本文主要是介绍处理35亿张图片+42台服务器+336块显卡,硅谷可怕的AI算力就是这么来的,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

硅谷Live / 实地探访 / 热点探秘 / 深度探讨
本文来源微信公众号“硅谷洞察”(ID:guigudiyixian)。硅谷洞察,链接硅谷资源的第一入口。本文由硅谷洞察原创,首发于腾讯科技,未经硅谷洞察或腾讯科技授权,请勿转载。
三十五亿张照片,树立人工智能新标杆
上周日,Facebook人工智能研究院(Facebook Artificial Intelligence Research)首席科学家,人工智能界的先驱 Yan Lecun(杨立昆)宣布开源了他们在图像识别以及整个计算机视觉领域的最新模型——“在Instagram的图片标签上预训练,在ImageNet上微调(finetune)的ResNext101模型”。
这一模型再次刷新了 ImageNet 数据集图像分类竞赛的准确度,在图像分类、目标检测等多个计算机视觉技术领域立下了新标杆。 诸如目标检测、图像分割等等计算机视觉基础任务都可以将其骨干网络替换为这一新模型,借助其强大的特征提取能力,有望取得更好的效果。换言之, 整个计算机视觉业界都有机会因之受益。
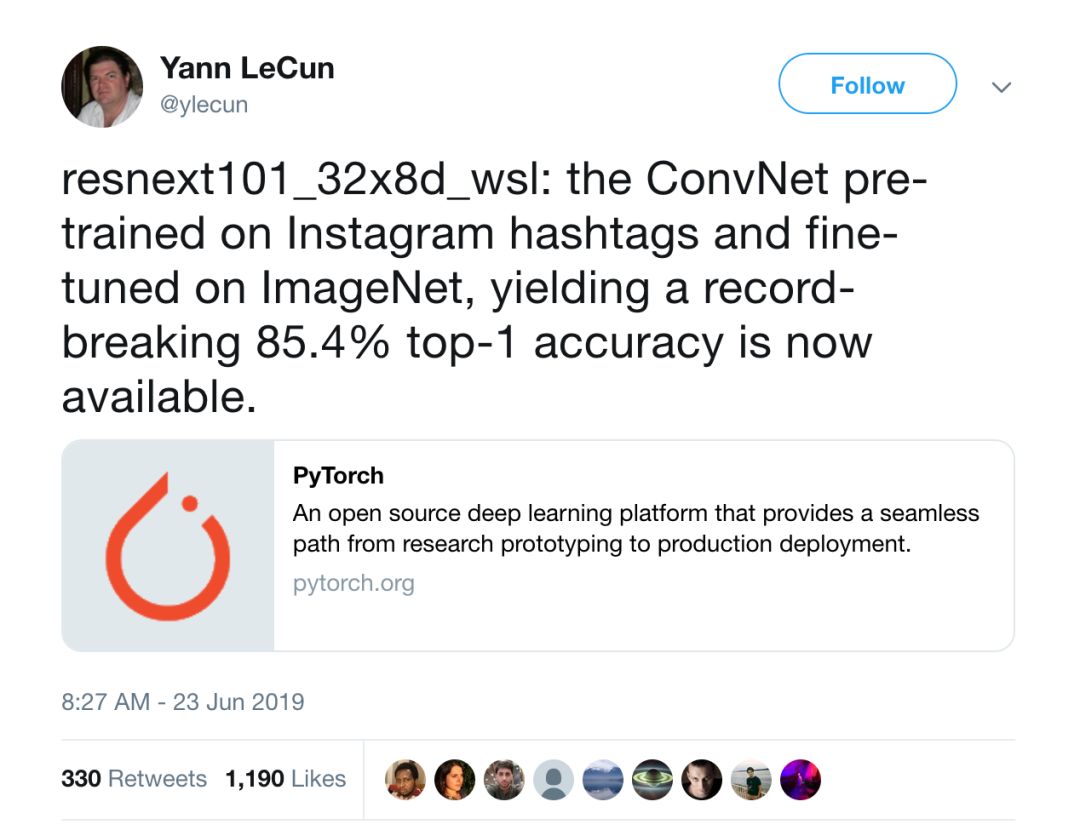
Yann Lecun Twitter
若你对这一领域有所了解,再着重关注一下上面引号里的那句描述,你可能就会不由自主地飙出一句:“有钱真 [敏感词] 好啊!”。
ImageNet,由李飞飞教授团队于2009年发布,包含了超过两万类物体,共计一千四百多万张图片,为整个人工智能领域奠下数据基础。 自那时起,诸多计算机视觉任务的新模型、新思想都是在ImageNet数据集上进行预训练,再在相应的目标任务上进行微调,以取得最好的效果。
 ImageNet数据集
ImageNet数据集
时过境迁,对 FAIR 来说,角色一转,ImageNet 居然成了迁移、微调的对象。
他们在来自 Instagram 的 三十五亿 张(注意,比 ImageNet 的一千四百万足足多了两百多倍)图片上进行了预训练,以人们为图片添加的标签(#hashtag)为类别,最终再在(相对之下)小得多的 ImageNet上进行微调,成功击败一众高手,站上顶峰。
 Instagram标签(右边蓝色#开头短语即为图片标签hashtag)
Instagram标签(右边蓝色#开头短语即为图片标签hashtag)
史无前例的海量数据之下,算力亦是重头戏。
为了处理三十五亿张图片,他们 拿出了42台服务器,用上336块显卡,又训练了足足22天。
颇有股“有钱使得鬼推磨”的气派。
数据和算力,两强结合之下, 人工智能几乎成了大力出奇迹的巨头游戏 。
其实从一开始,游戏的规则就是如此 。
近些年的人工智能革命,其实大抵建立于人工神经网络模型的大放异彩。
而究其根本,在上世纪70年代,人工神经网络模型的理论架构已经基本成熟,却在之后的几十年里一直没能得到认可、应用,直到近来才得以重见天日。
前文提到的 Yann Lecun,更是因为一直坚持神经网络而被学界排斥,郁郁不得志,直到如今才重获认可,获颁计算机领域“诺贝尔奖”之称的图灵奖。
这其后的根源,就在于算力的限制。上世纪的计算机算力和你手中的新款手机比起都可谓云泥之别,遑论吸纳海量数据,对神经网络模型进行训练。
时至2012年,算力的突飞猛进,加上 ImageNet 等前所未有的“巨型数据集”的出现,神经网络才真正再次登台,绘下人工智能新时代的夺目图景。
不过,又过了 7 年,直到现在,ImageNet 才终于被更大的数据集所取代,在这背后,弱监督学习功不可没。
强监督、弱监督、自监督
"弱"监督学习,自是相对于"强"监督学习而言。

