本文主要是介绍文献速递:深度学习--端到端深度学习方法用于通过语音信号检测帕金森病,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文献速递:深度学习–端到端深度学习方法用于通过语音信号检测帕金森病
Title
题目
End-to-end deep learning approach for Parkinson’s
disease detection from speech signals
端到端深度学习方法用于通过语音信号检测帕金森病
01
文献速递介绍
帕金森病是世界上增长最快的神经系统疾病之一。超过90%的帕金森病患者患有运动减缓性构音障碍,这表现为声音低沉、单调、基本频率范围缩小、辅音和元音不准确、声音含气以及不规则的停顿。之前的研究显示,语音信号可能是区分帕金森病患者和健康对照组(HCs)的有用临床证据。有趣的是,声音障碍是帕金森病早期发展的重要表现。因此,有效和智能地从语音中检测这些声音障碍可能是早期诊断的重要工具。对于开发非侵入式工具以检测和诊断帕金森病,包括基于语音的机器学习(ML)技术,人们的兴趣日益增加。传统的ML方法,如支持向量机(SVM)、K最近邻(KNN)、决策树、遗传算法、朴素贝叶斯(NB)、高斯过程分类及其组合通常基于不同测量提取手工设计的语音特征,包括梅尔频率倒谱系数(MFCC)、音高、颤音和闪烁值等声音信号。最近,一些新的特征被发现对于检测帕金森病有效,如内在模式函数倒谱系数(IMFCC)、基于非负矩阵分解的时频[21]、希尔伯特倒谱系数(HCCs)、瞬时能量偏差倒谱系数(IEDCC)以及基于经验模式分解的能量方向特征(EDF-EMD)。传统机器学习方法的性能主要受模型架构、手工设计的语音特征和特征选择方法的影响。
相比之下,深度学习因其良好的学习能力和低泛化误差,在许多模式识别任务中获得了相当大的流行度。对于通过语音检测帕金森病,有两种主要的深度学习方法:基于特征工程的方法和端到端的方法。
Abstract
摘要
超过90%的帕金森病患者患有低动力性构音障碍。本文提出了一种新颖的端到端深度学习模型,用于从语音信号中检测帕金森病。所提出的模型使用时间分布的二维卷积神经网络(2D-CNNs)提取时间序列动态特征,然后使用一维卷积神经网络(1D-CNN)捕获这些时间序列之间的依赖关系。在两个数据库上验证了所提出模型的性能。在数据库1上,所提出的模型性能优于基于专家特征的机器学习模型,并取得了令人瞩目的结果,在持续元音/a/的语音任务上准确率达到81.6%,在阅读一个简短句子(/si shi si zhi shi shi zi/)的中文语音任务上准确率为75.3%。在数据库2上,所提出的模型在包括元音、单词和句子在内的多种声音类型上进行了评估。在包括阅读简单(/loslibros/)和复杂(/viste/)西班牙语句子的语音任务上,准确率达到了高达92%。通过可视化模型生成的特征,发现学到的时间序列动态特征能够捕捉到帕金森病声音的减少的总体频率范围和减少的变异性这些重要的临床证据,这对于检测帕金森病患者是重要的。结果还表明,对于从语音中检测帕金森病,Mel频谱图的低频区域比高频区域更有影响力和重要性。
Methods
方法
The architecture of the herein proposed end-to-end deep learning model (Fig. 1) for Parkinson’s disease detection con tains two modules. The first module is composed of a seriesof time-distributed 2D-CNN (two-dimensional convolutional neural networks) blocks, which transform the input to time series dynamic features. Then, the obtained time series dynamic features are passed through the second module con taining a 1D-CNN (one-dimensional convolutional neural net work) block to learn the dependencies between them.
The input of the first module is a sequence of overlapping segments on the log Mel-spectrograms of an input speech sig nal. A sliding window is applied along the temporal axis to obtain the segments. The time-distributed 2D-CNN blocks are used to detect the local features for each segment, i.e., the time series dynamic features. Each time-distributed 2D CNN block is stacked by a 2D convolutional layer, batch nor malization layer, 2D average pooling layer, and dropout layer.
The role of the 2D convolutional layer is to capture local spa tial information of the spectrogram. The batch normalization layer increases the convergence speed and helps improve generalization. The 2D average pooling layer and dropout layer are used afterwards for dimensionality reduction and preventing overfitting, respectively.
