本文主要是介绍读《Shape-Guided: Shape-Guided Dual-Memory Learning for 3D Anomaly Detection》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Chu Y M, Chieh L, Hsieh T I, et al. Shape-Guided Dual-Memory Learning for 3D Anomaly Detection[J]. 2023.(为毛paperwithcode上面曾经的榜一引用却只有1)
摘要
专家学习
无监督
第一个专家:局部几何,距离建模
第二个专家:2DRGB,局部颜色外观
引言
虽然在大多数情况下,颜色信息通常足以定位异常,但也已经表明,当充分使用3D几何信息时,有利于实现更好的性能(Horwitz&Hoshen,2022)
(关于PRO这个指标,我的理解是相比起交并比,PRO是直接计算预测比上真实,作为重叠率,然后类似auc那样计算各个阈值下的情况得到曲线再计算面积)
方法
根据相关工作中的观点,重点提取点云中的旋转不变特征,隐式表示,通过符号距离函数对找到粒度的 3D 局部结构进行建模
以及颜色外观和几何坐标的双专家聚合
3D
重点是局部几何来考察3D信息,一是因为异常只在局部,二是因为局部点云信息可扩展(?)
用PointNet (Qi et al., 2017) 和神经隐函数 (NIF) (Ma et al., 2022),用于点云应用以探索 3D 形状信息。具体来说,我们首先将一个完整的点云划分为3D块并进行局部表示学习。对于每个生成的补丁,我们对 500 个点进行采样并应用 PointNet 来获得其特征向量
(这和之前研究3d数据的体素方法有啥区别)区别于传统的3D数据体素化方法,这种做法不是将3D数据转换为固定的网格结构,而是直接在点云上操作,保持了数据的原始形式和丰富的几何细节。体素化通常涉及将连续的几何空间离散化为固定分辨率的网格,这可能会导致几何信息的损失。而PointNet和NIF允许从原始点云直接学习,可以更好地捕捉细节和局部结构,这对于异常检测特别重要,因为异常通常是通过细微的局部变化来识别的。
(类似图神经网络吗)
2D
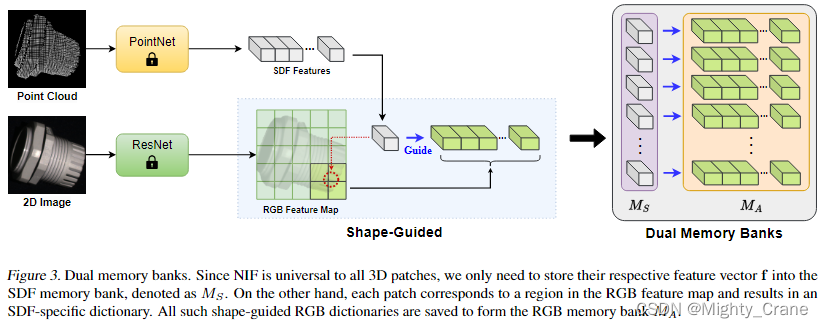
(我的理解就是拿点云中“拓扑化的体素”单元与2d图像中的像素patch块做特征对齐,然后类似一种双模态的融合)
(听说这个memory bank最近在异常检测等领域很火,但我的理解这不就是一个空间换时间的内存特征数据库嘛,随时提供正常特征作为模板来检索比对。而且还和模型一起保存下来?融入作为模型的一部分?不然推理时怎么比对嘛,那么这样的话感觉领域针对性好强,也太不够通用了吧)
实验
点云的分块甚至是预处理之间的,PointNet和NIF模型这两个冻结的玩意也是这里用patch训练的,所以有选型实验(但是这就有点那啥)
感觉有点怪,怪不得引用量不高?赶紧再看看代码
这篇关于读《Shape-Guided: Shape-Guided Dual-Memory Learning for 3D Anomaly Detection》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!