ImageNet数据集里的一张图片,标注为波斯猫
相比于 ImageNet 数据集为每一张图片人工加注的物品类别标签,Instagram 图片的标签就要来的含混的多。为了吸粉,用户更会刻意地为自己的图片加上大量无论相关不相关的标签,以博取更多的浏览量。
在这种情况下,人工智能模型还能学到图片与含混描述之间的对应关系吗?
在 三十五亿张图片 的暴力训练之下,效果显著,也因而有了我们开头提到的新模型开源。
从此,人工标注不再是计算机视觉领域的最大瓶颈,弱监督标签搭配巨头的强大算力,就能得到比悉心雕凿,训练于 ImageNet 之上的“小数据”模型好得多的性能表现。
算力为王,计算机视觉领域如此,在 AI 的另一重头戏——自然语言处理领域,亦是如此。
不同于 Facebook 视觉新模型的弱监督训练,在自然语言处理领域,更进一步的自监督训练已成主流。
Google 去年开源的 BERT 模型,在训练时会将输入句子的随机单词盖住,然后让模型根据上下文的内容预测被盖住的单词是什么,通过这一方式,模型可以学习到自然语言隐含的句法,亦能对词义句义有所掌握。
更重要的是,这一方法不需要任何人工标注,可谓“人有多大胆,地有多大产”,数字时代无数的自然语言资源 —— 电子书、网站、论坛帖子等等等等都能成为训练数据的来源。句子以自身信息作为监督,对模型进行训练,故称自监督学习。
在数据无限的前提之下,算力便显得愈发重要。
在 BERT 原论文里,Google 用了 16 块自主研发的人工智能芯片——张量处理器(Tensor Processing Unit,TPU)训练了四天四夜,才最终收获了突破性的结果。
若你想以显卡为标准作以比较,英伟达足足用了64张自家的顶级显卡,在多方优化之下训练了三天有余,才成功复现这一成果。
 谷歌TPU芯片
谷歌TPU芯片
今年卡耐基梅隆大学(CMU)和 Google 合作研发的 XLNet 模型,则在BERT的基础上更进一步,在足足 512 块 TPU 上训练了两天半时间。
以 Google Cloud(谷歌云服务)的计价标准计算, 训练一次 XLNet 模型总共需要二十四万五千美元 (合人民币一百六十余万)。若再考虑上模型研发过程中的不断试错,调参验证等等过程,XLNet 模型的开销简直天文数字。
巨额开支之下,中小团队自然无力竞争,自然语言处理的基础模型研发,也因而几近成了巨头独霸的竞技场 。
算力垄断之下,中小团队如何应对?
“ 站在巨人的肩膀上 ” 便是第一准则。
相互竞争之中,算力巨头们多会将自己训练好的模型对外开源,让没有训练资源的团队也能得以在模型上进行微调,得以应用。虽然这一过程亦对算力有所要求,但却已比从头训练现实的多。
目前,不少国内互联网公司已将BERT开源模型应用于自然语言处理系统之中,大大提升了系统的自然语言理解能力。视觉领域公司则可以从FAIR的新模型入手,对自身的图像识别系统的骨干模型进行更新升级,以期取得更好的成效。
“ 差异化 ”为核心。
中小团队在算力上对大公司望尘莫及,亦因而无力在如多类别图片分类等基础问题上与算力巨头逐鹿竞技,却可以基于自身的独特优势,在细分特定问题上夯实基础。
在去年年底拿到四亿美元C轮融资的Zymergen,便立足于自身在生物领域的深厚技术研发,将AI运用于药物、材料研发中,避开了与巨头在图像、自然语言处理等领域的白热化竞争,成就了自己独特的技术护城河。