此处提出的端到端深度学习模型的架构(图1)用于帕金森病的检测,包含两个模块。第一个模块由一系列时间分布的二维卷积神经网络(2D-CNN)块组成,这些块将输入转换为时间序列动态特征。然后,获得的时间序列动态特征通过包含一维卷积神经网络(1D-CNN)块的第二模块,以学习它们之间的依赖关系。
第一个模块的输入是输入语音信号的对数梅尔频谱图上的一系列重叠段。沿时间轴应用滑动窗口以获得这些段。时间分布的2D-CNN块用于检测每个段的局部特征,即时间序列动态特征。每个时间分布的2D-CNN块由一个2D卷积层、批量归一化层、2D平均池化层和dropout层堆叠而成。
2D卷积层的作用是捕获频谱图的局部空间信息。批量归一化层提高了收敛速度,并帮助改善泛化。2D平均池化层和dropout层随后用于降维和防止过拟合。
Conclusion
结论
Discriminating health control from Parkinson’s disease sub jects using speech signals is considered an important step toward noninvasive diagnostic decision support for PD. This paper proposed a novel end-to-end deep learning architecture for Parkinson’s disease detection from speech signals, which incorporates TSC and spectrum-based feature extraction to efficiently capture the dynamics of speech signals for Parkin son’s disease detection. The proposed model was demon strated the effectiveness on two databases of different languages (Chinese and Spanish). On Database-1, the pro posed model outperformed expert feature-based ML models using speech features extracted by NeuroSpeech and Surf board and achieved promising results, showing an accuracy of 81.6% on the speech task of sustained vowel /a/ and 75.3% on the speech task of reading a short sentence. On Database-2, the proposed model was assessed on multiple sound types, including vowels, words, and sentences. An accuracy of up to 92% was obtained for speech tasks that included reading of a simple sentence (/loslibros/) and of a complex sentence (/viste/) in Spanish, which exhibited higher detection accuracy than that previously reported, demon strating the effectiveness of the proposed model. In addition, by visualizing the features generated by the model, it was found that the learned time series dynamic features are able to capture the characteristics of the reduced overall frequency range and reduced variability in Parkinson’s disease sounds. The results also suggest that the low-frequency region is more influential and important for Parkinson’s disease detec tion than the high-frequency region, especially with the input of vowels and words.
