本文主要是介绍数据仓库维度表与事实表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据仓库维度表与事实表
数据仓库目前主要作用还是商业智能决策,而维度建模是数仓数据分析最常用的建模方法,建模当中维度表和事实表是不可或缺的重要组成部分,维度表是记录实体属性的表,是数据分析的主要对象,事实表记录事实数据,提供分析对象的度量值。
维度表是存储分析对象属性数据的表,作为分析对象如果数据出现问题,很可能导致下游一系列分析数据出现问题,故而维度表的数据标准化和准确度要求很高,接下来才是本篇文章的主体,为了保证维度表数据准确性就有了渐变维度。
渐变维度方式主要分为:重写、添加新的记录、添加列,不同的方式应用在不同的业务背景下。
1.重写
直接在维度表上面修改对象属性信息,这种一般应用在数据校正的前提下,例如:某电商仓库维表中代理键为A1仓的仓库名称更改,原本叫广州01仓,现在改成深圳01仓,这种情况最好就是直接重写维表A1仓的名称,同时向业务方征集意见看历史数据是否需要处理,然后将需要冲刷的历史数据重刷,不能重刷的历史数据向业务方发布消息不在更新广州01仓的数据。
| 仓库code | 仓库名称 |
|---|---|
| A1 |
2.添加新的记录
添加一条新的记录信息,同时用生效日期时间段、更新原因、当前标记列来记录该信息,这种应用在对象属性信息变更,同时以前的信息有用,例如:还是某电商仓库维表代理键为A1仓的仓库分类变更,由原本的合约仓变成现在的保税仓,因为合约仓和保税仓的某些指标的计算方式的不一样,所以不能用重写的方式再去重刷历史数据,此时添加新的记录信息,用时间和当前标记来区分,可以在计算的时候分别用不同的计算方式计算而不影响数据准确信。

3.添加列
维度表新增一列,缺点是无法优雅的新增很多列,应用于对象在一个属性上有两层意思的场景,例如:还是那个电商的维度表代理键为A1仓的仓库分类,原本它只是一个合约仓,现在它不仅是合约仓还是保税仓,这样前两种处理方式明显都不合适,最好处理方式就是添加一列-备用仓库分类,这样在使用的时候可以根据实际需要自由选择不同的仓库分类。

事实表是存储分析对象的度量数据的表,根据不同的应用场景也可以划分为三种:交易表、快照表、累加式快照表。
1.交易表
一笔交易单据记录一条数据。
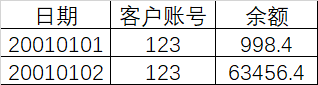
2.快照表
客户账户余额或者仓库存储货量每天都在变化,为了记录每天的数据变化将每天的数据都记录下来。
3:累加式快照表
假如交易表只记录交易事实,快照表只记录节点状态,那么累加式快照表就是将每笔单据开始到结束的每个状态以及时间节点都记录下来,采用的方法就是重写。

浅显的个人理解,欢迎补充…
这篇关于数据仓库维度表与事实表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!