本文主要是介绍【视觉算法系列3】在自定义数据集上训练 YOLO NAS(下篇),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

提示:免费获取本文涉及的完整代码与数据集,请添加微信peaeci122
YOLO-NAS是目前最新的YOLO目标检测模型,它在准确性方面击败了所有其他 YOLO 模型。与之前的 YOLO 模型相比,预训练的 YOLO-NAS 模型能够以更高的准确度检测更多目标。
如何在自定义数据集上训练 YOLO NAS?这将是我这两篇文章的目标。
目录:
1、用于训练 YOLO NAS 的物体检测数据集
2、在自定义数据集上训练 YOLO NAS
3、微调 YOLO NAS 模型
4、使用经过训练的 YOLO NAS 模型对测试图像进行推理
5、YOLO NAS 训练模型视频推理结果
6、结论
上篇讲到“微调 YOLO NAS 模型”中的“定义YOLO NAS训练的变换和增强”,本篇我们继续
YOLO NAS 训练参数、模型培训、分析微调结果。
YOLO NAS 训练参数
在我们开始微调过程之前,训练参数是最重要的组成部分。在这里,我们定义了要训练的epoch、要监控的验证指标和学习率等。
train_params = {'silent_mode': False,"average_best_models":True,"warmup_mode": "linear_epoch_step","warmup_initial_lr": 1e-6,"lr_warmup_epochs": 3,"initial_lr": 5e-4,"lr_mode": "cosine","cosine_final_lr_ratio": 0.1,"optimizer": "Adam","optimizer_params": {"weight_decay": 0.0001},"zero_weight_decay_on_bias_and_bn": True,"ema": True,"ema_params": {"decay": 0.9, "decay_type": "threshold"},"max_epochs": EPOCHS,"mixed_precision": True,"loss": PPYoloELoss(use_static_assigner=False,num_classes=len(dataset_params['classes']),reg_max=16),"valid_metrics_list": [DetectionMetrics_050(score_thres=0.1,top_k_predictions=300,num_cls=len(dataset_params['classes']),normalize_targets=True,post_prediction_callback=PPYoloEPostPredictionCallback(score_threshold=0.01,nms_top_k=1000,max_predictions=300,nms_threshold=0.7)),DetectionMetrics_050_095(score_thres=0.1,top_k_predictions=300,num_cls=len(dataset_params['classes']),normalize_targets=True,post_prediction_callback=PPYoloEPostPredictionCallback(score_threshold=0.01,nms_top_k=1000,max_predictions=300,nms_threshold=0.7))],"metric_to_watch": 'mAP@0.50:0.95'
}
在训练时,输出将同时显示 50% Iou 和 5%-95% IoU 时的 mAP。不过,我们只监控主要指标(mAP@0.50:0.95 IoU),因此最好的模型将根据它被保存。、
YOLO NAS 模型培训
由于我们要训练三个不同的模型,因此需要将过程自动化一些,可以定义一个包含三个模型名称的列表,并根据该列表设置检查点目录。这也会加载适当的模型,因为列表中的模型名称与super-gradients API中的模型名称匹配。
models_to_train = ['yolo_nas_s','yolo_nas_m','yolo_nas_l'
]CHECKPOINT_DIR = 'checkpoints'for model_to_train in models_to_train:trainer = Trainer(experiment_name=model_to_train, ckpt_root_dir=CHECKPOINT_DIR)model = models.get(model_to_train, num_classes=len(dataset_params['classes']), pretrained_weights="coco")trainer.train(model=model, training_params=train_params, train_loader=train_data, valid_loader=val_data)
三个训练实验将依次运行,所有的模型检查点将保存在各自的目录中。
分析 YOLO NAS 微调结果
在训练过程中,输出单元 / 终端显示训练过程的全面视图。
SUMMARY OF EPOCH 0
├── Training
│ ├── Ppyoloeloss/loss = 3.8575
│ ├── Ppyoloeloss/loss_cls = 2.3712
│ ├── Ppyoloeloss/loss_dfl = 1.1773
│ └── Ppyoloeloss/loss_iou = 0.3591
└── Validation├── F1@0.50 = 0.0├── F1@0.50:0.95 = 0.0├── Map@0.50 = 0.0012├── Map@0.50:0.95 = 0.0005├── Ppyoloeloss/loss = 3.7911├── Ppyoloeloss/loss_cls = 2.5251├── Ppyoloeloss/loss_dfl = 0.9791├── Ppyoloeloss/loss_iou = 0.3106├── Precision@0.50 = 0.0├── Precision@0.50:0.95 = 0.0├── Recall@0.50 = 0.0└── Recall@0.50:0.95 = 0.0
.