In future works, we will investigate the robustness of the proposed model on a relatively large dataset and on more types of sound. In addition, we will apply the proposed model to the stage classification of Parkinson’s disease to explore its applicability to this multi-label classification task. Table 15 lists the abbreviations used in this paper.
使用语音信号区分健康对照组和帕金森病患者被认为是朝着PD非侵入式诊断决策支持重要的一步。本文提出了一种新颖的端到端深度学习架构,用于从语音信号中检测帕金森病,该架构结合了TSC和基于频谱的特征提取,以有效捕获帕金森病检测的语音信号动态。在两个不同语言(中文和西班牙语)的数据库上展示了所提模型的有效性。在数据库1上,所提模型在使用NeuroSpeech和Surfboard提取的语音特征上超越了基于专家特征的机器学习模型,并取得了令人鼓舞的结果,显示在持续元音/a/的语音任务上准确率达到81.6%,在读短句的语音任务上准确率为75.3%。在数据库2上,所提模型在包括元音、单词和句子在内的多种声音类型上进行了评估。对于包括读简单句子(/loslibros/)和复杂句子(/viste/)的西班牙语语音任务,获得了高达92%的准确率,显示出比以前报道的更高的检测准确率,证明了所提模型的有效性。此外,通过可视化模型生成的特征,发现学习到的时间序列动态特征能够捕捉到帕金森病声音中整体频率范围缩小和变异性减少的特征。结果还表明,低频区域对于帕金森病的检测比高频区域更具影响力和重要性,尤其是在输入元音和单词时。
在未来的工作中,我们将探究所提模型在相对较大的数据集和更多类型的声音上的鲁棒性。此外,我们将应用所提模型于帕金森病的分期分类,以探索其对这一多标签分类任务的适用性。
表15列出了本文中使用的缩写。
Figure
图
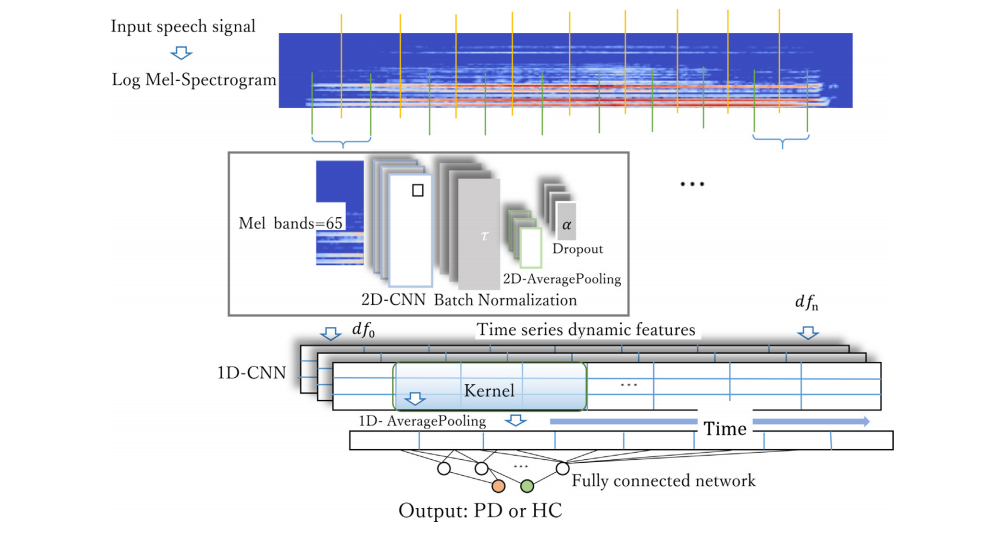
Fig. 1 – Architecture of the end-to-end deep learning model for Parkinson’s disease detection from speech signals
图1 - 用于通过语音信号检测帕金森病的端到端深度学习模型架构
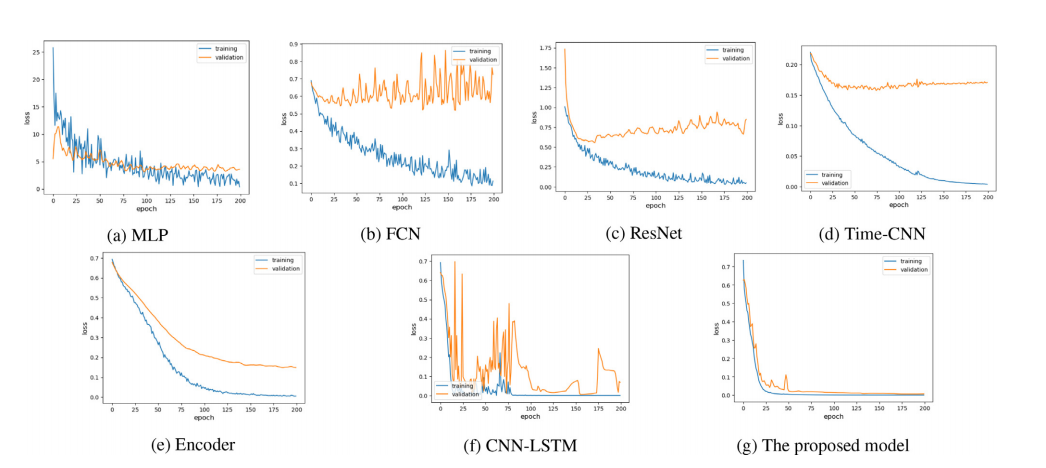
Fig. 2 – Learning curve results of end-to-end deep learning models on the speech task of sustained vowel/a/ (Database-1).
图2 - 端到端深度学习模型在持续元音/a/语音任务上的学习曲线结果(数据库1)。
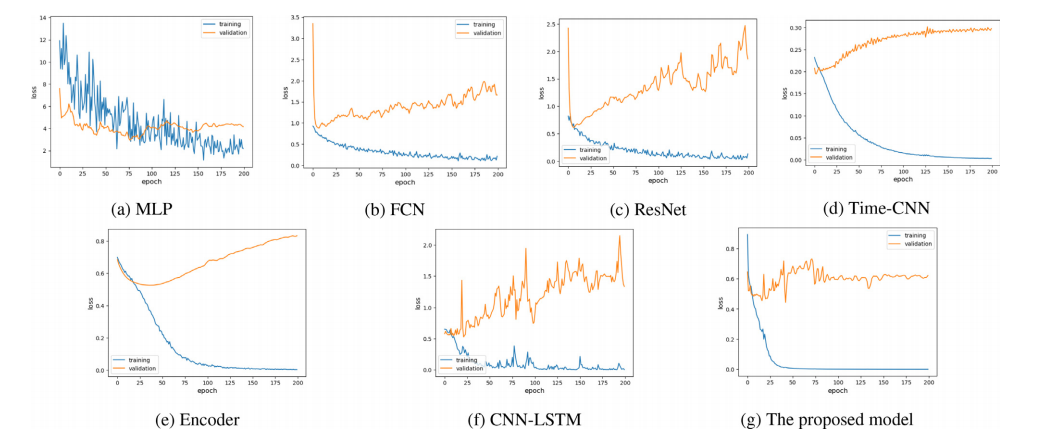
Fig. 3 – Learning curve results of end-to-end deep learning models on the speech task of reading the short sentence/si shi si zhi shi shi zi/ (Database-1).
