read() # 读取文件内容text = re.sub('[!,:,?的!了 我是]', '', text)word1 = jieba.lcut(text) # 将文本进行分词处理word2 = " ".join(word1) # 将分好的词通过空格连接print(word2)# 创建背景图mask = np.array(Image.open('D:\\爬虫图片\\love.png')) # 获取背景图片# mask=imread('D:\\爬虫图片\\2.jpg')a = WordCloud(background_color='white', # 设置颜色font_path='C:\Windows\Fonts\simhei.ttf', # 设置字体width=1080, # 设置大小mask=mask, # 如果参数为空,则使用二维遮罩绘制词云。如果 mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取height=626,max_words=50 # 要显示的词的最大个数,默认200).generate(word2)image = ImageColorGenerator(mask) # 提取颜色a.recolor(color_func=image) # 替换默认的字体颜色a.to_file('test.jpg') # 生成词云图片# plt.imshow(a)# plt.axis("off")# plt.savefig('test1.jpg')if __name__ == '__main__':url = '*********' #需要自己定义book2 = data_list(url)cloud(book2)# guis(book2,"pie")# guis(book2, "histogram")# save_text(book2)# save_book_execl(book2)# save_mysql(book2)
这篇关于Python爬虫练习:并尝试将数据写入txt文本,execl表格,mysql数据库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