.
.
SUMMARY OF EPOCH 50
├── Training
│ ├── Ppyoloeloss/loss = 1.4382
│ │ ├── Best until now = 1.433 (↗ 0.0053)
│ │ └── Epoch N-1 = 1.433 (↗ 0.0053)
│ ├── Ppyoloeloss/loss_cls = 0.6696
│ │ ├── Best until now = 0.6651 (↗ 0.0046)
│ │ └── Epoch N-1 = 0.6651 (↗ 0.0046)
│ ├── Ppyoloeloss/loss_dfl = 0.6859
│ │ ├── Best until now = 0.6846 (↗ 0.0013)
│ │ └── Epoch N-1 = 0.686 (↘ -0.0)
│ └── Ppyoloeloss/loss_iou = 0.1703
│ ├── Best until now = 0.17 (↗ 0.0003)
│ └── Epoch N-1 = 0.17 (↗ 0.0003)
└── Validation├── F1@0.50 = 0.292│ ├── Best until now = 0.3025 (↘ -0.0104)│ └── Epoch N-1 = 0.2774 (↗ 0.0146)├── F1@0.50:0.95 = 0.1859│ ├── Best until now = 0.1928 (↘ -0.007)│ └── Epoch N-1 = 0.1761 (↗ 0.0097)├── Map@0.50 = 0.7631│ ├── Best until now = 0.7745 (↘ -0.0114)│ └── Epoch N-1 = 0.7159 (↗ 0.0472)├── Map@0.50:0.95 = 0.4411│ ├── Best until now = 0.4443 (↘ -0.0032)│ └── Epoch N-1 = 0.4146 (↗ 0.0265)├── Ppyoloeloss/loss = 1.5389│ ├── Best until now = 1.5404 (↘ -0.0015)│ └── Epoch N-1 = 1.5526 (↘ -0.0137)├── Ppyoloeloss/loss_cls = 0.6893│ ├── Best until now = 0.687 (↗ 0.0024)│ └── Epoch N-1 = 0.6972 (↘ -0.0079)├── Ppyoloeloss/loss_dfl = 0.7148│ ├── Best until now = 0.7136 (↗ 0.0012)│ └── Epoch N-1 = 0.7234 (↘ -0.0086)├── Ppyoloeloss/loss_iou = 0.1969│ ├── Best until now = 0.1953 (↗ 0.0016)│ └── Epoch N-1 = 0.1975 (↘ -0.0006)├── Precision@0.50 = 0.1828│ ├── Best until now = 0.1926 (↘ -0.0097)│ └── Epoch N-1 = 0.1718 (↗ 0.011)├── Precision@0.50:0.95 = 0.1166│ ├── Best until now = 0.1229 (↘ -0.0063)│ └── Epoch N-1 = 0.1092 (↗ 0.0074)├── Recall@0.50 = 0.8159│ ├── Best until now = 0.8939 (↘ -0.0781)│ └── Epoch N-1 = 0.8307 (↘ -0.0149)└── Recall@0.50:0.95 = 0.522├── Best until now = 0.5454 (↘ -0.0234)└── Epoch N-1 = 0.5236 (↘ -0.0016)===========================================================
我们可以查看 Tensorboard 日志并检查 mAP 图,以便比较三个训练全部过程。Tensorboard 日志位于检查点目录下的相应训练文件夹中。
下图显示了三个训练实验的主要AP对比:
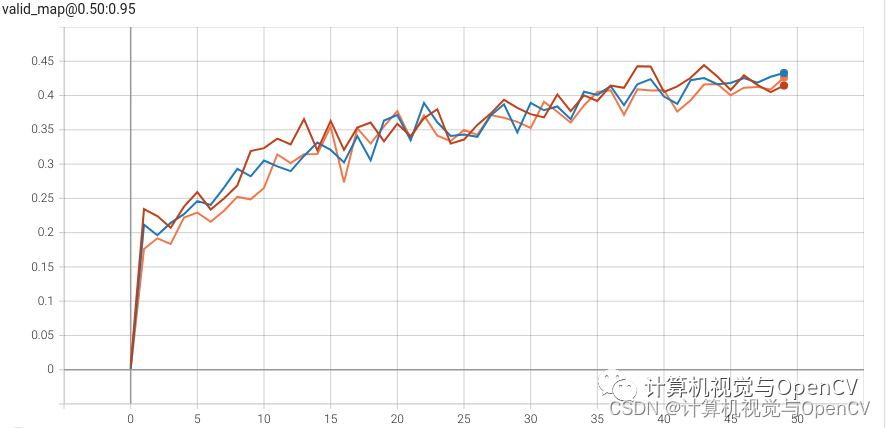
在上图中:
**红线:**YOLO NAS 大型模型训练
**蓝线:**YOLO NAS 中型模型训练
**橙线:**YOLO NAS 小型模型培训
YOLO NAS 大型模型在第 43 个epoch达到了最高 mAP 44.4%,这里注意一点, YOLO NAS 大型模型相对较快地达到了较高的 mAP,说明与 YOLO NAS 中型和小型模型相比,YOLO NAS 大型模型具有探测困难物体的能力。
super-gradients API为每个实验保存三个不同的检查点,一个最佳模型,一个最新模型,一个平均权重。
由于 YOLO NAS 大型模型在自定义数据集训练中表现最佳,我们将进一步使用该模型进行推理实验。
更长时间地训练 YOLO NAS 大模型
从上述实验中可以看出,YOLO NAS Large 模型的性能最好,为了获得更好的结果,我们可以对该模型进行 100 次历时训练。YOLO_NAS_Large_Fine_Tuning.ipynb 可以实现这一目标。