图3 - 端到端深度学习模型在读短句/四是四十是十狮子/语音任务上的学习曲线结果(数据库1)。
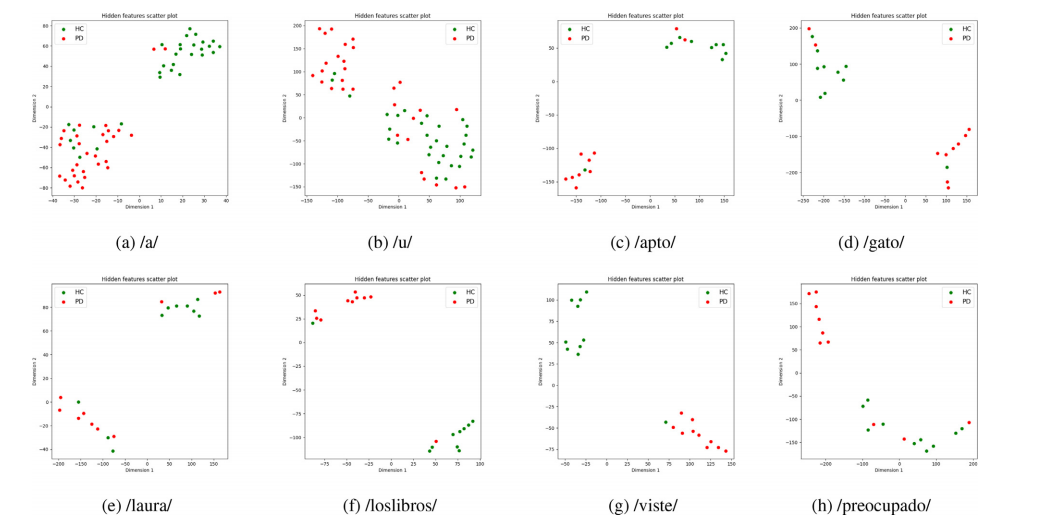
Fig. 4 – The t-SNE scatter plots of hidden features on the last layer of the proposed deep learning model after dimensionality reduction (Database-2).
图4 - 经过降维后,提出的深度学习模型最后一层隐藏特征的t-SNE散点图(数据库2)。

Fig. 5 – Critical difference diagram showing pairwise statistical difference comparison of seven deep learning models on Database-1 and Database-2.
图5 - 关键差异图,显示了在数据库1和数据库2上七个深度学习模型之间成对统计差异比较。
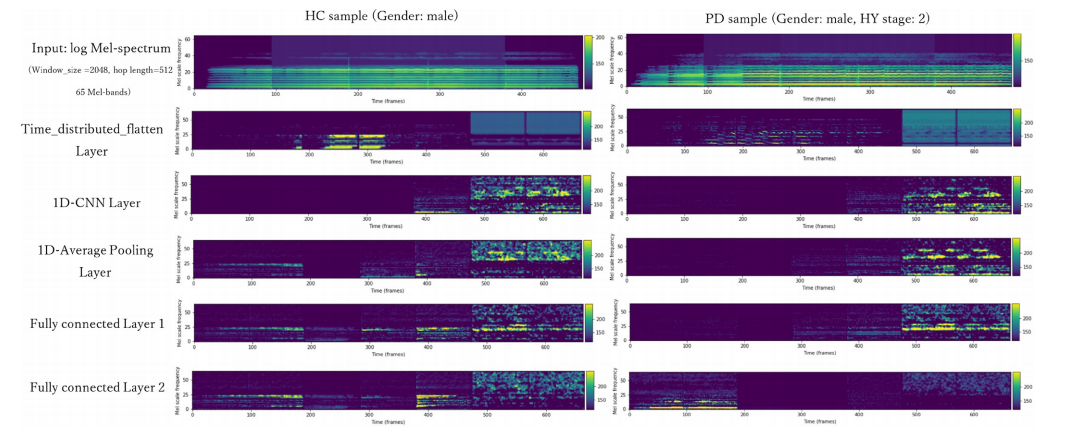
Fig. 6 – Feature visualization (guided Grad-CAM) comparison of healthy control and Parkinson’s disease samples for the speech task of sustained vowel/a/ (Database-1).
图6 - 健康对照组和帕金森病样本在持续元音/a/语音任务上的特征可视化(引导型Grad-CAM)比较(数据库1)。
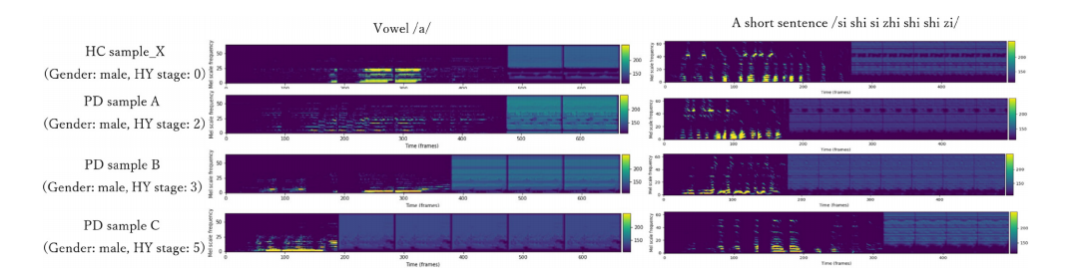
Fig. 7 – Comparison of features obtained from Time_distributed_flatten layer for male samples with different HY stages(Database-1).