Zymergen公司
https://www.vox.com/2015/6/16/11563594/synthetic-biology-startup-zymergen-emerges-from-stealth-with-44
除此之外,随着5G和物联网时代的到来,算力受限的物联网设备成为新热点。如何研发设计算力要求小、能效比低的模型亦能成为中小团队的破局之处。
“ 更高更快更强 ”还是根本。
面临算力垄断的加剧,提升自身算力仍是根本。即使选择了独到的差异化方向,又借助巨头的开源模型进行微调,算力的要求仍不容小觑。在大多数情况下,算力提升带来的效率提升还是要比算力本身的开支来的重要。条件容许之下,提升团队的算力可以说是最简单直接却又最见成效的投入之一了。
对AI芯片公司来说,这更是机遇所在。
若是通过不断的芯片研发,提高人工智能算法的训练、运行效率,以更低的成本提供更多的算力,AI芯片创业公司便能在这个算力为王的时代脱颖而出,成为英伟达显卡、谷歌TPU之外的重要选择。
拿到微软、三星投资,估值过亿美元的独角兽公司GraphCore便推出了自家研发的智能处理芯片(Intelligence Processing Unit, IPU),在从训练到推理的整个流程之上,试图与GPU和TPU一决高下。根据测试,IPU在能耗、速度、时延等方面都显出了自己的独特优势,有望成为AI算力战场的又一有力竞争对手。

GraphCore IPU芯片
https://www.theverge.com/circuitbreaker/2018/11/26/18112462/graphcore-new-ai-chips-server-processors-design-colorful
大名鼎鼎的寒武纪也在上个月推出了“思元”系列芯片。他们选择了一条更为差异化的道路,聚焦于整数低精度训练,在特定的应用环境下取得更好的速度与效率,避免了对竞争对手的直缨其锋,有望在英伟达的传统优势战场——云端计算中心抢下一席之地。
“差异化”核心的重要性又一次凸显。
在模型一再革新,数据指数增长,算力愈发重要的今日,中小团队几乎不可能在热门领域与巨头正面竞争。中小团队应聚焦自身优势,寻找差异化的切入点,才能在人工智能的浪潮中脱颖而出,立于不败之地。
巨头企业也应负起自身的社群责任,为技术、模型的开源化作出贡献,让更多的开发者、团队、科研人员受益于业界最新技术的发展。这也将有助于巨头公司自身的形象确立,吸引更多人才加入,为自身发展添砖加瓦。
不过,无论中小团队还是巨头企业,算力的提升都是重点议题。 现如今,为图形计算而生的显卡仍是我们人工智能系统的主要硬件。
通过系统 架构的改革,特型化硬件的设计、开发,我们的AI芯片仍大有潜力可挖。 充沛的算力如同驱动两次工业革命的煤炭和电力,也将驱动我们的人工智能革命不辍前行。
推荐阅读

区块链报告 | 脑机接口报告
硅谷人工智能 | 斯坦福校长
卫哲 | 姚劲波 | 胡海泉
垂直种植 | 无人车
王者荣耀 | 返老还童

这篇关于处理35亿张图片+42台服务器+336块显卡,硅谷可怕的AI算力就是这么来的的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