下图是在自定义数据集上对模型进行 100 次历时训练后的 mAP 图。
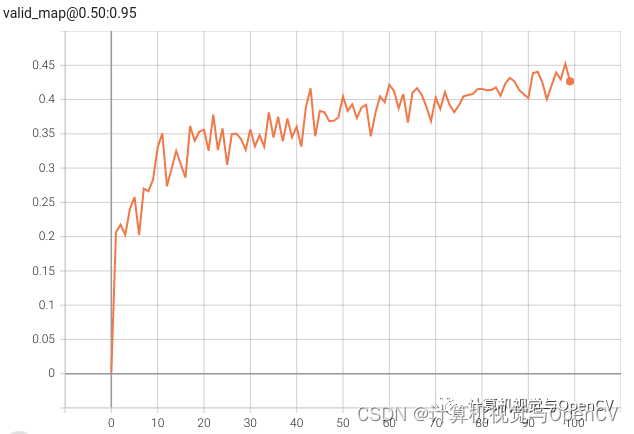
在自定义数据集上对YOLO NAS Large模型进行微调,mAP达到45%以上。
四. 使用训练过的 YOLO NAS 模型对测试图像进行推理
数据集中包含一个测试分割,保留它用于推理目的,可以执行 inference.ipynb 笔记本中的代码单元来运行推理实验,完成以下几件事:
1、首先,它从检查点目录加载经过最佳训练的YOLO NAS权重。
2、然后对测试图像进行推理,执行此操作时,代码会将推理结果保存在 inference_results/images 目录中,并保留原始图像名称。
3、获得推理结果后,笔记本会将地面实况注释重叠到预测图像上,从而显示一组图像。
最后一步将告诉我们训练模型遗漏了哪些对象,以及模型是否做出了错误预测。
通过可视化一些推理预测来开始分析。

从初步分析来看,这个模型几乎可以预测所有的物体,甚至是看起来非常小的人,但是,要在这里找出任何错误就比较困难了。
在预测的基础上可视化地面实况注释是一个更好的方法。

在上图中,真实注释以红色显示,类名称位于底部。
可以看到,在大多数情况下,模型缺少对Person类的检测。除此之外,它还检测到实际上不是汽车的汽车实例,并且还检测到其中一张图像中的自行车作为人。
总的来说,该模型表现良好,只是无法检测到非常难以识别的物体。
五. YOLO NAS 训练模型视频推理结果
我们还对无人机热成像视频进行了推理实验。
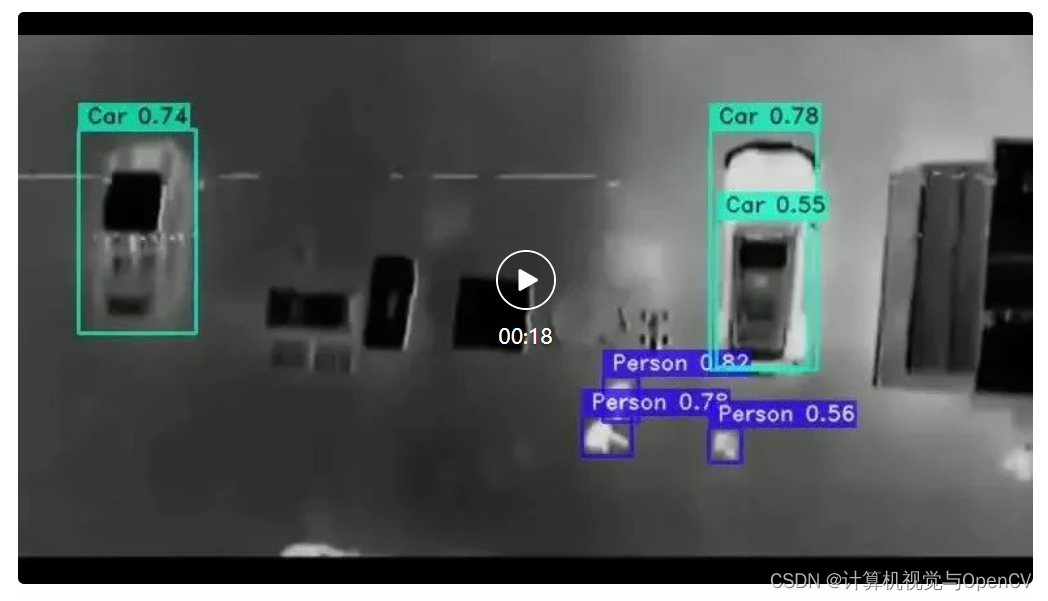
(完整视频效果请前往微信公众号“计算机视觉与OpenCV”查看)
从结果可以看出,尽管相机移动摇晃,该模型仍可以在几乎所有帧中检测到人和汽车。
视频推理在配备 GTX 1060 GPU 的笔记本电脑上运行,模型的平均运行速度为17 FPS,使用的是 YOLO NAS Large 机型,整体速度还不错。
六. 结论
这篇文章,主要探讨如何在自定义数据集上训练 YOLO NAS 模型。在实验中,我选择了一个极具挑战性的热成像数据集,包含 5 个类别。这个数据集中的物体很小,人类很难检测到,但是 YOLO NAS 经过微调后做得非常好,这显示了 YOLO NAS 模型在实时检测小物体的实际用例中的潜力。
从实验中可以推断,新的 YOLO NAS 模型为实时检测开辟了新天地,这些应用包括监控、交通监控和医疗成像等。



这篇关于【视觉算法系列3】在自定义数据集上训练 YOLO NAS(下篇)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