图7 - 不同HY阶段的男性样本从时间分布式平展层获得的特征比较(数据库1)。
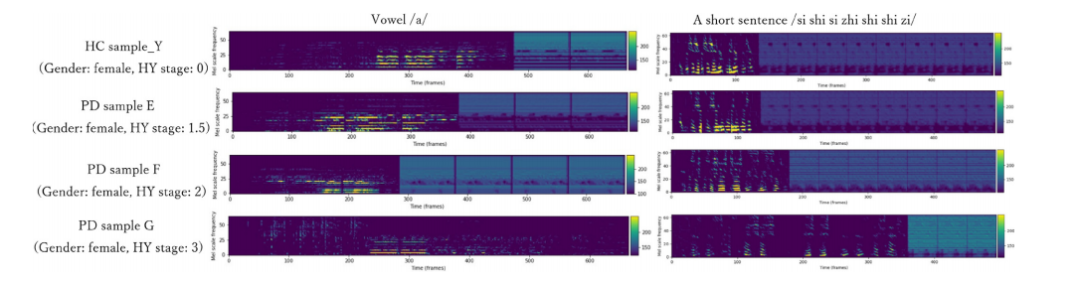
Fig. 8 – Comparison of features obtained from Time_distributed_flatten layer for female samples with different HY stages(Database-1).
图8 - 不同HY阶段的女性样本从时间分布式平展层获得的特征比较(数据库1)。

Fig. 9 – ROC curve results obtained for Database-2.
图9 - 获取的数据库2的ROC曲线结果。
Table
表
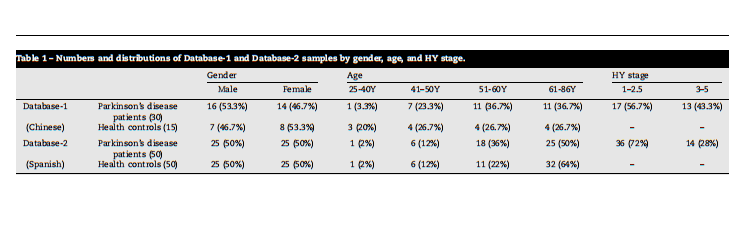
Table 1 – Numbers and distributions of Database-1 and Database-2 samples by gender, age, and HY stage.
表1 - 根据性别、年龄和HY阶段,数据库1和数据库2样本的数量和分布。

Table 2 – Speech tasks and the sample size included in this study.
表2 - 本研究包含的语音任务和样本大小。
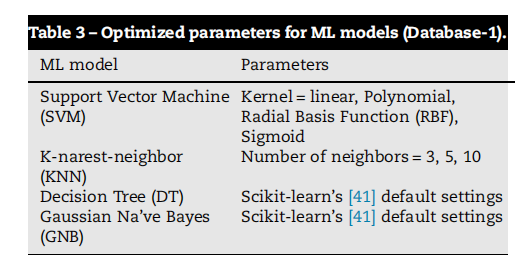
Table 3 – Optimized parameters for ML models (Database-1).
表3 - 机器学习模型的优化参数(数据库1)。
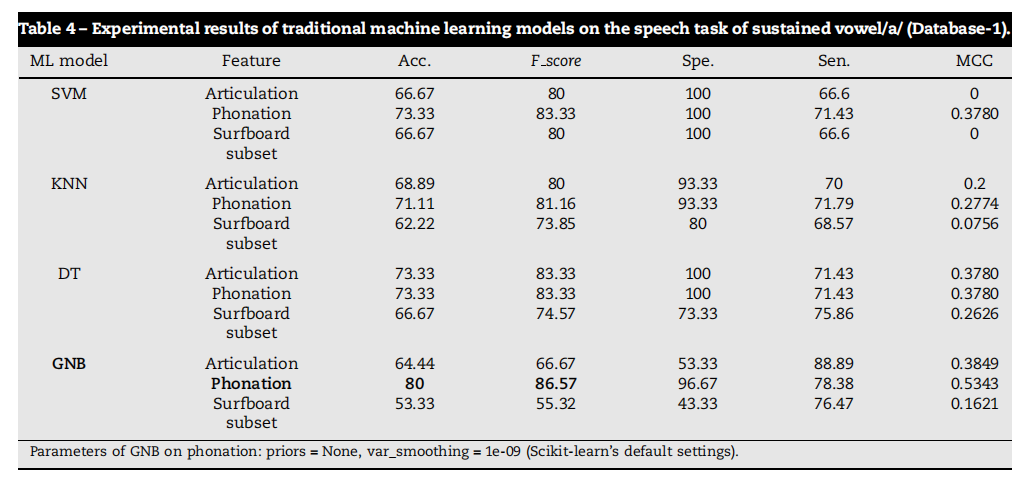
Table 4 – Experimental results of traditional machine learning models on the speech task of sustained vowel/a/ (Database-1).
表4 - 传统机器学习模型在持续元音/a/语音任务上的实验结果(数据库1)。
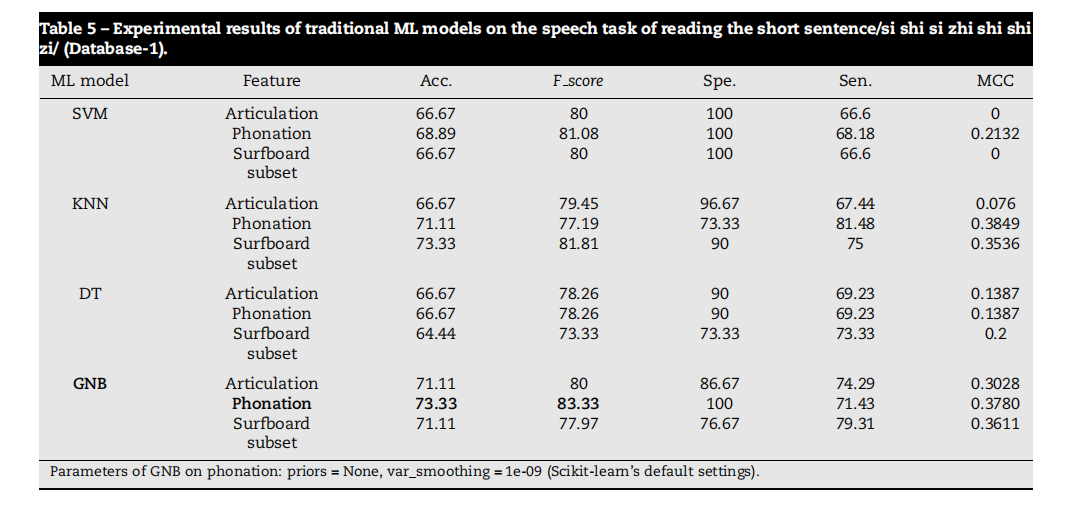
Table 5 – Experimental results of traditional ML models on the speech task of reading the short sentence/si shi si zhi shi shi zi/ (Database-1).
表5 - 传统机器学习模型在读短句/四是四十是十狮子/语音任务上的实验结果(数据库1)。
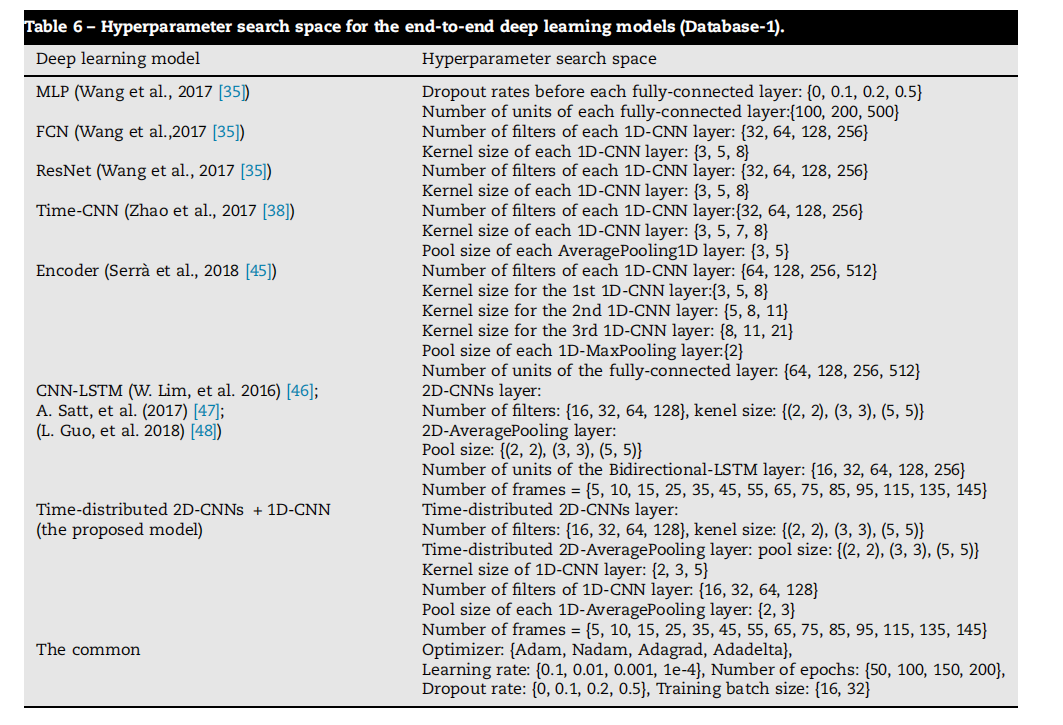
Table 6 – Hyperparameter search space for the end-to-end deep learning models (Database-1).
表6 - 端到端深度学习模型的超参数搜索空间(数据库1)。
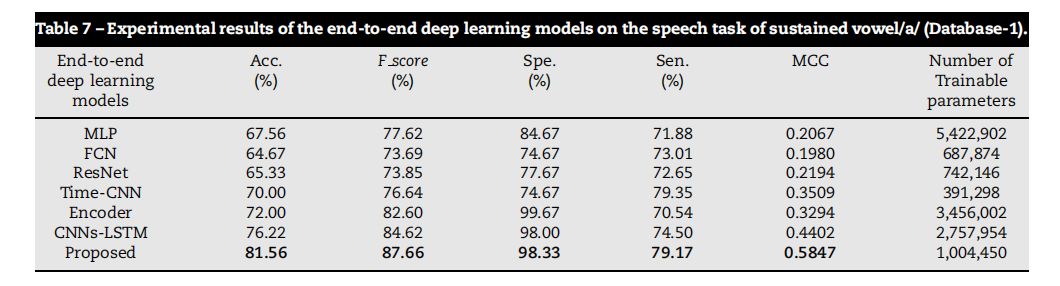
Table 7 – Experimental results of the end-to-end deep learning models on the speech task of sustained vowel/a/ (Database-1).
表7 - 端到端深度学习模型在持续元音/a/语音任务上的实验结果(数据库1)。
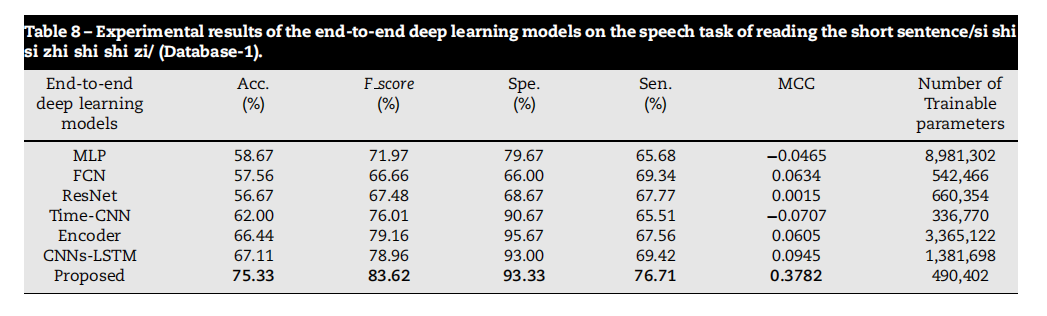
Table 8 – Experimental results of the end-to-end deep learning models on the speech task of reading the short sentence/si shi si zhi shi shi zi/ (Database-1).
表8 - 端到端深度学习模型在读短句/四是四十是十狮子/语音任务上的实验结果(数据库1)。
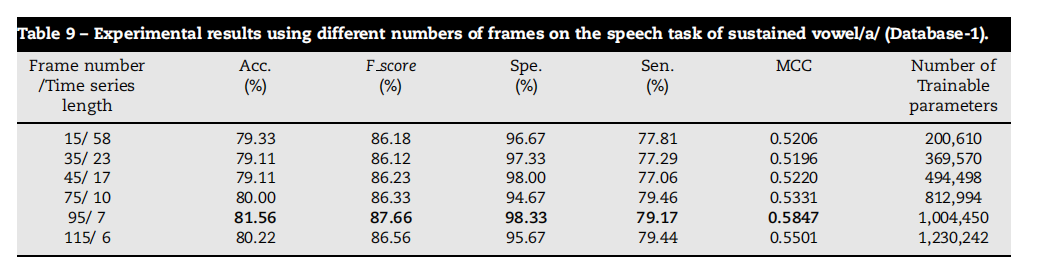
Table 9 – Experimental results using different numbers of frames on the speech task of sustained vowel/a/ (Database-1).
表9 - 在持续元音/a/语音任务上使用不同帧数的实验结果(数据库1)。
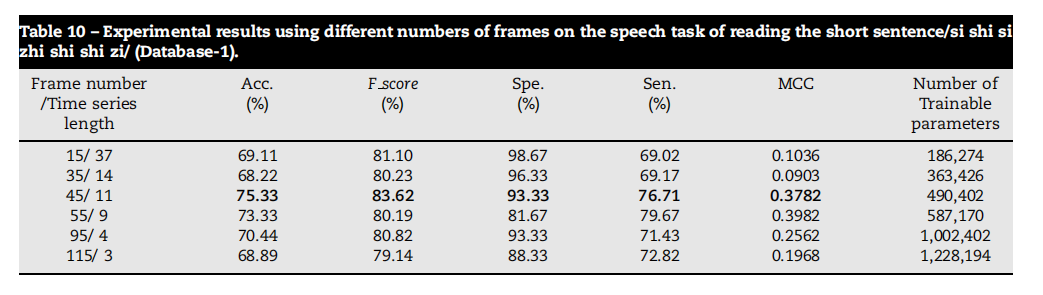
Table 10 – Experimental results using different numbers of frames on the speech task of reading the short sentence/si shi si zhi shi shi zi/ (Database-1).
表10 - 在读短句/四是四十是十狮子/语音任务上使用不同帧数的实验结果(数据库1)。

Table 11 – The optimal hyperparameters obtained from Database-1 for the experiments on Database-2.
表11 - 从数据库1获取的用于数据库2实验的最优超参数。
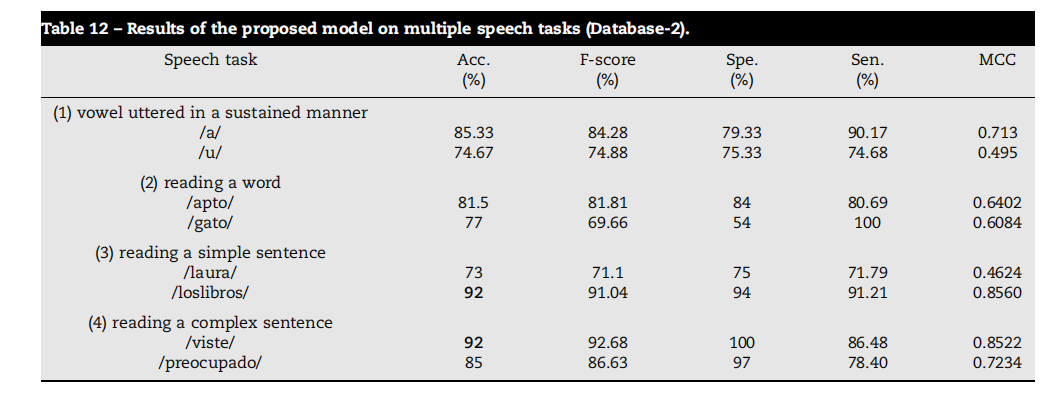
Table 12 – Results of the proposed model on multiple speech tasks (Database-2).
表12 - 提出的模型在多个语音任务上的结果(数据库2)。
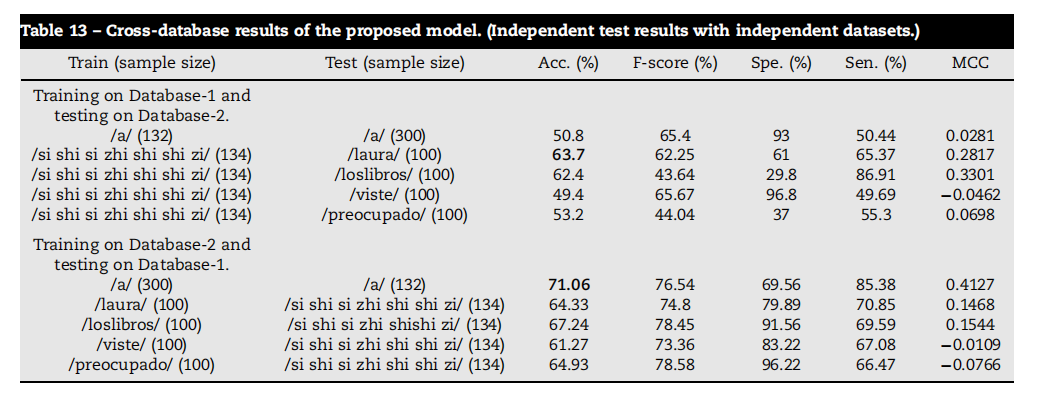
Table 13 – Cross-database results of the proposed model. (Independent test results with independent datasets.)
表13 - 提出模型的跨数据库结果。(独立数据集的独立测试结果。)
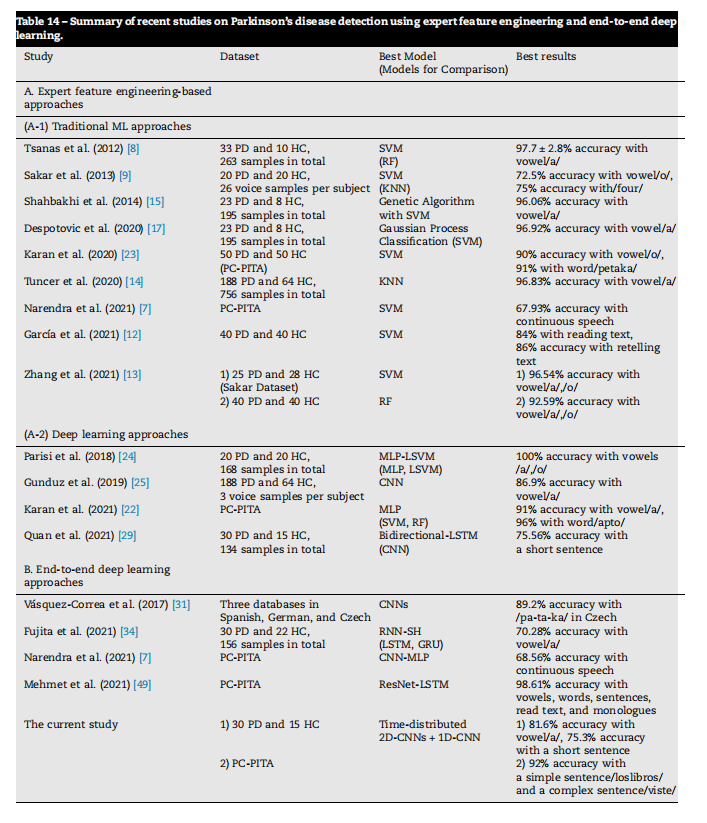
Table 14 – Summary of recent studies on Parkinson’s disease detection using expert feature engineering and end-to-end deep learning.
表14 - 使用专家特征工程和端到端深度学习进行帕金森病检测的近期研究总结。

Table 15 – The abbreviations used in this paper.
表15 - 本文中使用的缩写。
这篇关于文献速递:深度学习--端到端深度学习方法用于通过语音信号检测帕金森病的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



